问题标签 [plyr]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
r - 使用 R 中的 plyr 包重命名输出列
Hadley 让我开始使用plyr包,我发现自己一直在使用它来做“分组”之类的事情。但我发现自己必须始终重命名结果列,因为它们默认为 V1、V2 等。
这是一个例子:
有没有办法让 ddply 为我命名结果列,以便我可以省略最后一行?
r - 对于每个组,汇总数据框中所有变量的平均值(ddply?拆分?)
一周前,我会手动完成此操作:按组将数据帧子集到新数据帧。对于每个数据帧计算每个变量的平均值,然后 rbind。很笨重...
现在我已经了解了splitand plyr,我想一定有更简单的方法可以使用这些工具。请不要证明我错了。
我正在玩弄两者,ddply但我无法制作我想要的东西 - 即每个组的一张这样的桌子
也许d_ply有些odfweave输出会起作用。非常感谢您的意见。
ps 我注意到 data.frame 将 rnorm 转换为我的 data.frame 中的因子?我怎样才能避免这种情况 - I(rnorm(100) 不起作用,所以我必须像上面那样转换为数字
r - 从绝对数到两级数据中的比例(R!SAC?plyr?)
我将数据嵌套在级别中:
现在我想要一些简单的东西——我觉得我上个月才能够做到这一点。但是我的脑海中缺少了一些东西:我想要百分比(忽略 NA),L1 中每个变量的总和为 100
我可以得到我需要的总数
但我想应该可以制作一个给我想要的功能?我尝试了使用 cast 和 plyr 的各种方法……但圣诞节已经给我脆弱的大脑带来了许多啤酒。
任何帮助将不胜感激 - 任何人都不会投反对票。
谢谢
这是我的数据:
r - 使用 plyr 对 df 进行多重变换
我有一个 df,我想用 plyr 对其进行多次转换:
...
可以在一个功能中完成吗?非常感谢。
r - 我可以在 ddply() 中进行保证金计算吗?
该cast()函数非常适合计算聚合值的边距:
cast(df, IDx1+IDx2~IDy1, margins=c('IDx1','IDx2','grand_row'),c(min, mean, max))
问题是我需要使用第二个向量和自定义函数来衡量我的平均值。
当然,ddply()让我将自定义聚合函数应用于我的分组记录:
......这太棒了。
但真正能拯救这一天的是能够同时做这两件事,无论是通过调用双向量函数cast()还是以某种方式伪造margins=()变量ddply().
这可能吗?
r - 对 R 中数据帧的每一行进行 plyr 操作
我喜欢 plyr 语法。每当我必须使用 *apply() 命令之一时,我最终都会踢狗并进行 3 天的折腾。所以为了我的狗和我的肝脏,对数据帧的每一行进行 ddply 操作的简洁语法是什么?
这是一个适用于简单案例的示例:
效果很好,给了我想要的东西。但是如果事情变得更复杂,这会导致 plyr 变得时髦(而不像 Bootsy Collins),因为 plyr 正在咀嚼从所有这些浮点值中制作“级别”
在我的盒子上,它会咀嚼几分钟,然后返回:
我认为我完全在滥用 plyr,我并不是说这是 plyr 中的错误,而是我的虐待行为(尽管有肝脏和狗)。
所以简而言之,是否有使用 ddply 对每一行进行操作的语法快捷方式来代替apply(X, 1, ...)?
我一直在使用的解决方法是创建一个“键”,为每一行提供一个唯一值,然后我可以重新加入它。
但我一直在想“必须有更好的方法”
谢谢!
r - 如何使用 plyr 对行进行编号?
基本上我想要一个基于我的同类群组的自动递增 id 列 - 在这种情况下是 .(kmer, cvCut)
我想要添加一个基于 kmer/cvCut 组具有新行名的列
r - 如何更好地从 ggplot2 创建具有多个变量的堆叠条形图?
