问题标签 [neural-network]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
c++ - C++ 将 shared_ptr 提升为 hash_map 键
我正在制作一个神经网络,并希望使用 hash_map 来为每个神经元的输出神经元保留权重参考:
我意识到我不能使用 boost::shared_ptr 作为 stdext::hash_map 的键,那么还有什么建议呢?是否有任何变通方法或者是使用不同键或切换到 std::map 的唯一选择?谢谢!
这是错误:
java - Joone vs. Encog - 生产应用
有没有人在生产应用程序中同时使用 Joone 和 Encog?您是否需要在产品应用程序中使用其中一个或另一个产品不足的地方做些什么?
artificial-intelligence - 霍普菲尔德神经网络
你知道除了模式识别之外的任何应用程序。为了实现 Hopfield 神经网络模型值得吗?
statistics - 具有目标函数的多元映射/回归
概述
我有一个维度为 N 的“输入”的多元时间序列,我想将其映射到维度为 M 的输出时间序列,其中 M < N。输入的范围为 [0,k],输出的范围为 [0,1 ]。我们将序列中某个时间片的输入向量称为“ I[t] ”,将输出向量称为“ O[t] ”。
现在,如果我知道对<I[t], O[t]>的最佳映射,我可以使用一种标准的多元回归/训练技术(例如 NN、SVM 等)来发现映射函数。
问题
我不知道特定<I[t], O[t]>对之间的关系,而是对输出时间序列的整体适应度有所了解,即适应度由完整输出序列上的惩罚函数控制。
我想确定映射/回归函数“ f ”,其中:
这样惩罚函数 P(O) 被最小化:
[请注意,惩罚函数 P 正在将f的多次应用生成的结果系列应用于I[t]的跨时间。也就是说f是I[t]的函数,而不是整个时间序列]
I 和 O 之间的映射非常复杂,以至于我不知道哪些函数应该构成它的基础。因此,期望必须尝试许多基函数。
对解决此问题的一种方法有看法,但不希望对提案产生偏见。
想法?
machine-learning - 需要好的方法来选择和调整“学习率”
在下图中,您可以看到一个学习算法试图学习产生所需的输出(红线)。学习算法类似于反向误差传播神经网络。
“学习率”是一个控制训练过程中调整大小的值。如果学习率太高,那么算法学习很快,但是它的预测在训练过程中跳跃很多(绿线 - 学习率 0.001),如果它较低,那么预测跳跃更少,但是算法需要一个学习时间更长(蓝线 - 学习率为 0.0001)。
黑线是移动平均线。
如何调整学习率,使其最初收敛到接近所需的输出,但随后减慢速度以便它可以磨练正确的值?
学习率图 http://img.skitch.com/20090605-pqpkse1yr1e5r869y6eehmpsym.png
{kind=link}
neural-network - 用于神经网络训练的数据集
我正在寻找一些相对简单的数据集来测试和比较人工神经网络的不同训练方法。我希望不需要太多预处理的数据将其转换为输入和输出列表的输入格式(标准化为 0-1)。任何链接表示赞赏。
reverse-engineering - 反编译器的ANN?
有没有尝试在反编译中使用人工神经网络?如果可以将经过修剪的源语义连同代码一起提供给神经网络,这样它就可以学习两者之间的联系,那就太好了。我认为当有优化时这可能会失去它的有效性,并且可能对高级语言也更好,但我有兴趣听到任何人对此进行的任何尝试。
python - 神经网络输入/输出
谁能向我解释如何做更复杂的数据集,比如团队统计数据、天气、骰子、复数类型
我了解所有数学以及一切如何运作我只是不知道如何输入更复杂的数据,然后如何读取它吐出的数据
如果有人可以在 python 中提供示例,那将是一个很大的帮助
matlab - Matlab - 神经网络训练
我正在创建一个带有反向传播的 2 层神经网络。NN 应该从 20001x17 向量中获取其数据,该向量在每一行中包含以下信息:
- 前 16 个单元格包含范围从 0 到 15 的整数,这些整数充当变量,帮助我们确定在看到这些变量时要表达的 26 个字母中的哪一个。例如,一系列 16 个值表示字母 A:[2 8 4 5 2 7 5 3 1 6 0 8 2 7 2 7]。
- 第 17 个单元格包含一个从 1 到 26 的数字,代表我们想要的字母表中的字母。1代表A,2代表B等等。
NN 的输出层由 26 个输出组成。每次向 NN 输入如上所述的输入时,它应该输出一个 1x26 向量,其中除了与输入值要表示的字母相对应的一个单元格之外,其他所有单元格都包含零。例如,输出 [1 0 0 ... 0] 将是字母 A,而 [0 0 0 ... 1] 将是字母 Z。
在我展示代码之前,一些重要的事情:我需要使用 traingdm 函数,并且隐藏层数(目前)固定为 21。
为了创建上述概念,我编写了以下 matlab 代码:
现在我的问题是:我希望我的输出如所描述的那样,即 y2 向量的每一列例如应该是一个字母的表示。我的代码没有这样做。相反,它产生的结果在 0 和 1 之间变化很大,值从 0.1 到 0.9。
我的问题是:我需要做一些我不需要做的转换吗?意思是,我是否必须将我的输入和/或输出数据转换为我可以实际查看我的 NN 是否正确学习的形式?
任何输入将不胜感激。
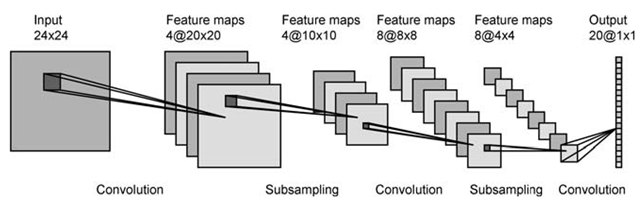
artificial-intelligence - 卷积神经网络 - 如何获得特征图?
我读了一些关于卷积神经网络的书籍和文章,似乎我理解了这个概念,但我不知道如何像下图那样把它表达出来:(
来源:what-when-how.com)
{kind=link}
从 28x28 归一化像素输入,我们得到 4 个大小为 24x24 的特征图。但如何得到它们?调整输入图像的大小?或执行图像转换?但是什么样的转变呢?或将输入图像切割成 4 块 24x24 x 4 角?我不明白这个过程,对我来说,他们似乎在每一步都将图像切割或调整为更小的图像。请帮忙谢谢。