问题标签 [numerical-stability]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
python - Keras:损失在inf和number之间波动
我正在研究具有混合密度网络最终层提供的自定义损失函数的 Keras 模型(损失试图最小化某些高斯模型的负对数似然)。
让我感到困惑的是,损失有时会达到一个时期,在该时期它返回 -inf 作为结果损失。然后下一次迭代损失将再次是一个数字(例如-2.1)。损失有时会在负无穷大和每隔一个时期出现一个数字之间反弹。
NLL 损失显然可以预料到负损失,但这种波动让我感到困惑。是什么解释了 Keras 中的这种行为?我的理解是 -inf 损失是由某处的数字下溢引起的,但我不确定模型如何从中恢复并在此后重新建立数字稳定性。
有谁知道这是如何工作的?对于其他人可以就这个问题提出的任何建议,我将不胜感激。
c - 单纯形算法的数值稳定性
编辑:单纯形数学优化算法,不要与单纯形噪声或三角测量相混淆。
我正在实现自己的线性规划求解器,我想使用 32 位浮点数来实现。我知道 Simplex 对数字的精度非常敏感,因为它执行大量计算,如果使用的精度太低,可能会出现舍入误差。但是,我仍然想使用 32 位浮点数来实现它,这样我就可以将指令设为 4 宽,也就是说,我可以使用 SIMD 一次执行 4 次计算。我知道我可以使用双打并制作 2 宽的指令,但 4 大于 2 :)
我的浮点实现遇到了问题,其中解决方案不是最理想的,或者问题被认为是不可行的。这尤其发生在混合整数线性程序中,我用分支定界法解决了这个问题。
所以我的问题是:如何尽可能防止舍入错误导致不可行、无界或次优的解决方案?
我知道我可以做的一件事是缩放输入值,使它们接近一(http://lpsolve.sourceforge.net/5.5/scaling.htm)。还有什么我可以做的吗?
tensorflow - Tensorflow:在除法之前添加小数字以实现数值稳定性
为了防止在 TensorFlow 中除以零,我想在我的股息中添加一个很小的数字。快速搜索没有产生任何结果。特别是,我对使用科学记数法很感兴趣,例如
如何做到这一点?
r - 增加观察次数有 R 抛出随机系数 - 数值稳定性问题?
我有这个代码
我希望系数类似于 [1,2]。
相反,N =20000R 不断向我抛出统计上不显着且不适合模型的随机数,$R^2$ 真的很低..我只是不明白我做错了什么。这里是一个示例输出:
但是,如果我输入 N=200 或 N=2000,它会起作用。系数与真实系数相似,并且在真实系数的两个标准差内,我得到的 $R^2$ 值高达 99%,并且这些系数在 $p<<0.01$ 的情况下都具有统计学意义。
这里发生了什么?为什么增加观察次数会使回归恶化?R是否暗中遇到数值稳定性问题?
我在 Kubuntu 19.04 上运行 R 3.6.0。使用 --vanilla 选项在命令行上运行 R 也会出现同样的问题。
编辑:这是输出sessioninfo()
tensorflow - 带有 'relu' 的 LSTM 'recurrent_dropout' 产生 NaN
