问题标签 [statsd]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
graphite - 石墨 + statsd,缺少统计数据?
我们使用 statsd 作为聚合器,在 60 秒后转发到石墨。
我可以看到石墨填充“stats.timers”桶。但并非所有预期的。
在石墨机器上:
查看 statsd 源代码(https://github.com/etsy/statsd/blob/master/lib/process_metrics.js),我希望每次发生的事情都会出现以下指标(每个都作为自己的存储桶)。
资源:
任何人都知道为什么对于某些人我只得到“count_ps”而对于其他人我得到“upper”。石墨是否需要一些时间来处理其内部统计队列?
statsd 日志说大约 500 numstats / min 被发送:
任何帮助高度赞赏
干杯马塞尔
monitoring - Naming statsd metrics for short lived streams
I am trying to model statistics to submit to statsd/graphite. However what I am monitoring is "session" centric. For example, I have a game that is played in real time. There are multiple instances of a game active on the servers. Each game has multiple (and variable number of) participants. Each instance of a game has a unique ID as does each player. I want to track (and graph) each player's stats but then roll the metric up for the whole instance and then for all the instances of a game. For example there may be two instances of a game active at a given time. Lets say each has two players in the game
where game_instances and player_ids are 128 bit numbers
And I want to be able to see that the value of all voice errors for game_instance_a is 30 while all voice errors across the system is 150
Given this I have three questions
- What guidance would you have on naming the metrics.
- Is it kosher to have metrics that have "dynamic" identifiers as part of the name
- What are they scale limits on this. If I had a 100K game instances with say as many as 1000 players in a game, is this going to kill statsd/graphite?
Thanks!
node.js - Graphite 和 statsd,平均百分位数,stddev 不正确
由于 statsd 计算每个刷新间隔(默认为 10 秒)的统计信息,因此 Graphite 在查看更长的时间窗口时简单地平均这些似乎是不正确的。例如,statsd 发送 6 个刷新间隔的第 90 个百分位。如果我正在查看 1 分钟存储桶中的数据,Graphite 会对这些数据进行平均。仅取 6 个 10 秒百分位数的平均值来创建一分钟的第 90 个百分位数是不准确的。
这也是其他统计数据的问题:均值、中位数、标准差。对于 min/max/count,很容易设置 Graphite 存储聚合以正确聚合。但是对于统计数据是不正确的。
人们是如何处理这个问题的?
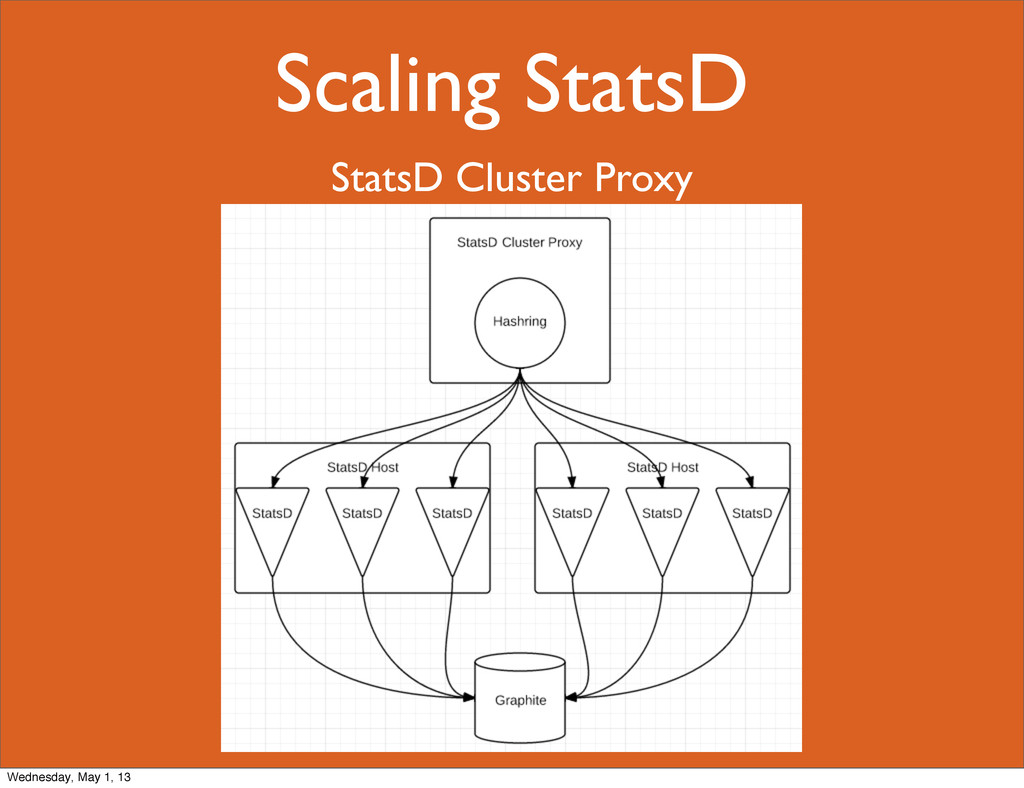
proxy - Statsd 集群代理
我正在尝试使用他们的集群代理设置一个 Statsd 集群。但我发现的只是他们的“官方”自述文件...... https://github.com/etsy/statsd/blob/master/docs/cluster_proxy.md
有人可以告诉我更多关于 statsd 服务器/实例集群的信息吗?
