问题标签 [syntaxnet]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
corpus - 使用 Syntaxnet 注释语料库
我正在尝试使用 Syntaxnet 注释语料库。我在 /models/syntaxnet/syntaxnet/models/parsey_mcparseface/context.pbtxt 文件的末尾添加了以下行:
当我运行命令时:
我正进入(状态:
根据## here ## 给出的答案,我更改了我的 demo.sh 文件,现在我收到一些错误消息:
什么是可能的解决方案?
parsing - 理解注解 - Syntaxnet
我在一组 1400 条推文上成功构建并运行了 Syntaxnet。我很难理解解析文件中每个参数的含义。例如,我有一句话:
解析的文件内容为:
每一列到底是什么意思?为什么除了 POS 标签之外还有空格和数字?
tensorflow - 是否可以导出语法网络模型(Parsey McParseface)以与 TensorFlow Serving 一起服务?
我的 demo.sh 工作正常,我查看了 parser_eval.py 并在某种程度上理解了它。但是,我看不到如何使用 TensorFlow Serving 来服务这个模型。我可以从顶部看到两个问题:
1) 这些图没有导出模型,在每次调用时使用图构建器(例如,structured_graph_builder.py)、上下文协议缓冲区和一大堆其他我不完全理解的东西来构建图(它似乎也注册了额外的 syntaxnet.ops )。那么......是否有可能,我将如何将这些模型导出到 Serving 和所需的“捆绑”形式中SessionBundleFactory?如果不是,则似乎需要在 C++ 中重新实现图形构建逻辑/步骤,因为 Serving 仅在 C++ 上下文中运行。
2) demo.sh 实际上是两个模型,实际上是与 UNIX 管道一起通过管道传输的,因此任何 Servable 都必须(可能)构建两个会话并将数据从一个会话编组到另一个。这是一个正确的方法吗?或者是否可以构建一个“大”图,其中包含“修补”在一起的两个模型并将其导出?
python - 如何使用 SyntaxNet 输出来操作执行命令,例如在 Linux 系统上将文件保存在文件夹中
下载并训练SyntaxNet 后,我正在尝试编写一个程序,该程序可以打开新的/现有文件,例如 AutoCAD 文件,并通过分析文本将文件保存在特定目录中: 打开 LibreOffice 文件 X。考虑 SyntaxNet 的输出为:
首先,我考虑将解析后的文本更改为 XML 格式,然后使用语义分析(如SPARQL)解析 XML 文件以找到 ROOT=save、dobj=X 和 nummode=Y,然后编写一个可以执行相同操作的 python 程序。在文中
我不知道如果我将解析的文本更改为 XML,然后使用使用查询的语义分析,以便
ROOT与其对应的函数或保存的脚本 匹配dobj,在一个目录中提及nummode我有一些想法用
subprocess包将 python 连接到终端,但我没有找到任何可以帮助我从终端保存例如 AUTOCAD 文件或任何其他文件的东西,或者我是否需要.sh使用蟒蛇的帮助?
我对文本的句法和语义分析进行了大量研究,例如Christian Chiarcos, 2011 , Hunter and Cohen, 2006和Verspoor et al., 2015,现在还研究了Microsoft Cortana , Sirius , google但没有一个通过他们如何将解析的文本更改为执行命令的详细信息,这使我得出结论,这项工作太容易被谈论,但由于我不是计算机科学专业的,所以我无法弄清楚我能做些什么。
python - 使用 SyntexNet Parsey McParseface 创建训练语料库
我目前正在尝试学习 Tensorflow,并且已经到了需要创建一些语料库数据集的地步。我没有钱在 LDC 购买带注释的 Gigaword 英语语料库,所以我正在考虑创建自己的爬虫。我从网上得到了一些文章,但现在想以类似于 LDC Gigaword 示例的方式格式化它们:https ://catalog.ldc.upenn.edu/desc/addenda/LDC2012T21.jpg
{kind=link}
