问题标签 [tarsosdsp]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
java - 从麦克风流式传输,添加效果并使用 tarsos android 库保存到 wav 文件
注意:我正在使用 android studio,目前我正在使用最新的tarsos 音频库,它应该与 android 兼容,实际上已经成功地将该库添加到我的 android studio 项目中。我之前尝试过使用 JTransforms 和 Minim 库,但没有成功。2017 年 8 月 23 日编辑:发现并修复了一些错误,重新发布了当前代码,但实际问题总结如下:
摘要:在我发布的第 5 个代码块中,在被注释掉的第 15 行,我需要知道如何让该行工作而不抛出编译错误
我要做的是从麦克风录制,并在录制时使用 tarsos 库中的 dsp BandPass 过滤器并将结果输出到 .wav 文件。按照本教程,我可以通过使用 android.media 导入成功地将麦克风流式传输到 .wav 文件,但这不允许我添加 BandPass 过滤器,并且使用 tarsos 导入函数不允许我使用保存作为该教程具有的 .wav 方法,我知道我遗漏了一些东西和/或做错了什么,但是我已经用谷歌搜索了将近一个星期,还没有找到一个可行的解决方案,我只找到了指向库内 java 文件的链接这没有帮助,因为我找不到有关如何正确使用它们的教程。我究竟做错了什么?这是我尝试使用的 tarsos 方法的相关代码:
相关的导入和“全局”变量
这将在 onClick 方法中开始麦克风录制,并且通过注释/取消注释 2 个“运行”变量值之一,我可以在调用 startRecording 方法时在过滤器或无过滤器(android 或 tarsos 函数)之间切换
开始录音方法:
onClick 方法中的停止录制按钮
在此之前,这两种情况都很好,如果 running==4(应用了 tarsos dsp 过滤器)程序崩溃。如果我使用 running==5 (没有过滤器的 android.media 方式),其余的工作正常并保存文件,但没有应用带通效果。如果我尝试用 tarsos dispatcher = AudioDispatcherFactory... (例如 dispatcher = new AudioRecord...)交换 changedRecord = new AudioRecord... ,它们是不兼容的,甚至不会考虑编译。(这就是为什么下面方法中的第 15 行被注释掉了)
android - 在 dispatcher.addAudioProcessor(p) 中使用 Tarsos DSP 获取 NullPointer 异常;
我使用 Tarsos DSP 来确定声音的频率,即从麦克风输入的声音。它在大多数设备上都能完美运行,但其中一些设备会出错。
错误:
代码(第 1545-1547 行):
调度员是:
audio - 使用不同库的 mfcc 提取结果不同的原因
我找到了两个用于音频信号处理的库( librosa和tarsosDSP )。他们都有提取mfcc的方法。
在同一个.wav文件上运行一个简单的例子后,他们给出了完全不同的结果:

蓝色来自 librosa,橙色来自 tarsosDSP。橙色线几乎与y=x * -3/5蓝色线完全相同。
他们如此不同的原因是什么?我完全使用了示例代码,所以我认为原因不是我用不同的输入调用它们,而是它们如何在内部计算结果。
android - 如何在 android 中使用 MFCC TarsosDSP 和麦克风
在这个例子中(答案): 如何使用 TarsosDSP 获得 MFCC?
他们展示了如何在来自浮点数组的 android @Test 中使用 MFCC,我试图将它与来自麦克风的数据一起使用:
我想打印输出,但这没有打印任何东西,我无法调试它!我需要帮助。
编辑:
经过一番努力,我已将代码更改为:(但仍然无法正常工作)
编辑:完成:
java - 使用 TarsosDSP 将立体声转换为单声道不起作用
我想在声音数据上使用 TarsosDSP 的一些功能。传入的数据是Stereo,但是Tarsos确实只支持mono,所以我尝试将其转成mono如下,但是结果听起来还是觉得立体声数据被解释为mono,即转换viaMultichannelToMono似乎没有任何效果,虽然乍一看,它的实现看起来不错。
我在这里做错了什么吗?为什么MultichannelToMono处理器不将数据传输到单声道?
java - 如何从 TarsosDSP 获取音频频谱
我正在尝试从 Android 上的麦克风流中获取音频频谱。我正在使用 TarsosDSP 来完成繁重的工作。但似乎无法在流程事件中获得任何有意义的结果。我正在尝试获得 8 个频率并实时显示它们的幅度。我正在使用 SpectrumPeakAnalyser 类,但我不知道那是否适合使用。以下是流程事件的相关代码:
AudioDispatcher 调度程序 = AudioDispatcherFactory.FromDefaultMicrophone(SAMPLE_RATE, BUFFER_SIZE, OVERLAP); SpectralPeakFollower = new SpectralPeakProcessor(BUFFER_SIZE, OVERLAP, SAMPLE_RATE); dispatcher.AddAudioProcessor(spectralPeakFollower);
并且在进程事件中
我似乎找不到任何适合这种情况的例子,因为我不关心峰值,我只想要实时幅度。感谢您提供的任何帮助。
java - TarsosDSP:缓冲区太小应该至少为 7168 #151
虽然文档中写了常用的缓冲区大小为1024、2048;它并没有真正运行 1024 的大小;我收到错误消息:
缓冲区大小太小应至少为 7168
在调用以下内容时
请声明是否需要任何步骤来解决问题,我需要该大小以获得更精细的分辨率,同时对缓冲区数据进行一些处理。
android-studio - Android Studio 中的 TarsosDSP
这是我在 SO 上的第一篇文章,我正在尝试将我的音乐技能与计算机科学结合起来。
我正在使用带有 gradle 4.5、Nexus 5X、API 25、Android 7.1.1、Windows 7 的 Android Studio 3.1.2。
我非常小心地遵循了这些说明:
创建一个名为 Pitchbender 的项目
下载
/li>.jarTarsosDSP 并包含在我检查了
/li>build.gradle我的项目:在我的项目中,Android Studio自动完成了以下导入:
/li>我的清单文件中有此权限
/li>Android Studio提供了将以下代码的第一行转换为 Kotlin 的选项:
如果我对 Kotlin 转换响应“否”,则会出现以下编译错误:
分类器“AudioDispatcher”没有任何伴生对象,因此必须在这里初始化。
我能做些什么?
