问题标签 [weighted]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
javascript - JavaScript 加权随机或时间百分比
我有一个每 100 毫秒运行一次的 Node.js 进程 (setInterval)。我有一些我想每隔 x 时间采取的行动。例如,2% 的时间做 X,10% 的时间做 Y,等等。
现在,我基本上是这样做的:
问题是它非常不一致。您可能希望if(rand > 900)至少接近 10% 的时间,但有时可能连续 10 倍或根本没有。
如果我们假设 100 毫秒间隔是固定的,那么任何人都会对更好的解决方案提出建议,该解决方案会更准确。
谢谢!
编辑:基于 Dr. Dredel 的评论:
line - 加权最小二乘法找到最佳拟合线
我正在尝试找出最适合多个数据点 (x,y) 的线。我正在使用这里描述的最小二乘法http://faculty.cs.niu.edu/~hutchins/csci230/best-fit.htm
但是我需要调整算法,以便我可以为每个数据点添加权重,并且线条将更倾向于数据集中比其他点更重要的点。
请注意,我只知道非常基本的统计数据,因此请记住,您在回答时是在向具有基本知识的人解释。
javascript - 数组的加权平均值
我必须在 JavaScript 中编写以下加权平均公式:
平均值 = (p1*p2*x1 + p3*p4*x2 + ... +p(n-2)*p(n-1)*xn) / (p1*p2 + p3*p4 + ... + p (n-2)p(n-1) )
该公式给出了值的平均值x。
我还使用JavaScriptarray填充了n元素:
...我想找到平均值pi的权重和值在哪里。xi
如何使用此数组编写公式?
java - 利用负循环寻找图上两个节点之间的零/负权重路径
我真的很难在标题中描述这一点,但我会以更长的格式试一试。
我真的被这个问题难住了,我不是在寻找答案,只是一点帮助或一些需要阅读的特定主题。
我所拥有的是一个有向图,具有各种权重的边,包括负数和正数。我试图做的是编写一个算法,该算法提供了两个位于图上的节点(并假设它们是连接的)在它们之间找到一条路径,导致路径的总权重为零或负数。路径可以多次包含节点(希望允许路径抵消包含边的正权重)。
我目前正在阅读 Russel 和 Norvig 的人工智能,但由于各种问题(算法不断循环负循环),我正在努力寻找一种方法将文本中的逻辑应用于我的问题。我不完全了解如何为此使用 Backtrack 和 AStar 等方法
如果有人可以为我指出正确的方向,这将有助于我更好地理解我的问题,那将是一个很大的帮助,我可以很好地处理 DFS 和 BFS 以及与图表相关的许多其他事情,但必须找到一条路径两个节点之间的重量限制真的让我很困惑。
谢谢
下面我包含了一个示例图,我需要能够找到从 Start 到 Goal 的路径,其中路径的总权重不超过零。
示例图 http://i144.photobucket.com/albums/r166/ZooropaTV/bu.jpg
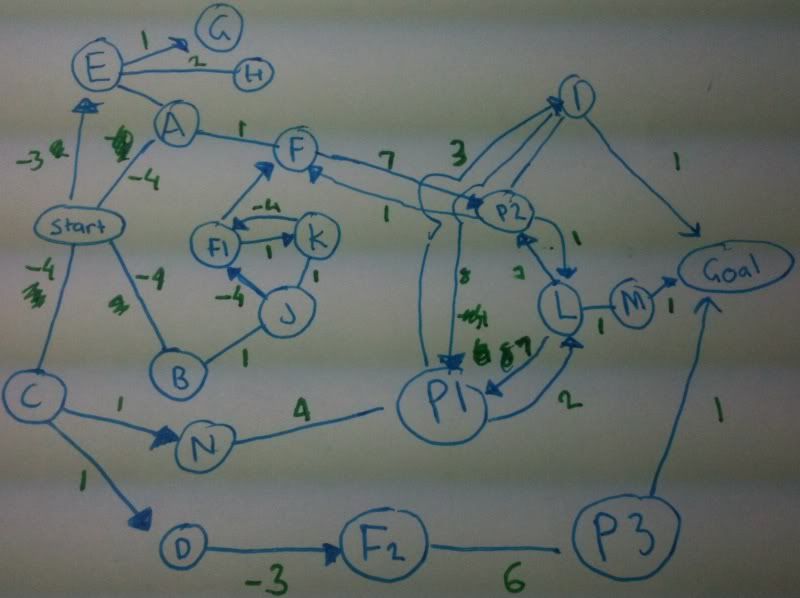{kind=link}
刚刚意识到我一直在做的很多搜索/阅读都被误导了,因为我的目标不一定是找到按重量计算的最短路径,而是通过访问所需的最少节点数,我需要换个思路现在关于它,但仍然想要任何建议
algorithm - 保持顺序的两个有序列表中项目的最优配对策略算法
我有以下两个有序的项目列表:
每个项目都有一个等于字符串长度的分数,所以......
