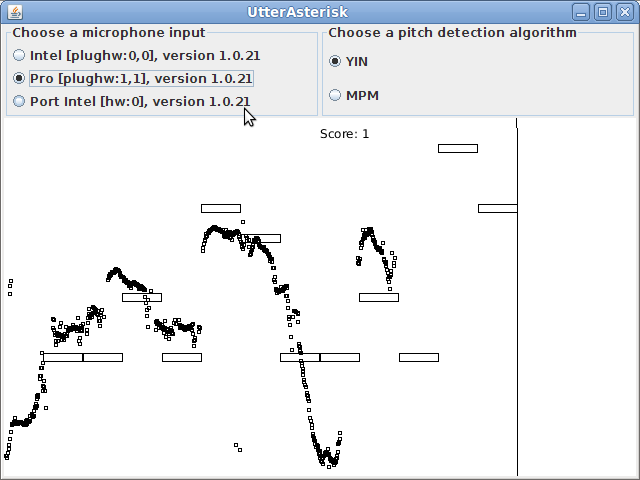
我正在玩 TarsosDSP 附带的 UtterAsterisk 示例程序。该程序的目标是显示指示用户应该做的笔记的水平条。垂直条从左向右移动,以向用户指示何时执行哪些音符的正确时间。用户获得积分取决于用户是否在正确的持续时间内做出了正确的笔记。
应用程序截图链接:https ://0110.be/files/photos/392/UtterAsterisk.png
{kind=link}
这个程序有3个部分:
- 选择音频输入
- 选择检测算法
- 预期笔记与实际产生的笔记的视觉表示:每 X 毫秒制作一个黑色小方块,代表用户所做的笔记。在本节的标题中(在程序的最新版本中),它说“吹口哨效果最好”。
我想知道为什么这段代码最适合吹口哨?
作为背景信息,我正在尝试为类似的程序制作一个快速原型,但用户会产生非口哨、非人声(无语音)的声音(如动物的声音),并且需要匹配以确保正确性。
我已经尝试吹口哨程序上指示的音符,它确实工作得很好(除了我不擅长吹口哨的事实!)。
我尝试选择不同的检测算法,但是当我发出非啸叫声时,声音发出的音符并不总是在第 3 部分中出现。
我有一种感觉,吹口哨会产生一个单一的音符,而发出嘎嘎声(像鸭子一样)实际上是一种谐波(希望我没听错:混合几个音符来产生声音)。
第 151、152 行:https ://github.com/JorenSix/TarsosDSP/blob/master/src/examples/be/tarsos/dsp/example/UtterAsterisk.java
// add a processor, handle percussion event.
dispatcher.addAudioProcessor(new PitchProcessor(algo, sampleRate, bufferSize, this));
我相信 PitchProcessor 只会处理一个峰值,因为它返回一个 pitchDetectionResult,它只包含一个频率(第 59 行): https ://github.com/JorenSix/TarsosDSP/blob/master/src/core/be/ tarsos/dsp/pitch/PitchDetectionResult.java
不幸的是,我主要是从数字信号处理领域开始的,并且可以使用一些帮助来了解在这个特定应用中如何更好地吹哨。如果我的直觉是正确的(吹口哨 = 单音),那么一个人怎么能做与这个程序相同的基本操作(将用户发出的动物声音与匹配的录音进行比较)?
谢谢您的意见!