任何非零都会recurrent_dropout产生 NaN 损失和权重;后者是 0 或 NaN。发生在堆叠的、浅的、stateful, return_sequences= 任何、带有 & w/o Bidirectional()、activation='relu', 的情况下loss='binary_crossentropy'。NaN 出现在几批中。
有什么修复吗?帮助表示赞赏。
已尝试故障排除:
recurrent_dropout=0.2,0.1,0.01,1e-6kernel_constraint=maxnorm(0.5,axis=0)recurrent_constraint=maxnorm(0.5,axis=0)clipnorm=50(凭经验确定),那达慕优化器activation='tanh'- 无 NaN,重量稳定,最多可测试 10 个批次lr=2e-6,2e-5- 无 NaN,重量稳定,最多可测试 10 个批次lr=5e-5- 没有 NaN,权重稳定,3 批次 - 第 4 批次的 NaNbatch_shape=(32,48,16)- 2批次的大损失,第3批次的NaN
注意: ,每批batch_shape=(32,672,16)17 次调用train_on_batch
环境:
- Keras 2.2.4(TensorFlow 后端)、Python 3.7、Spyder 3.3.7(通过 Anaconda)
- GTX 1070 6GB,i7-7700HQ,12GB RAM,Win-10.0.17134 x64
- CuDNN 10+,最新的 Nvidia 驱动器
附加信息:
模型发散是自发的,即使使用固定种子(Numpy、Random 和 TensorFlow 随机种子)也会发生在不同的训练更新中。此外,当第一次发散时,LSTM 层的权重都是正常的——只是稍后才变为 NaN。
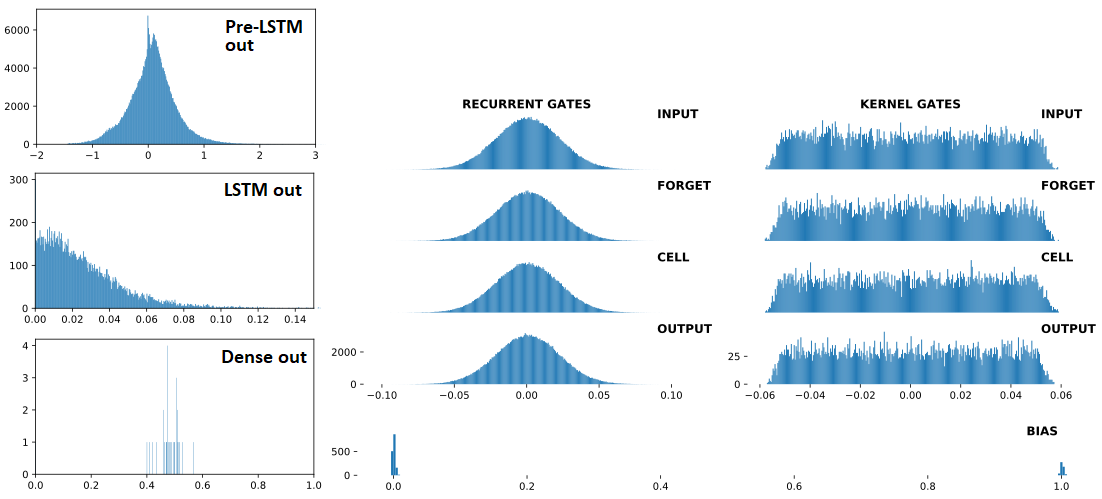
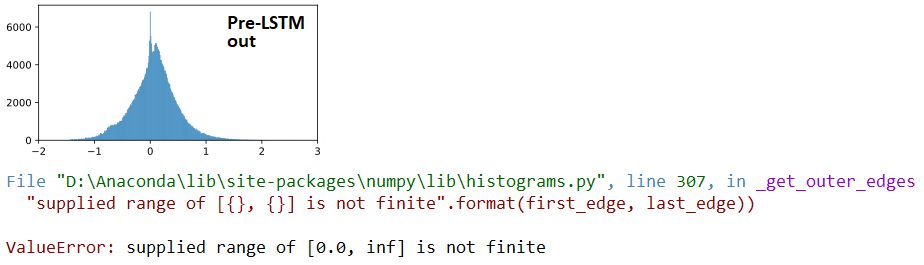
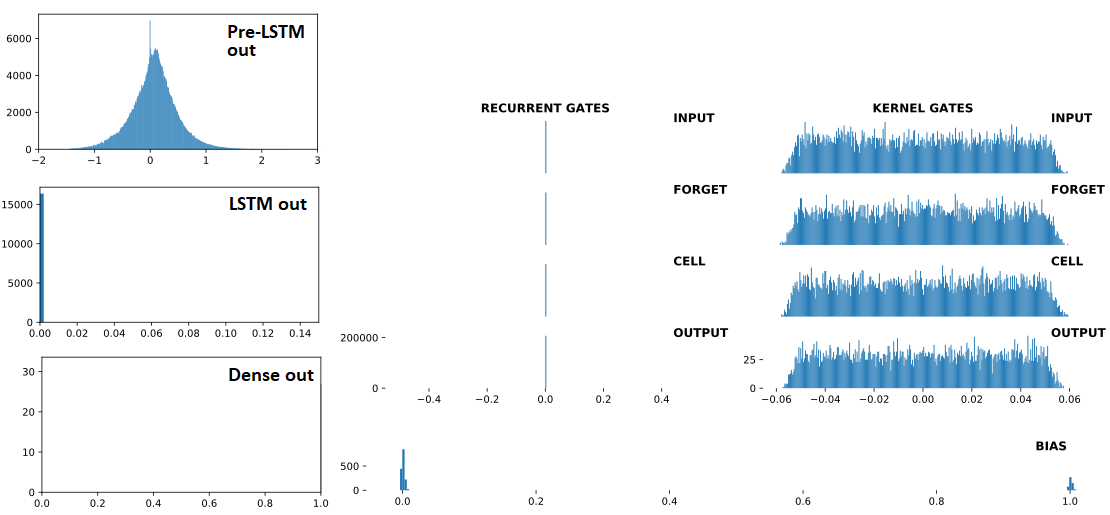
以下是,按顺序:(1)输入LSTM;(2)LSTM输出;(3)Dense(1,'sigmoid')输出——三个是连续的,Dropout(0.5)在每个之间。前面的(1)是Conv1D层。右:LSTM 权重。“之前” = 1 次火车更新之前;"AFTER = 1 次列车更新后
分歧前:
AT 分歧:
分歧后:
最小的可重复示例:
观察:以下加速发散:
- 更高
units(LSTM) - 更高的层数(LSTM)
- 更高
lr<<时没有发散<=1e-4,测试了多达 400 列火车 - 更少
'1'的标签<<与下面没有分歧y,即使是lr=1e-3; 测试多达 400 辆列车
y = np.random.randint(0,2,32) # makes more '1' labels
更新:在 TF2 中未修复;from tensorflow.keras也可以使用进口来重现。
python - 如何测试我的代码的数值稳定性?