顺便说一句,演示文稿的这张幻灯片 ( https://speakerdeck.com/draco2003/measure-everything ) 是否正确?https://speakerd.s3.amazonaws.com/presentations/9afefbe094950130a5bd0ee022157b64/slide_21.jpg?1367417187
{kind=link}
以及如何将所有数据聚合到一个石墨中?
谢谢!
python - 用 Python 实现 StatsD/Graphite
所以我让 Etsy 的StatsD和 Graphite 在 OS X 10.9.3 上运行。
我现在正在尝试使用 Python 来实现它们,我不想使用python-statsd,因为我想在求助于库之前了解如何单独使用该技术(如果我需要使用 Ruby /PHP 稍后,然后我就不会理解基本机制)。
即我正在尝试使用 Python 将应用程序数据发送到 StatsD,然后将其显示在 Graphite 中。
在我的应用程序中,我使用的是 Steve Ivy 的python_example.py的精确副本。
在我的代码中,我这样调用增量函数:
这是引发的错误:
以下是发送内容的值udp_sock.sendto:
('somename.someval:1|c', ('localhost', 8125))
链接到我的代码:https ://github.com/bengrunfeld-wf/gae-github-console/blob/statsd/console/statsd.py
graphite - 碳继电器无法正常工作
我已经设置了 2 个真正的服务器。
一个 Statsite(StatsD 的替代品)位于一个“Graphite Stack”(Carbon 和 Graphite Webapp)前面。
通过 UDP 从 Statsite 正确收集指标。我只是每 10 秒将它们转发到碳缓存(碳中继的 TCP 端口 2013)。
在我的 Carbon 服务器上,3 个 carbon 缓存实例(a、b 和 c)在一个 carbon 中继(一致散列)后面运行。
我有 3 个缓存:[a, b, c] 部分,都在不同的端口上监听。中继部分,在目的地配置键中获得了这 3 个缓存实例。我已经通过 python 脚本启动了每个碳缓存,带有选项 --instance=[a, b, c] 并且我还使用自己的 python 脚本启动了 carbon-relay。我什至可以在中继日志中看到所有 3 个实例都已连接。
但是在我的 Graphite Webapp 中,我可以看到carbon.agents.XXXXX-[a, b, c].metricsCount所有 3 个实例的计数率都相同。
我想念 carbon relay 的 metrics 文件夹carbon.relay.XXXX.metricsCount。
我做的一切正确吗???
elasticsearch - 超过阈值后的电子邮件警报,logstash?
我正在使用logstash,elasticsearch并kibana分析我的日志。email当特定字符串通过logstash中的输出进入日志时,我会通过电子邮件发出警报:
这工作正常。
现在,我想提醒一个字段的计数(当超过阈值时):
例如,如果user是字段,我想在唯一用户数超过 5 时发出警报。
这可以通过emaillogstash中的输出来完成吗?
请帮忙。
编辑: 正如@Alcanzar 告诉我的那样:
配置文件:
所以根据上面,server2我abclog有一个 grok 模式来解析我的文件,并且在usergrok 解析的字段上,我希望应用度量标准。
我在上面的配置文件中这样做了,但是当我使用-vv.
因此,如果文件中有 9 条日志行,它首先解析 9 条,然后开始公制部分,但该message字段不是日志文件中的日志行,而是我的 PC 的用户名,因此它给出_grokparsefailure. 像这样的东西:
任何帮助表示赞赏。
node.js - TypeError:无法调用 null 的方法“插入”
我对 nodejs 很陌生,并且遇到了麻烦。我使用statsd收集统计数据,然后将它们发送到mongodb服务器进行存储,但是当我将statsd的计时器数据发送到mongodb时,我遇到了这个问题。
谁能告诉我如何解决这个问题,非常感谢!
java - 带有 Datadog 的 Kamon 抛出 java.lang.UnsupportedClassVersionError major/minor 51.0
我正在尝试使用 kamon 将数据发送到 datadog。我的设置如下:
我在 akka 启动时遇到以下异常:
graphite - Graphite 可以与非常偶尔的计数器一起使用吗?
使用statsd,配置flushInterval: 1000并与石墨的 carbon-cache通信。我希望我能看到非常偶然的柜台。
我有以下碳配置:
存储架构.conf:
以这种方式发送一个独特的计数器:
我可以看到statsd收到的数据包:
以及发送到 carbon-cache 的数据(tcpdump 提取):
在石墨中,查看“foobar”的数据,我可以看到那一刻发生了一些事情(细线,见图片中的红色圆圈),但结果始终为“0”:

我错过了什么吗?
如果有更频繁的结果,那么我可以看到看起来正确的数字。
是否有最低数量的统计数据需要考虑?是否可配置?
注意:也许对于这种偶尔的数据 StatsD / Graphite 是不值得的,但由于为同一个项目收集了其他非常频繁的数据,无论如何都会使用这些数据,并希望可以使用一个独特的解决方案,即使对于罕见的计数器。