问题标签 [parsey-mcparseface]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
nlp - 法律文本的 NLP?
我有一个包含几十万份法律文件(主要来自欧盟)的语料库——法律、评论、法庭文件等。我试图通过算法来理解它们。
我已经模拟了已知的关系(时间、this-changes-that 等)。但在单文档级别,我希望我有更好的工具来快速理解。我对想法持开放态度,但这里有一个更具体的问题:
例如:是否有 NLP 方法来确定文档的相关/有争议的部分,而不是样板文件?最近泄露的TTIP论文有数千页的数据表,但其中某处的一句话可能会摧毁一个行业。
过去我玩过 google 的新Parsey McParfaceNLP 和其他 NLP 解决方案,但虽然它们工作得非常好,但我不确定它们在隔离意义方面有多好。
nlp - 如何从 Parsey McParseface 获取基于选区的解析树
Parsey McParsey 默认返回一个基于依赖的解析树,但他们是一种从中获取基于选区的解析树的方法吗?
编辑:为了澄清,“从中获得”我的意思是从 Parsey 本身。尽管从 ConLL 输出构建树也是一种选择。
pos-tagger - Parsey McParseface 中使用了 POS 标签和依赖标签集的定义?
输出的 POS 标签和依赖标签分别在此处的和文件Parsey McParseface中给出。tag-setlabel-set
自述文件概述了该Syntaxnet模型是在 Penn Treebank、OntoNotes 和 English Web Treebanks 上训练的。
这些树库中使用的相应 POS 标签和依赖标签是否有与Universal Dependency 项目给出的类似的详细描述?
tensorflow - 是否可以导出语法网络模型(Parsey McParseface)以与 TensorFlow Serving 一起服务?
我的 demo.sh 工作正常,我查看了 parser_eval.py 并在某种程度上理解了它。但是,我看不到如何使用 TensorFlow Serving 来服务这个模型。我可以从顶部看到两个问题:
1) 这些图没有导出模型,在每次调用时使用图构建器(例如,structured_graph_builder.py)、上下文协议缓冲区和一大堆其他我不完全理解的东西来构建图(它似乎也注册了额外的 syntaxnet.ops )。那么......是否有可能,我将如何将这些模型导出到 Serving 和所需的“捆绑”形式中SessionBundleFactory?如果不是,则似乎需要在 C++ 中重新实现图形构建逻辑/步骤,因为 Serving 仅在 C++ 上下文中运行。
2) demo.sh 实际上是两个模型,实际上是与 UNIX 管道一起通过管道传输的,因此任何 Servable 都必须(可能)构建两个会话并将数据从一个会话编组到另一个。这是一个正确的方法吗?或者是否可以构建一个“大”图,其中包含“修补”在一起的两个模型并将其导出?
python - 使用 SyntexNet Parsey McParseface 创建训练语料库
我目前正在尝试学习 Tensorflow,并且已经到了需要创建一些语料库数据集的地步。我没有钱在 LDC 购买带注释的 Gigaword 英语语料库,所以我正在考虑创建自己的爬虫。我从网上得到了一些文章,但现在想以类似于 LDC Gigaword 示例的方式格式化它们:https ://catalog.ldc.upenn.edu/desc/addenda/LDC2012T21.jpg
{kind=link}
我正在尝试使用 Parsey Mcparseface 模型对我的输入进行 POS 标记并帮助我输出多个 xml 文件。我目前已经接近了我想要的输出,方法是使用 python 修改 conll2tree.py 文件和 demo.sh 文件,以允许我从单个文件中读取我的输入。使用的命令行显示在这篇文章的底部。
我想弄清楚的是如何让模型处理目录中的所有文件。我当前的爬虫是用 JavaScript 编写的,并输出单独的 .json 文件,其中包含带有标题、正文、图像等的 json 对象。我使用句子边界检测来用逗号分隔每个句子,但似乎我对 parsey 的输入需要作为每个句子在不同行上的输入。我将在我的 python 脚本中修改它,但我仍然不知道如何配置下面的参数,以便我可以让它遍历每个文件,读入内容,处理并继续下一个文件。有没有办法为输入参数设置通配符?或者我是否需要在我的 python 脚本中通过命令行单独发送每个文件?我只是假设 parsey 模型或者 SyntexNet 是否可以批量处理它们,