我有以下计算数字流的平均值和标准差的方法
因为我想在一般应用程序中使用这个类,所以我想让它尽可能健壮。我已尽我所能通过尽可能晚地放置求和和乘法(即可能破坏数字的操作)来使代码在数值上稳定。
我有以下代码,我编写该代码是为了测试我update从 中执行批量更新的正确性update_single,我知道这是正确的:
为了尝试测试它的数值稳定性,我尝试使用一些非常小和一些非常大的数字,方法是将#-marked 行替换为:
这段代码打印出来:
如您所见,这些数字非常相似,但并不完全相同。我的代码在数值上是否稳定,有没有比我上面的更好的方法来测试它?
python-3.x - 为什么我计算图像标准偏差的两种方法返回不同的结果?
我有一个由大约 17,000 张图像组成的数据集,每个图像的大小为 3000x1700。
我有两种计算数据集均值和标准差的方法:逐像素方法和逐图像方法。逐像素方法简单地计算数据集中所有像素的均值和标准差(使用Welford 的在线算法,因为总共有太多像素,无法一次将它们全部存储在内存中)。image-wise 方法计算数据集中所有图像的均值和方差,然后对它们进行平均(并将 sqrt 应用于平均方差以获得标准偏差)。
一般来说,这两种方法显然不会返回相同的结果,因为按图像的方法会给不同大小的图像赋予相同的权重。但是,我的数据集中的所有图像都具有完全相同的大小,因此在我的情况下,这两种算法应该返回相同的均值和标准值。
现在,当运行此代码时,它开始正常,在它报告的第一张图像之后:
σ 值只有轻微的偏差。然而,随着使用更多图像,此错误会变得越来越大。
最后,在整个数据集上运行该过程后,错误变得非常显着:
如您所见,即使使用了整个数据集,这两种方法的均值也几乎相同。然而,标准差结果相差甚远,尽管它们对于两种方法应该是相同的。我的两种方法中的哪一种在这里有问题,为什么?
python - 计算(平方)欧几里得距离的替代方法的数值问题
我想快速计算平方欧几里得,如下所述:
注意1:我只对距离感兴趣,而不是RBF 内核。
注意2:这里我忽略numexpr了,只直接使用numpy。
简而言之,我计算:
~10与此相比,我能够更快地计算距离矩阵scipy.pdist。但是,我观察到数值问题,如果我取平方根来获得欧几里德距离,情况会变得更糟。我的值大约为1E-8 - 1E-7,应该完全为零(即重复点或到自身点的距离)。
问题:
有没有办法或想法来克服这些数值问题(最好在不牺牲太多评估速度的情况下)?或者数字问题是为什么这条路径首先没有被采用(例如 by scipy.pdist)的原因?
例子:
这是一个显示数值问题的小代码示例(不是加速,请查看上面链接的 SO 线程的答案)。
示例输出:
正如您所看到的,一些值也是负数(这导致在nan取 sqrt 之后)。当然这些很容易捕捉——但是对于欧几里得情况来说,小的积极因素有很大的错误(例如abs_error=5.96046448e-08)
python-3.x - 使用 JiTCDDE 的意外解决方案
我正在尝试使用 Python 研究以下延迟微分方程的行为:
其中f是一个截止函数,当其参数的绝对值在 1 和 10 之间时,它基本上等于恒等式,否则等于 0(见图 1),并且Nd和τ是T常数。

为此,我使用包 JiTCDDE。这为上述方程提供了一个合理的解。然而,当我尝试在等式右侧添加噪声时,我得到的解在几次振荡后稳定到非零常数。这不是方程的数学解(唯一可能的常数解等于零)。我不明白为什么会出现这个问题以及是否有可能解决它。
我在下面重现我的代码。在这里,为了简单起见,我用高频余弦代替了噪声,它被引入方程系统作为虚拟变量的初始条件(余弦可以直接引入系统,但对于一般噪音,这似乎是不可能的)。为了进一步简化问题,我还删除了涉及f函数的术语,因为没有它也会出现问题。图 2 显示了代码给出的函数图。

顺便说一句,我注意到即使没有噪音,解决方案在零点似乎也是不连续的(对于负时间,y 设置为零),我不明白为什么。
decimal-point - 平原三点定向运算的数值稳定性
下面的照片是一篇论文的一部分(Nam-Du ̃ng Hoang 等人的 Quicker than Quickhull),它是关于使用叉积的平原中三点的定向算子。

据说(4)的数值稳定性一般比(2)和(3)差。从互联网上找到的资源,我可以预期,但我不知道为什么会这样。
当涉及到计算机计算时,小数点运算不是很准确。谁能解释(或比较(2)~(4)方程)在数值稳定性方面究竟发生了什么?