我读了一些关于卷积神经网络的书籍和文章,似乎我理解了这个概念,但我不知道如何像下图那样把它表达出来:(
来源:what-when-how.com)
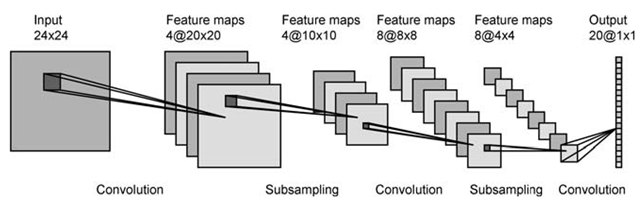{kind=link}
从 28x28 归一化像素输入,我们得到 4 个大小为 24x24 的特征图。但如何得到它们?调整输入图像的大小?或执行图像转换?但是什么样的转变呢?或将输入图像切割成 4 块 24x24 x 4 角?我不明白这个过程,对我来说,他们似乎在每一步都将图像切割或调整为更小的图像。请帮忙谢谢。
我读了一些关于卷积神经网络的书籍和文章,似乎我理解了这个概念,但我不知道如何像下图那样把它表达出来:(
来源:what-when-how.com)
从 28x28 归一化像素输入,我们得到 4 个大小为 24x24 的特征图。但如何得到它们?调整输入图像的大小?或执行图像转换?但是什么样的转变呢?或将输入图像切割成 4 块 24x24 x 4 角?我不明白这个过程,对我来说,他们似乎在每一步都将图像切割或调整为更小的图像。请帮忙谢谢。
这是 CONV2 函数的 matlab 帮助文件,在 CNN Matlab 中使用(获取卷积层)。仔细阅读,你会看到答案。
%CONV2 Two dimensional convolution.
% C = CONV2(A, B) performs the 2-D convolution of matrices A and B.
% If [ma,na] = size(A), [mb,nb] = size(B), and [mc,nc] = size(C), then
% mc = max([ma+mb-1,ma,mb]) and nc = max([na+nb-1,na,nb]).
%
% C = CONV2(H1, H2, A) convolves A first with the vector H1 along the
% rows and then with the vector H2 along the columns. If n1 = length(H1)
% and n2 = length(H2), then mc = max([ma+n1-1,ma,n1]) and
% nc = max([na+n2-1,na,n2]).
%
% C = CONV2(..., SHAPE) returns a subsection of the 2-D
% convolution with size specified by SHAPE:
% 'full' - (default) returns the full 2-D convolution,
% 'same' - returns the central part of the convolution
% that is the same size as A.
% 'valid' - returns only those parts of the convolution
% that are computed without the zero-padded edges.
% **size(C) = max([ma-max(0,mb-1),na-max(0,nb-1)],0).**