问题标签 [bernoulli-probability]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
python - 样本分布模拟未产生正态分布
我试图使用 Python 模拟“样本比例的抽样分布”。我尝试使用伯努利变量,如示例here
关键是,在大量的口香糖中,我们有真正比例为0.6的黄色球。如果我们抽取样本(一些大小,比如 10 个),取其平均值并绘图,我们应该得到一个正态分布。
我试图在 python 中做,但我总是得到均匀分布(或在中间平坦)。我无法理解我错过了什么。
程序:
依赖函数:
bi_to_nor_demo
SDSP
输出:

更新: 我什至尝试了如下统一分布,但得到了类似的输出。不收敛到正常:(。(使用下面的函数代替 create_bernoulli_population)
python - 抽样分布正态近似不拟合
我试图使用 Python 模拟“样本比例的抽样分布”。我尝试使用伯努利变量,如示例here
关键是,在大量的口香糖中,我们有真正比例为0.6的黄色球。如果我们抽取样本(一些大小,比如 10 个),取其平均值并绘图,我们应该得到一个正态分布。
我设法获得了正常的采样分布,但是,具有相同 mu 和 sigma 的实际正常连续曲线根本不适合,而是放大到几个因子。我不确定是什么原因造成的,理想情况下它应该非常适合。下面是我的代码和输出。我尝试改变幅度和 sigma(除以 sqrt(samplesize))但没有任何帮助。请帮忙。
代码:
输出:
红色曲线是失配正态逼近曲线。mu 和 sigma 来自统计离散分布(小蓝条),并馈送到计算正态曲线的公式。但正常曲线看起来以某种方式放大了。
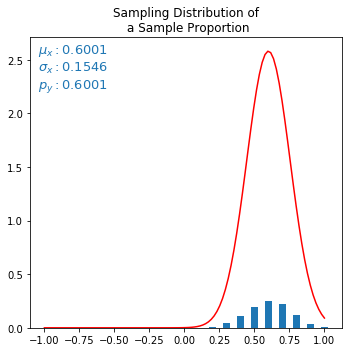
更新:
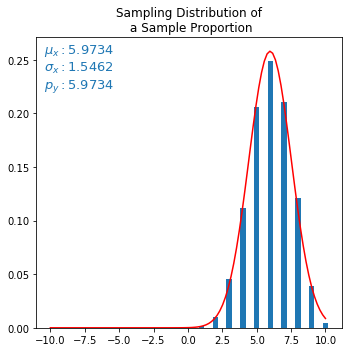
避免除以取平均值,解决了图形问题,但 mu 被缩放。所以问题还没有完全解决。:(
删除上述除法后的输出(但需要吗?):
r - 如何有效地将 dpoibin 分解为 R 中的和数?
Poisson-Binomial 分布涉及具有不同成功概率的独立伯努利试验序列中成功次数的概率。这是二项分布的推广。
使用命令dpoibin,在poibin包中,可以获得质量概率函数。例如,使用以下命令:
在向量中包含成功概率的 100 次独立伯努利试验序列中,可以获得 30 次成功的概率Probs_Success。要计算这个概率,必须将所有可能的长度为 100 的序列的概率相加,其中有 30 次成功和 70 次失败。
问题:如何有效地获得在 R 中生成上述概率的所有和?非常感谢你的帮助。
对于那些对引发此问题的问题感兴趣的人,请单击以下链接:
https://math.stackexchange.com/questions/2924831/bivariate-poisson-binomial-distribution
machine-learning - 如何计算伯努利朴素贝叶斯的联合对数似然
对于使用BernoulliNB的分类问题,如何计算联合对数似然。联合似然计算如下公式,其中 y(d) 是实际输出数组(不是预测值),x(d) 是特征数据集。

python - 如何使用伯努利NB?
我正在尝试使用 BernoulliNB。使用相同的数据进行训练和测试,我得到了训练数据以外的预测和 1 以外的概率。请问这是为什么?
结果
我试图在这里描述我正在尝试做的事情:
https://stats.stackexchange.com/questions/367829/how-probable-is-a-set
r - 修复伯努利模拟的函数
我想创建一个具有三个参数的函数:样本大小、样本数量、伯努利试验中成功的真实 p。
该函数将输出以下结果:p 的平均估计值(即每个样本的 p 估计值的平均值)、真实标准差的平均估计值(即每个样本的 sd 估计值的平均值),最后是分数95% CI 包含真实 p 的样本的数量。
我想出了以下代码:
但是,即使在修改了引起我注意的错误之后,此代码也不起作用。
我不断收到此错误:
draw_sample 中的错误(s = 30,r = 1000,p = 0.05):(
列表)对象不能被强制输入“双”
因此,我很想寻求您的帮助以找到问题并构建这样的功能!谢谢!
python - TypeError:在列表上应用自制伯努利拟合时无法使用灵活类型执行减少
我正在尝试使用自己的 fit 函数实现我自己的 Bernoulli 类,以适应包含单词的训练和测试列表(垃圾邮件检测)
这是我的伯努利课程:
这是我的实现:
预期结果:
能够适应我的班级我的火车和测试列表但是我收到以下错误:
在以下行:
我不知道为什么它会失败,也许是因为我有列表而不是 np?甚至不知道如何解决它。
有人可以帮助我或向我解释如何实现拟合吗?
python - 如何在python中正确建模条件伯努利分布
假设我有一个长度为 5 的上下文向量 x,我在 0 和 1 之间随机采样。这我可以在 python 中编码为
首先,我想建模一个依赖于上下文向量的奖励函数。假设奖励是0或1。在模拟中对此进行建模的最佳方法是什么?
接下来,假设我有 100 个不同的用户,对于每个用户,奖励函数随上下文变化的方式都不同。所以我想如果我将奖励函数建模为伯努利分布,我可以为不同的用户给出不同的平均值。但是我想针对不同的上下文对其进行建模。我不确定如何建模。为一组 100 个用户在不同上下文中建模奖励的最佳方法是什么?
pandas - 在 Dataframe 中查找 BernoulliNB 概率
我有一些训练数据(TRAIN)和一些测试数据(TEST)。每个数据帧的每一行都包含一个观察到的类 (X) 和一些二进制 (Y) 列。BernoulliNB 根据训练数据预测测试数据中 X 给定 Y 的概率。我正在尝试查找测试数据(Pr)中每一行的观察类的概率。
编辑:我使用 Antoine Zambelli 的建议来修复代码:
这似乎有效,给了我结果(df_S):

这正确地为前 2 行给出了“NaN”,因为训练数据不包含有关 X=5 或 X=0 类的信息。
r - 如何在 R 中计算二项式实验的 PDF
我知道您可以使用代码创建二项式实验
但是你怎么能计算这个实验的PDF。我知道 Dbinom 会给你准确的 PFD,但有没有办法计算实验的经验 PDF?