我目前正在尝试学习 Tensorflow,并且已经到了需要创建一些语料库数据集的地步。我没有钱在 LDC 购买带注释的 Gigaword 英语语料库,所以我正在考虑创建自己的爬虫。我从网上得到了一些文章,但现在想以类似于 LDC Gigaword 示例的方式格式化它们:https ://catalog.ldc.upenn.edu/desc/addenda/LDC2012T21.jpg
{kind=link}
我正在尝试使用 Parsey Mcparseface 模型对我的输入进行 POS 标记并帮助我输出多个 xml 文件。我目前已经接近了我想要的输出,方法是使用 python 修改 conll2tree.py 文件和 demo.sh 文件,以允许我从单个文件中读取我的输入。使用的命令行显示在这篇文章的底部。
我想弄清楚的是如何让模型处理目录中的所有文件。我当前的爬虫是用 JavaScript 编写的,并输出单独的 .json 文件,其中包含带有标题、正文、图像等的 json 对象。我使用句子边界检测来用逗号分隔每个句子,但似乎我对 parsey 的输入需要作为每个句子在不同行上的输入。我将在我的 python 脚本中修改它,但我仍然不知道如何配置下面的参数,以便我可以让它遍历每个文件,读入内容,处理并继续下一个文件。有没有办法为输入参数设置通配符?或者我是否需要在我的 python 脚本中通过命令行单独发送每个文件?我只是假设 parsey 模型或者 SyntexNet 是否可以批量处理它们,
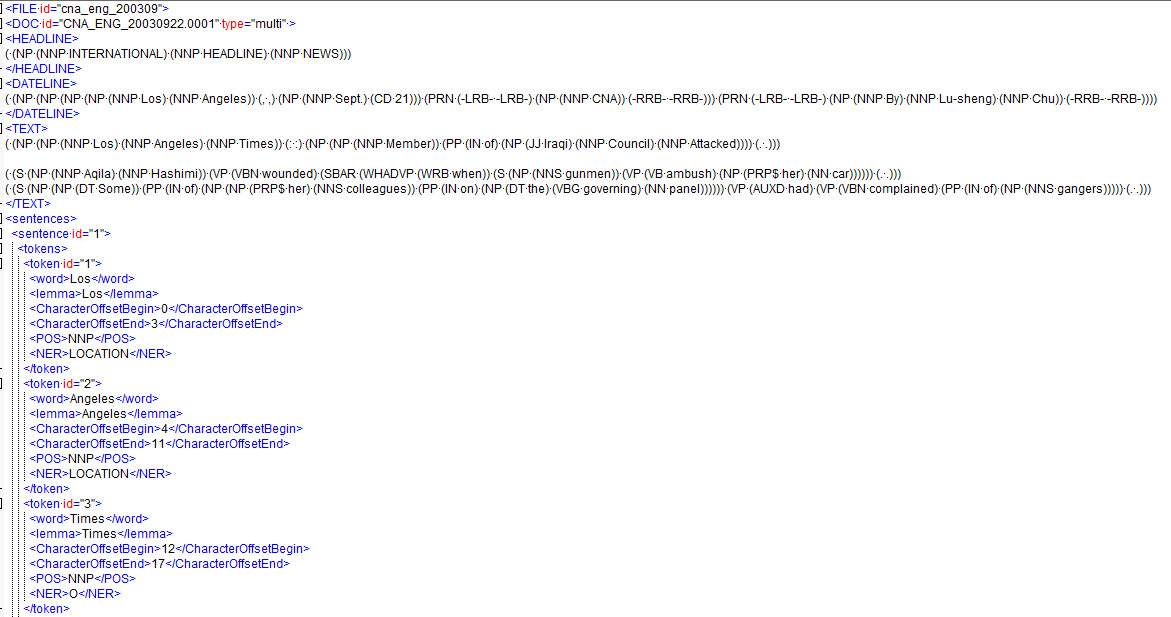
我遇到的另一个问题是,是否有办法让 Parsey Mcparseface 输出如上图“标题”所示的格式,如下所示:
(.(NP.(NNP.INTERNATIONAL).(NNP.HEADLINE).(NNP.NEWS)))
如果不是,这种格式叫什么,所以我可以更多地研究如何通过自己的代码来做这件事?让我失望的部分是 NP 的前缀数字(假设名词短语)。
我已经设法将 POS 标签提取成类似于通过句子标记显示的图像中的格式,但我假设随着我对 Tensorflow 的深入了解,拥有它们显示的格式会很好标题和文本字段标签也是如此,因为它显示了单词之间的更多关系。
PARSER_EVAL=bazel-bin/syntaxnet/parser_eval
MODEL_DIR=syntaxnet/models/parsey_mcparseface
[[ "$1" == "--conll" ]] && INPUT_FORMAT=stdin-conll || INPUT_FORMAT=stdin
#--input=testin \
#--input=$INPUT_FORMAT \
$PARSER_EVAL \
--input=testin \
--output=stdout-conll \
--hidden_layer_sizes=64 \
--arg_prefix=brain_tagger \
--graph_builder=structured \
--task_context=$MODEL_DIR/context.pbtxt \
--model_path=$MODEL_DIR/tagger-params \
--slim_model \
--batch_size=1024 \
--alsologtostderr \
| \
$PARSER_EVAL \
--input=stdin-conll \
--output=testout \
--hidden_layer_sizes=512,512 \
--arg_prefix=brain_parser \
--graph_builder=structured \
--task_context=$MODEL_DIR/context.pbtxt \
--model_path=$MODEL_DIR/parser-params \
--slim_model \
--batch_size=1024 \
--alsologtostderr \
| \
bazel-bin/syntaxnet/danspos \
--task_context=$MODEL_DIR/context.pbtxt \
--alsologtostderr
我还在 content.pbtxt 文件中添加了以下条目:
input {
name: 'testin'
record_format: 'english-text'
Part {
file_pattern: './testinp.txt'
}
}
input {
name: 'testout'
record_format: 'conll-sentence'
Part {
file_pattern: './testoutput.txt'
}
}