我想创建一个对 (A,B) 的列表,其中包含来自 A 的索引或来自 B 的索引或两者的一对,而不更改它们出现在每个列表中的顺序。
然后每对都有其项目的分数,因此通过配对项目,我们将两个项目的总分减半。我想得到分数最低的对组合。
例如,在上面的两个列表中,每个项目都可以配对,但有些配对会阻止我们配对其他项目,因为我们无法在不更改其中一个列表的顺序的情况下同时配对。例如,我们不能配对"blueberries",也不能在一个列表中配对,但在另一个列表"oranges"中配对。我们只能配对一个或另一个。每个列表也可以多次包含相同的项目。"oranges" "blueberries"
上述问题的最优结果是...
我认为答案大致如下:
- 找到对
- 将这些对分成可能的对组
- 计算权重最大的组
我可以通过将一个列表中的对连接到另一个列表来确定哪些对在视觉上排除了哪些其他对,如果该连接与另一个连接相交,它将排除它。我不确定这将如何以编程方式完成。
我怎么解决这个问题?
algorithm - 使用逐渐冒泡的列表项执行加权洗牌的算法
我想知道是否有人知道一种简单的算法来执行列表的洗牌,该算法允许权重偏差,以便列表中的每个项目同时朝着列表的顶部工作。
我正在一个网站上使用分页目录中的企业列表,并且列表需要公平显示,因此一个企业不能总是高于/低于另一个列表。目录的纯粹洗牌是不够的,因为它的随机性可能会导致任何给定的企业在很长一段时间内随机洗牌到列表中的相似位置,所以我想提供一些权重,以便每个列表被慢慢地推到列表中,以便随着时间的推移,它们有相当平等的机会显示在目录的第一页上。
编辑:
在凯文的感谢下 - 我正在尝试将这些规则正式化:
1)对于 n 个列表,每个列表必须在 n 个“准随机播放”中显示在位置一)
2)(模糊)列表的平均(?)位置应该随着时间的推移而增加,直到它到达位置 1
3) 对于任意两个业务(A 和 B),在 n 次洗牌迭代中,A 不能超过 B 超过 50% 的时间?
我还应该补充一点,我为一家拥有极其复杂和令人费解的“洗牌器”的企业工作,这对于安抚大量付费客户而言是必要的,这些客户坚持在我们目录中的各个业务类别中公平分配。客户的投诉是一个“真正的”问题,因为用户通常从前几个分页页面中选择项目,按字母顺序(默认情况下)对客户进行排序是不公平的,并且鉴于用户从上到下阅读,这不是公平的是,一项业务始终高于另一项业务。
我很想知道是否有人对他们以前可能已经实施过的这个问题有一个整洁的解决方案。
编辑:
我有一个想法,考虑到这些项目存储在数据库中,我可以有一个列,它是每个列表位置随时间推移的总和,当一个项目到达第一个位置时,我可以使用它来排序(降序)然后我可以将列表设置为 0,这意味着列表中的每个项目最终都会排在列表的顶部。问题是,对于大量列表,随着时间的推移,这个数字可能会变得相当大......
编辑:
我不想猛击数据库,我需要在用户浏览时保持一致性,因此我只会每晚(每天一次)执行“伪随机播放”,而不是在目录的每次显示上
average - 如何计算每组的个人加权分数?
我有 20 个问题,每个问题进一步分为一组 4 个问题,这意味着总共有 5 组 A、B、C、D 和 E。每个问题有 5 分,所以在一组中可以得到的最大分数获得的是20。
在为每组进行的两次测试中,我得到以下结果
现在我想要的是我想要加重 C 和 D 组的重量,几乎是所有其他组的两倍。要计算加权百分比,请执行以下操作。
现在我想单独计算每组的加权百分比。例如,考虑到之前分别为 100% 和 80%,而没有考虑权重,集合 A 和集合 C(测试 1)的新加权百分比是多少。同样,对于测试 1 和测试 2 的加权平均值分别为 66.2% 和 89.64% 的所有单个百分比。
我试图提出一些逻辑,类似于以下内容,但我没有完全理解。可能你能帮助我吗?
无论如何,这可能吗?
c - 加权随机整数
我想为随机生成的数字分配权重,权重如下所示。
最有效的方法是什么?
algorithm - 一组 [low, high] 值对的加权随机
我有一个 {keyword: [low, high], keyword1: [low1, high1], keyword2: [low2, high2] ... } 的列表,我想在它上面运行一个加权随机算法来选择一个关键字每一个请求。无论如何,直接的算法会扭曲结果吗?
谢谢,拉贾。