如果我对 Kotlin 转换问题回答“是”,则该语句将转换为
然后,当我运行这个程序时,Android 通知我有一个错误并关闭我的项目并继续关闭我的项目。该怎么办?
请帮助至少运行完整代码的第一条指令:
问题:
您在Android Studio中是否有任何简单的项目,以便我可以看到我的错误是什么?
java - 为什么 PitchDetection 更适用于吹口哨?
我正在玩 TarsosDSP 附带的 UtterAsterisk 示例程序。该程序的目标是显示指示用户应该做的笔记的水平条。垂直条从左向右移动,以向用户指示何时执行哪些音符的正确时间。用户获得积分取决于用户是否在正确的持续时间内做出了正确的笔记。
应用程序截图链接:https ://0110.be/files/photos/392/UtterAsterisk.png
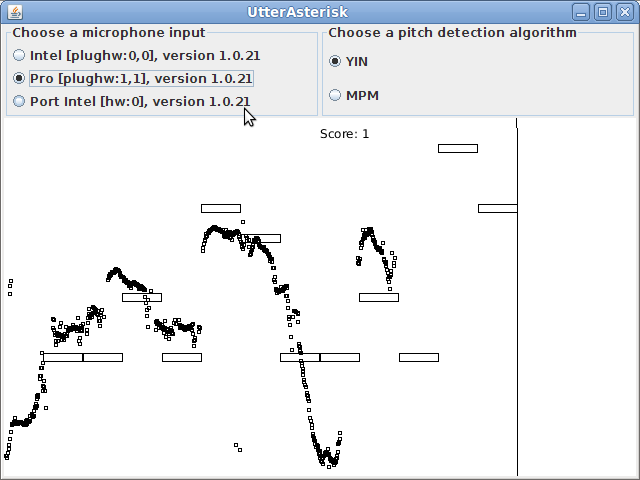{kind=link}
这个程序有3个部分:
- 选择音频输入
- 选择检测算法
- 预期笔记与实际产生的笔记的视觉表示:每 X 毫秒制作一个黑色小方块,代表用户所做的笔记。在本节的标题中(在程序的最新版本中),它说“吹口哨效果最好”。
我想知道为什么这段代码最适合吹口哨?
作为背景信息,我正在尝试为类似的程序制作一个快速原型,但用户会产生非口哨、非人声(无语音)的声音(如动物的声音),并且需要匹配以确保正确性。
我已经尝试吹口哨程序上指示的音符,它确实工作得很好(除了我不擅长吹口哨的事实!)。
我尝试选择不同的检测算法,但是当我发出非啸叫声时,声音发出的音符并不总是在第 3 部分中出现。
我有一种感觉,吹口哨会产生一个单一的音符,而发出嘎嘎声(像鸭子一样)实际上是一种谐波(希望我没听错:混合几个音符来产生声音)。
第 151、152 行:https ://github.com/JorenSix/TarsosDSP/blob/master/src/examples/be/tarsos/dsp/example/UtterAsterisk.java
我相信 PitchProcessor 只会处理一个峰值,因为它返回一个 pitchDetectionResult,它只包含一个频率(第 59 行): https ://github.com/JorenSix/TarsosDSP/blob/master/src/core/be/ tarsos/dsp/pitch/PitchDetectionResult.java
不幸的是,我主要是从数字信号处理领域开始的,并且可以使用一些帮助来了解在这个特定应用中如何更好地吹哨。如果我的直觉是正确的(吹口哨 = 单音),那么一个人怎么能做与这个程序相同的基本操作(将用户发出的动物声音与匹配的录音进行比较)?
谢谢您的意见!
java - Android,实时幅度和音高检测
我正在编写一个需要听麦克风并为我提供实时幅度和音高输出的应用程序。我已经弄清楚如何进行音高识别。我一直在对fft进行大量研究。发现 Android 库 TarsosDSP 使得监听音高变得非常简单:
我还想出了如何通过使用内置的 android .getMaxAmplitude() 方法来进行幅度检测。
但我的问题是,我一生都无法弄清楚如何同时做到这两点。问题是您显然可以运行多个麦克风实例。就像您尝试在单独的线程上运行两个单独的实时录制一样。我已经浏览了整个互联网,试图寻找一些示例代码来让我继续前进,但我找不到任何东西。有没有人不得不做类似的事情?
编辑 我发现您可以使用 Pitchdetectionhandler 中的 AudioEvent。audioevent.getbytebuffer() 根据文档返回一个字节数组,其中包含以字节为单位的音频数据:https ://0110.be/releases/TarsosDSP/TarsosDSP-latest/TarsosDSP-latest-Documentation/ 。
如果我在转换为短 [] 时没有弄错,那么最大值就是最高幅度,对吗?
但:
在这种情况下,amp 总是返回 127。而且这种方法不会真的在现场工作吗?
还有三个问题。我的基本想法是对的,如果是这样,为什么它总是返回 127,我将如何在实时环境中使用它。