问题标签 [tidytext]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
{kind=link}
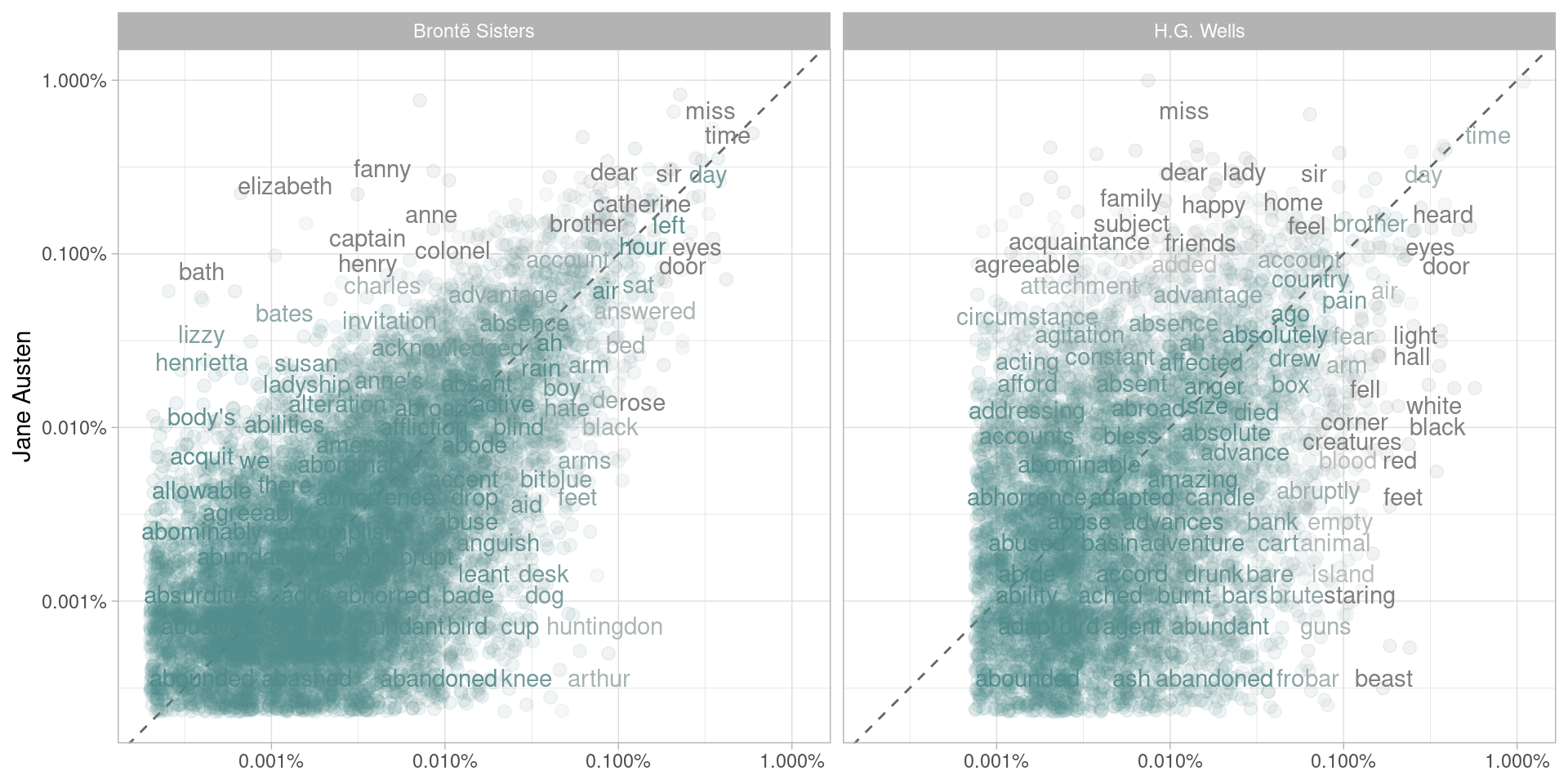
r - ggplot'非有限值'错误
df我有一个看起来像这样的 R 数据框 ( ):
我想用ggplot2绘图n除以total每个blogger.
我有这个代码:
但它会产生这个警告:
tm - 使用 r-tm 读取文档以使用 r-mallet
我有这段代码来拟合主题模型和MALLET 的 R 包装器:
我已经使用tm包来读取我的文档,这些文档是目录中的 txt 文件:
语料库不能用作 的输入mallet.import,那么我如何从myCorpus上面的 tm 语料库DF到调用的?
r - Getting tf idf when documents are defined by two columns
I'm doing text analysis using tidytext. I am trying to calculate the tf-idf for a corpus. The standard way to do this is:
However, in my case, the 'document' is not defined by a single column (like book). Is it possible to call bind_tf_idf where the document is defined by two columns (for example, book and chapter)?
r - 计算“行”标记中的单词
我是 R 的新手,所以这个问题似乎很明显。但是,我没有管理,也没有找到解决方案
当它们是行(实际上是评论)时,如何计算我的标记中的单词数?因此,有一个带有评论(reviewText)的数据集与产品 ID(asin)相关联
amazonr_tidy_sent = amazonr_tidy_sent%>%unnest_tokens(word, reviewText, token = "lines")
amazonr_tidy_sent = amazonr_tidy_sent %>% anti_join(stop_words)%>%ungroup()
我尝试按照以下方式进行
wordcounts <- amazonr_tidy_sent %>%
group_by(word, asin)%>%
summarize(word = n())
但这不合适。我认为,没有办法计算,因为作为标记的行不能“分离”
非常感谢
r - 无法在 R 中安装软件包
安装软件包时出现以下错误:
请建议如何解决此错误。
r - tidytext 从文件夹中读取文件
我正在尝试将 pdf 文件的文件夹读入 R 中的数据框。我可以使用pdftools库和pdf_text(filepath).
理想情况下,我可以获取一系列 pdf 的作者和标题,然后将其推送到具有这些列的数据框中,以便我可以tidytext在文本上使用基本功能。
对于现在的单个文件,我可以使用:
在这里,我有一个带有单个单词的数据框。我想进入一个数据框,其中我有文章解包,包括标题和作者列。
r - 安装包 tidytext 时出错 - R
我尝试安装包 tidytext 但收到以下错误:
谁能帮我理解我错过了什么?谢谢
r - 在 R 的 tidytext 中使用 unnest_tokens() 保留标点符号
我正在使用tidytextpackage inR进行 n-gram 分析。
由于我分析推文,因此我想保留 @ 和 # 以捕获提及、转发和主题标签。但是,unnest_tokens函数会自动删除所有标点符号并将文本转换为小写。
我发现unnest_tokens有一个使用正则表达式的选项 using token='regex',所以我可以自定义它清理文本的方式。但是,它只适用于 unigram 分析,它不适用于 n-gram,因为我需要定义token='ngrams'来进行 n-gram 分析。
有没有办法防止unnest_tokens在 n-gram 分析中将文本转换为小写?
r - 如何从列中提取月份
我想从 Textmining with R web 教科书创建一个绘图,但使用我的数据。它基本上每年搜索最热门的术语并将它们绘制成图表(图 5.4:http ://tidytextmining.com/dtm.html )。我的数据比他们开始使用的数据要干净一些,但我是 R 新手。我的数据有一个“日期”列,格式为 2016-01-01(它是一个日期类)。我只有 2016 年的数据,所以我想做同样的事情,但更细化,(即按月或按天)
这个想法是我会从我的文本中选择我的特定单词,看看它们在几个月内如何变化。
谢谢!