问题标签 [percentile]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
mysql - 在 MySQL 中计算百分位排名
我在 MySQL 中有一个非常大的测量数据表,我需要为这些值中的每一个计算百分位等级。Oracle 似乎有一个名为 percent_rank 的函数,但我找不到与 MySQL 类似的任何东西。当然,我可以在 Python 中对它进行暴力破解,无论如何我都会使用它来填充表格,但我怀疑这会非常低效,因为一个样本可能有 200.000 个观察值。
algorithm - 实时数据捕获的百分比
我正在寻找一种确定实时数据捕获百分位数的算法。
例如,考虑一个服务器应用程序的开发。
服务器的响应时间可能如下:17 ms 33 ms 52 ms 60 ms 55 ms 等。
报告第 90 个百分位响应时间、第 80 个百分位响应时间等很有用。
天真的算法是将每个响应时间插入到一个列表中。当请求统计时,对列表进行排序并在适当的位置获取值。
内存使用量与请求数量呈线性关系。
在有限的内存使用情况下,是否有一种算法可以产生“近似”百分位数统计信息?例如,假设我想以一种处理数百万个请求的方式解决这个问题,但只想使用一千字节的内存进行百分位跟踪(放弃对旧请求的跟踪不是一个选项,因为百分位应该是适用于所有请求)。
还要求没有分布的先验知识。例如,我不想提前指定任何桶范围。
python - 如何使用 python/numpy 计算百分位数?
有没有一种方便的方法来计算序列或一维 numpy 数组的百分位数?
我正在寻找类似于 Excel 的百分位函数的东西。
我查看了 NumPy 的统计参考,但找不到这个。我能找到的只是中位数(第 50 个百分位数),但没有更具体的东西。
matlab - 如何在 MATLAB 中计算 99% 的覆盖率?
我在 MATLAB 中有一个矩阵,我需要找到每列的 99% 值。换句话说,99% 的人口具有比它更大的值。MATLAB中有这个函数吗?
excel - 在 Excel 中使用“桶”数据而不是数据列表本身计算百分位数
我在 Excel 中有一堆数据,我需要从中获取某些百分比信息。问题是,我没有让数据集由每个值组成,而是有关于数据数量或“桶”数据的信息。
例如,假设我的实际数据集是这样的:1,1,2,2,2,2,3,3,4,4,4
我拥有的数据集是这样的:
有没有一种简单的方法可以计算百分位信息(以及中位数),而不必将汇总数据分解为完整的数据集?(一旦我这样做了,我就知道我可以使用 Percentile(A1:A5, p) 函数)
这很重要,因为我的数据集非常大。如果我将数据分解出来,我将有数十万行,并且我必须为几百个数据集做这件事。
帮助!
mysql - 从 MySQL 中选择第 n 个百分位数
我有一个简单的数据表,我想从查询中选择大约 40% 的行。
我现在可以通过首先查询找到行数然后运行另一个查询来排序并选择第 n 行来做到这一点:
可能会返回类似 93, 93*0.4 = 37
我可以将这两个查询组合成一个查询吗?
algorithm - 重复计算百分位数的快速算法?
在算法中,每当我添加一个值时,我都必须计算数据集的第 75 个百分位数。现在我正在这样做:
- 获取价值
x - 在后面插入
x一个已经排序的数组 - 向下交换
x直到数组排序 - 读取位置的元素
array[array.size * 3/4]
第 3 点是 O(n),其余的是 O(1),但这仍然很慢,尤其是当数组变大时。有没有办法优化这个?
更新
谢谢尼基塔!因为我使用的是 C++,所以这是最容易实现的解决方案。这是代码:
c# - 计算百分位数以去除异常值的快速算法
我有一个程序需要重复计算数据集的近似百分位数(顺序统计),以便在进一步处理之前删除异常值。我目前正在通过对值数组进行排序并选择适当的元素来做到这一点;这是可行的,但它在配置文件上是一个明显的亮点,尽管它只是该程序的一个相当小的部分。
更多信息:
- 该数据集包含多达 100000 个浮点数,并假定为“合理”分布 - 在特定值附近不太可能出现重复或密度的巨大峰值;如果由于某种奇怪的原因分布是奇怪的,那么近似值不太准确是可以的,因为数据可能无论如何都搞砸了,进一步的处理也很可疑。但是,数据不一定是均匀分布或正态分布的;它不太可能退化。
- 一个近似的解决方案会很好,但我确实需要了解近似如何引入错误以确保它是有效的。
- 由于目标是消除异常值,我一直在计算相同数据的两个百分位数:例如,一个为 95%,一个为 5%。
- 该应用程序在 C# 中,在 C++ 中进行了一些繁重的工作;伪代码或任何一个预先存在的库都可以。
- 一种完全不同的去除异常值的方法也可以,只要它是合理的。
- 更新:看来我正在寻找一个近似的选择算法。
尽管这一切都是在一个循环中完成的,但数据每次都(略有)不同,因此像对这个问题所做的那样重用数据结构并不容易。
已实施的解决方案
使用 Gronim 建议的维基百科选择算法将这部分运行时间减少了大约 20 倍。
由于我找不到 C# 实现,这就是我想出的。即使对于小输入,它也比 Array.Sort 更快;在 1000 个元素时,它的速度提高了 25 倍。
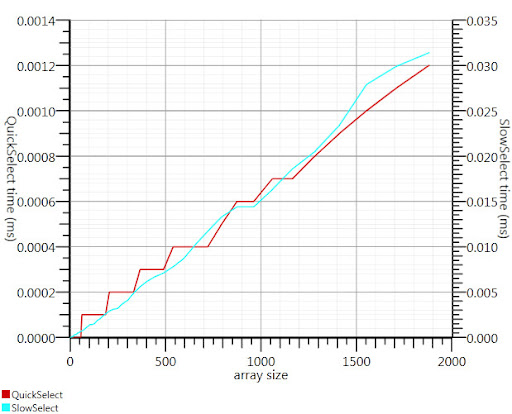
谢谢,Gronim,为我指明了正确的方向!