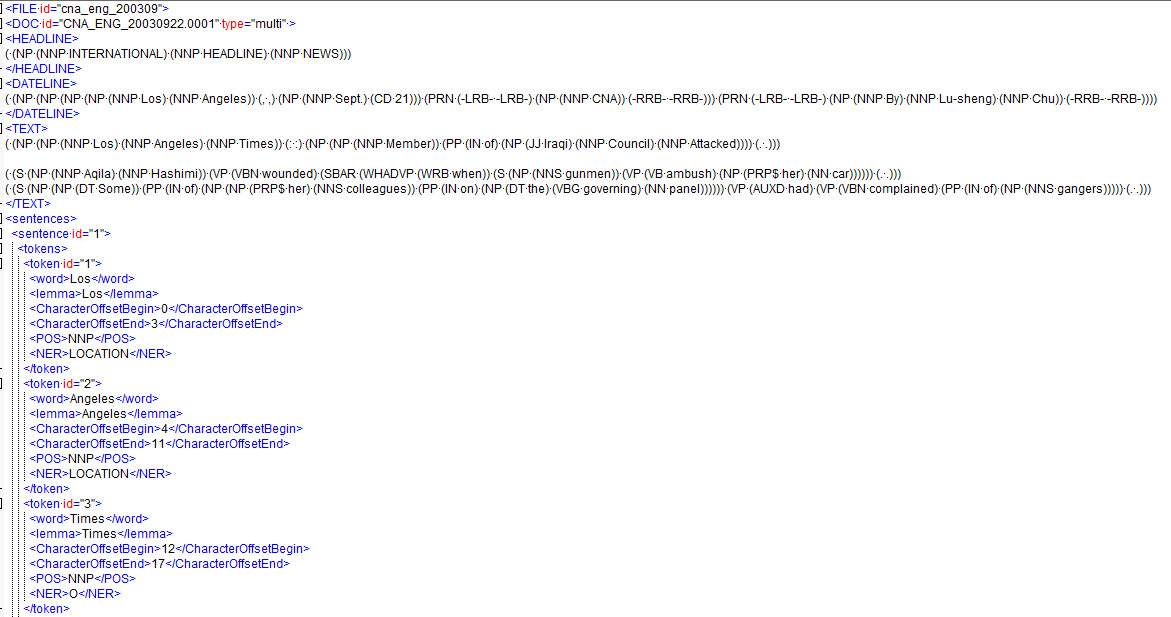
我遇到的另一个问题是,是否有办法让 Parsey Mcparseface 输出如上图“标题”所示的格式,如下所示:
(.(NP.(NNP.INTERNATIONAL).(NNP.HEADLINE).(NNP.NEWS)))
如果不是,这种格式叫什么,所以我可以更多地研究如何通过自己的代码来做这件事?让我失望的部分是 NP 的前缀数字(假设名词短语)。
我已经设法将 POS 标签提取成类似于通过句子标记显示的图像中的格式,但我假设随着我对 Tensorflow 的深入了解,拥有它们显示的格式会很好标题和文本字段标签也是如此,因为它显示了单词之间的更多关系。
我还在 content.pbtxt 文件中添加了以下条目:
tensorflow - Parsey McParseface 重新训练模型
有没有办法通过为现有模型提供更多的训练数据来增强谷歌的依赖解析器Parsey ?
nlp - Parsey McParseface 错误地识别问题的根源
在我看来,Parsey 在正确标记问题和任何带有“is”的句子方面存在严重问题。
文本:巴拉克奥巴马是夏威夷人吗?
GCloud 代币(正确):
- 是 - [根] 动词
- 兵营 - [nn] 名词
- 奥巴马 - [nsubj] 名词
- 来自 - [adp] 准备
- 夏威夷 - [pobj] 名词
Parsey 令牌(错误):
- 是 - [警察] 动词
- 兵营 - [nsubj] 名词
- Obama - [词根] 名词
- 来自 - [adp] 准备
- 夏威夷 - [pobj] 名词
Parsey 决定将名词 (!) Obama 设为词根,这将其他一切都搞砸了。
文字:我的名字是菲利普
GCloud 代币(正确):
- 我的 [poss] 代号
- 名称 [nsubj] 名词
- 是 [根] 动词
- Philipp [attr] 名词
ParseyTokens(不正确):
- 我的 [poss] 代号
- 名称 [nsubj] 名词
- 是 [警察] 动词
- Philipp [词根] 名词
parsey 再次选择名词作为词根并与 COP 斗争。
任何想法为什么会发生这种情况以及我该如何解决?
谢谢,菲尔
nlp - 如何将训练数据添加到开箱即用的 Parsey McParseFace 模型
我想知道,如果可能的话,如何训练一个新的 SyntaxNet 模型,该模型使用来自 github 页面上原始的、开箱即用的“准备解析”模型的训练数据。我想做的是添加新的训练数据来制作一个新模型,但我不想制作一个全新的、因此与原始 Parsey McParseFace 完全不同的模型。因此,我的新模型将使用包含模型的训练数据(Penn Treebank、OntoNotes、English Web Treebank)以及我的新数据进行训练。我没有钱从 LDC 购买用于训练原始模型的树库。有没有人尝试过这个?非常感谢。
syntaxnet - Parsey mcparseface:如何获取句子中单词的位置以及解析树
我正在使用 parsey mcparseface 和 syntaxnet 来解析一些文本。我希望提取单词的位置数据以及解析树。
目前的输出是:
我需要怎样
或类似的。(当同一个词出现很多次时,这将特别有用。)
谢谢
python - Syntaxnet / Parsey McParseface python API
我已经安装了 syntaxnet,并且能够使用提供的演示脚本运行解析器。理想情况下,我想直接从 python 运行它。我发现的唯一代码是:
这是一场彻底的灾难——效率低下且过于复杂(从 python 调用 python 应该用 python 完成)。
我怎样才能直接调用 python API,而不通过 shell 脚本、标准 I/O 等?
编辑 -为什么这不像打开 syntaxnet/demo.sh 并阅读它那么容易?
这个 shell 脚本调用了两个 python 脚本(parser_eval 和 conll2tree),它们被编写为 python 脚本,并且不能导入到 python 模块中而不会导致多个错误。仔细观察会产生额外的类似脚本的层和本机代码。为了在 python 上下文中运行整个事情,需要重构这些上层。没有人对语法网进行这样的修改或打算这样做吗?