问题标签 [linguistics]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
java - 如何用java获取句子的逻辑部分?
假设有一句话:
将其更改为
不会破坏句子的意义,它仍然有效。以任何其他方式洗牌会产生奇怪的无效句子。所以基本上,我说的是句子的一部分,它使信息更具体,但删除它们并不会破坏整个句子。是否有任何 NLP 库可以识别这些部分?
parsing - 字符和文本处理资源(编码、正则表达式、NLP)
我想学习编码、字符和文本的基础。了解这些对于处理大量文本非常重要,无论是日志文件还是用于构建集体智能算法的文本源。我目前的知识非常基础:比如“只要我使用 UTF-8,我就没事”。
我并不是说我需要立即学习高级主题。但我需要知道:
- 位和字节级别的编码知识。
- 英文中未使用的字符和字母。
- 多字节编码。(我懂一些中文和日文。解析它们很重要。)
- 常用表达。
- 文本处理算法。
- 解析自然语言。
我还需要了解数学和语料库语言学。当前和未来的网络(语义、智能、实时网络)需要处理、解析和分析大文本。
我正在寻找一些资源(也许是书籍?),让我开始了解一些项目符号。(我在 Stack Overflow 上找到了很多关于正则表达式的有用讨论。因此,您无需就该主题提出资源建议。)
php - 从错误的单词 php 中获取正确的单词
我想知道如何从错误的单词中得到正确的单词...
例子
字符串是“字符串”
但正确的词是字符串...
php中有什么算法吗?
谢谢并提前
latex - LaTeX 中的双行双语段落
行间光泽可用于对文档的翻译进行布局。
http://en.wikipedia.org/wiki/Interlinear_gloss
通常这是逐字或逐词素完成的。但是,我想以不同的方式执行此操作,一次翻译整个段落。以下链接和图像是我想要完成的示例,尽管我想为更大的不同文本执行此操作。
http://www.optimnem.co.uk/learning/spanish/three-little-pigs.php
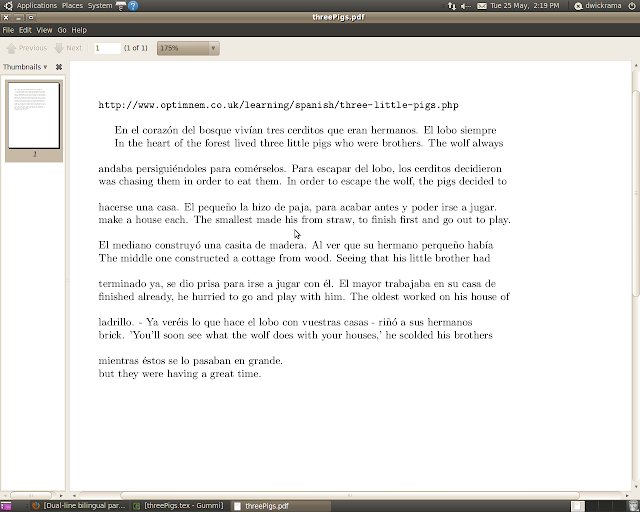
现在我对考虑在语言之间改变顺序的单词或短语的顺序不感兴趣。也就是说,我不介意段落中的单词是否未对齐,或者一个段落的长度是否比另一个长得多,从而导致悬垂线。
据我所知,以下软件包不能满足我的需求:
这是英文版:
这是西班牙语版本:
我不想像这样手动进行:
我想使用一个包或一个宏来自动让英文和西班牙文文本在到达每个行尾时穿插换行符。如何以更自动化的方式在 Latex 中布局这个简单的双行双语段落(无需手动添加换行符)?
linguistics - 活用英语的软件
有没有软件可以做到以下几点?
给定一个英文句子,如
“他喜欢烤豆”,
我将“他”改为“我”,句子变为
“我喜欢烤豆”
(注意 S)
或者
“她的头发扎成马尾辫”
我将“她”改为“他”,句子变为
“他的头发扎成马尾辫”。
同样,可以把句子变成过去式,
“她的头发扎成马尾辫”。
这样的软件是否存在?
php - 贝叶斯分类器的 PHP 实现:将主题分配给文本
在我的新闻页面项目中,我有一个数据库表news,其结构如下:
此外,还有一个包含词频信息的表格贝叶斯:
现在我希望我的 PHP 脚本对所有新闻条目进行分类,并为它们分配几个可能的类别(主题)之一。
这是正确的实现吗?你能改进它吗?
培训是手动完成的,它不包含在此代码中。如果将文本“你可以通过出售房地产赚钱”分配给类别/主题“经济学”,那么所有单词(you,can,make,...)都将插入到表贝叶斯中,其中“经济学”为主题和 1作为标准计数。如果单词已经与相同的主题组合在一起,则计数会增加。
样本学习数据:
字数主题
卡钦斯基政治 1
索尼技术 1
银行经济学 1
电话技术1
索尼经济学 3
爱立信科技2
样本输出/结果:
文字标题:电话测试索尼爱立信阿斯彭-敏感温贝里
政治
....电话 ....测试 ....索尼 ....爱立信 ....阿斯彭 ....敏感 ....winberry
技术
....发现手机 ....测试 ....索尼发现 ....爱立信发现 ....aspen ....敏感 ....winberry
经济学
....电话 ....测试 ....发现索尼 ....爱立信 ....阿斯彭 ....敏感 ....温莓
结果:文本属于主题技术,可能性为 0.013888888888889
非常感谢您!
python - Justadistraction:对没有空格的英语进行标记。村上羊人
我想知道如果删除了空格,您将如何用英语(或其他西方语言)标记字符串?
这个问题的灵感来自村上小说《舞舞舞》中的羊人角色
在小说中,羊人被翻译成这样说:
“就像我们说的,我们会做我们能做的。试着把你重新连接到你想要的,”羊人说。“但我们不能一个人做。你也得工作。”
因此,保留了一些标点符号,但不是全部。足以让人类阅读,但有些武断。
您为此构建解析器的策略是什么?字母、音节计数、条件语法、前瞻/后置正则表达式等的常见组合?
具体来说,python 方面,您将如何构建(宽容的)翻译流程?不是要求一个完整的答案,而是更多你的思考过程将如何分解问题。
我以一种轻浮的方式问这个问题,但我认为这个问题可能会得到一些有趣的(nlp/crypto/frequency/social)答案。谢谢!
python - Python - 英文翻译
用 Python 编写程序以将英语单词和/或短语翻译成其他语言的最佳方法是什么?
compare - 计算相对的 Levenshtein 距离 - 有意义吗?
我同时使用 Daitch-Mokotoff soundexing 和 Damerau-Levenshtein 来确定应用程序中的用户条目和值是否“相同”。
Levenshtein 距离是否应该用作绝对值?如果我有一个 20 个字母的单词,那么 4 的距离还不错。如果单词有4个字母...
我现在正在做的是获取距离/长度以获得更好地反映单词已更改百分比的距离。
这是一种有效/经过验证的方法吗?还是单纯的愚蠢?