我经常需要制作堆叠的条形图来比较变量,而且因为我在 R 中完成所有统计数据,所以我更喜欢在 R 中使用 ggplot2 来完成我的所有图形。我想学习如何做两件事:
首先,我希望能够为每个变量添加适当的百分比刻度线,而不是按计数添加刻度线。计数会令人困惑,这就是我完全取出轴标签的原因。
其次,必须有一种更简单的方法来重组我的数据以实现这一点。这似乎是我应该能够在 ggplot2 中使用 plyR 本地做的事情,但是 plyR 的文档不是很清楚(我已经阅读了 ggplot2 书和在线 plyR 文档。
我最好的图表如下所示,创建它的代码如下:
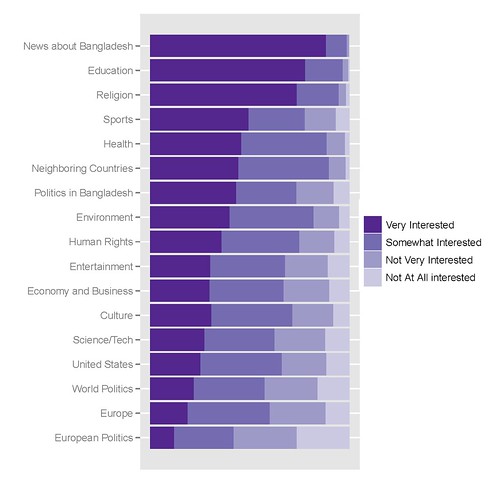
我用来获取它的 R 代码如下:
我非常感谢任何提示、技巧或提示。
r - 从 data.frame 命令的列表中指定列名
我有一个列表cols,其中包含列名:
cols <- c('Column1','Column2','Column3')
我想重现此命令,但调用列表:
data.frame(Column1=rnorm(10))
这是我尝试时会发生的情况:
> data.frame(cols[1]=rnorm(10))
Error: unexpected '=' in "data.frame(I(cols[1])="
如果我换成or cols[1],也会发生同样的事情。I()eval()
如何将向量中的那个项目输入到data.frame()命令中?
更新:
对于某些背景,我定义了一个函数calc.means(),它接受一个数据框和一个变量列表,并执行一个大而复杂的 ddply 操作,在变量指定的级别进行汇总。
我试图用该命令做的是将聚合级别返回到最顶层,在每一步data.frame()重新运行并使用将结果粘合到另一个上。我需要添加具有“全部”值的虚拟列,以使 rbind 正常工作。calc.means()rbind()
基本上,我正在将类似滚动cast的边距功能添加到 ddply 中,并且我不想为每次运行重新输入列名。这是完整的代码:
r - 如何在 R 中构造和重新编码杂乱的分类数据?
我正在努力解决如何最好地构建混乱的分类数据,这些数据来自我需要清理的数据集。
编码方案
我正在分析大学科学课程考试的数据。我们正在研究学生回答的模式,我们开发了一种编码方案来表示学生在回答中所做的事情。编码方案的一个子集如下所示。
请注意,在每个主要代码 (1, 2, 3) 中都有嵌套的非唯一子代码 (a, b, ...)。
原始数据是什么样的
我创建了我的实际数据的匿名原始子集,您可以在此处查看。我的部分问题是那些对数据进行编码的人注意到一些学生表现出多种模式。编码人员的解决方案是创建足够的列 ( reason1, reason2, ...) 来容纳具有多种模式的学生。这变得很重要,因为顺序 ( reason1, reason2) 是任意的——正确应用“依赖关系”的两个学生(如我的
数据集中的学生 41 和学生 42 )都应该在分析中注册,无论3a出现在reason列中还是reason2列中。
如何最好地构建学生数据?
我的部分问题是,在原始数据中,并非所有学生都以相同的顺序显示相同的模式或相同数量的模式。有些学生可能只做一件事,有些学生可能会做几件事。因此,示例学生的抽象表示可能如下所示:
请注意,在上面的示例中student002,student003两者都被编码为“1b”,尽管我故意将顺序显示为不同以反映我的数据的实际情况。
我的(实际)问题
- 我应该将
reason1,reason2,连接...成一列吗? - 我如何(重新)编码
reasonR 中的 s 以反映某些学生的多样性?
谢谢
我意识到这个问题既是关于良好的数据概念化的问题,也是关于 R 的特定特性的问题,但我认为在这里问这个问题是合适的。如果你觉得我问这个问题不合适,请在评论中告诉我,stackoverflow 会自动在我的收件箱中塞满悲伤的表情。如果我还不够具体,请告诉我,我会尽力说得更清楚。