我正在尝试使用 Parsey Mcparseface 模型对我的输入进行 POS 标记并帮助我输出多个 xml 文件。我目前已经接近了我想要的输出,方法是使用 python 修改 conll2tree.py 文件和 demo.sh 文件,以允许我从单个文件中读取我的输入。使用的命令行显示在这篇文章的底部。
我想弄清楚的是如何让模型处理目录中的所有文件。我当前的爬虫是用 JavaScript 编写的,并输出单独的 .json 文件,其中包含带有标题、正文、图像等的 json 对象。我使用句子边界检测来用逗号分隔每个句子,但似乎我对 parsey 的输入需要作为每个句子在不同行上的输入。我将在我的 python 脚本中修改它,但我仍然不知道如何配置下面的参数,以便我可以让它遍历每个文件,读入内容,处理并继续下一个文件。有没有办法为输入参数设置通配符?或者我是否需要在我的 python 脚本中通过命令行单独发送每个文件?我只是假设 parsey 模型或者 SyntexNet 是否可以批量处理它们,
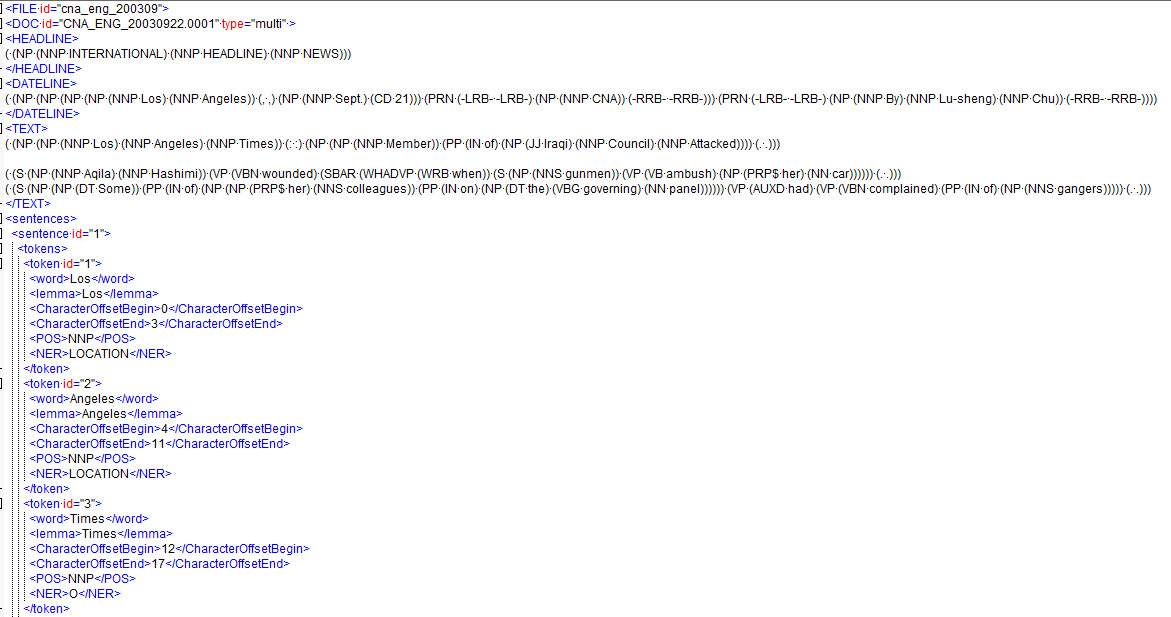
我遇到的另一个问题是,是否有办法让 Parsey Mcparseface 输出如上图“标题”所示的格式,如下所示:
(.(NP.(NNP.INTERNATIONAL).(NNP.HEADLINE).(NNP.NEWS)))
如果不是,这种格式叫什么,所以我可以更多地研究如何通过自己的代码来做这件事?让我失望的部分是 NP 的前缀数字(假设名词短语)。
我已经设法将 POS 标签提取成类似于通过句子标记显示的图像中的格式,但我假设随着我对 Tensorflow 的深入了解,拥有它们显示的格式会很好标题和文本字段标签也是如此,因为它显示了单词之间的更多关系。
我还在 content.pbtxt 文件中添加了以下条目:
python - 解析 python asciitree 输出并打印“标记括号表示法”
Google SyntaxNet 提供类似 .. 的输出
我想使用 python 来读取和解析这个输出(字符串数据)。并使用“标记括号表示法”打印出来,例如 ->
你能帮助我吗?
tensorflow - 如何指定 bazel 使用的 CPU 内核数?
我正在用 bazel 构建语法网络(tensorflow fork)。它的工作非常缓慢并且一直挂断。
上次我遇到这个问题(使用 caffe)时,有人告诉我通过添加-j4. 在 bazel 中,此命令不起作用。像这样的 bazel 有什么自定义命令吗?
CPU 规格:3.8GHz 时钟,四核
CPU 型号:AMD 4800(或类似的东西)。
linux - 创建符号链接失败
我正在尝试在我的 CentOS 6.7 机器上升级 glibcxx。我按照这里给出的步骤做了。
现在,当我这样做时:
我列出了 GLIBCXX_3.4 到 GLIBCXX_3.4.22。
为了在我的 Syantaxnet 构建中使用这个文件,我创建了一个符号链接:
但我收到一个错误:
编辑1:
我认为错误是因为文件名相同,并将 /opt/google/chrome/lib/libstdc++.so.6 重命名为 libstdc++.so.6_new。该命令仍然失败。
有人可以帮我解决这个问题吗?另外,这是错误的解决方案:
tensorflow - 如何结合来自 tensorflow tensorflow-serving 和 syntaxnet 的 bazel 工件?
我已经使用 bazel 构建了 syntaxnet 和 tensorflow-serving。两者都嵌入了自己的(部分?)张量流本身的副本。我已经有一个问题,我想在一个脚本中“导入”一些 tensorflow-serving 部分,该脚本“存在”在我无法弄清楚的语法树中(不做一些非常丑陋的事情)。
现在我想要“tensorboard”,但这显然不是作为syntaxnet 或tensorflow-serving 内的嵌入式tensorflow 的一部分构建的。
所以现在我确定“我做错了”。我应该如何组合由各种单独的 bazel 工作区构建的工件?
特别是,我如何构建 tensorflow(使用 tensorboard)和 syntaxnet 和 tensorflow-serving 并让它们“安装”以供使用,以便我可以开始在一个完全独立的目录/存储库中编写自己的脚本?
“./bazel-bin/blah”真的是 bazel 的结局吗?没有“make install”等价物吗?