问题标签 [omap]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
embedded - 晶核 MPU 时钟频率差异
我有一个嵌入式系统,启动时显示如下:
时钟频率(Crystal/Core/MPU):12.0/400/1000 MHz
谁能解释一下这三个时钟频率之间的差异。处理器为 ARMv7、OMAP3xxx
c++ - 为使用 PowerVR 的 Omap4 开发 EGL 应用程序
我有 Pandaboard,我在 OMAP4 上处理 PowerVR 支持,我已经成功地尝试了 Imagination Examples。但我想知道,如何在我的主机上将我自己的代码和开发应用程序编写到 Pandaboard 或 Omap4 上,这样交叉编译?
解决方案是PowerVR SDK吗?又怎样?
注意:Ubuntu 11.10 在 Pandaboard(armhf) 上运行。Ubuntu 12.04 在 HostMachine(x86) 上运行
arm - 在 OMAP 4460 上进行多个 DMA 传输时 CPU 是否被阻塞?
我想知道 DMA 在 Pandaboard 中的工作原理。我已经阅读了 Pandaboard 中使用的 OMPA4460 的 TRM,DMA 系统一次可以管理总共 128 个请求,最多 32 个逻辑通道和 4 个中断请求。当 DMA 正在进行时,CPU 是否有机会一次执行另一个任务?
arm - 由 ARM Cortex-A9 制成的 SoC 的典型 L1 和 L2 访问延迟
我正在寻找由 ARM Cortex-A9 处理器(例如具有多个 ARM A9 处理器的 Nvidia Tegra 2 和 Tegra 3)制成的 SoC 的 L1 访问延迟和 L2 访问延迟。
我可以找到有关这些架构的 L1 和 L2 大小的一些信息,但我找不到有关 L1 和 L2 访问延迟的太多信息。我发现的唯一可靠信息是“在 Tegra 3 上,L2 缓存延迟比 2 快 2 个周期,而 L1 缓存延迟没有改变。”
这里提到 Tegra 2 上的 L2 有 25 个周期的延迟,这里提到 L1 有 4 个周期的延迟,L2 有 31 到 55 个周期的延迟。这些参考资料都不是完全可靠的。我希望在 Nvidia、TI 和 Qualcomm 网站和技术文档上找到更多信息,但没有成功。
编辑:OMAP4460 和 OMAP4470 等类似 SoC 的信息也会很棒。
spi - 我应该使用哪些 OMAP-L138 寄存器来选择另一个 SPI 芯片?
我有 OMAP-L138 Experimenter Kit,我想与设置在 SPI 1 芯片选择 1 上的外围设备之一进行通信(SPI1 芯片选择 0 上也有闪存)。
我很困惑我应该使用哪些寄存器来选择芯片 1 ?
根据OMAP-L138 Technical Reference Manual,我应该
设置 4 针模式
spi->SPIPC0 = SOMI | 西莫 | 时钟 | SCS0; //带片选的4针模式
设置 SPIPC0.SCS0FUN 的 1 位以显示 SPI_CS1 - 是 SPI 功能引脚
SETBIT(spi->SPIPC0, 0x00000002);
设置 SPIDAT1.CSNR 的 17 位(表示 SPI_CS1 引脚被驱动为高电平。)
SPI->SPIDAT1 = 0;SETBIT(spi->SPIDAT1, 0x20000); //设置第17位(对应SPI_CS1)
将 SIDEF.CSDEF 设置为 1 位(表示 SPI_CS1 引脚被驱动为高电平。)
spi->SPIDEF = 0;SETBIT(spi->SPIDEF, 0x00000002); //在 CSDEF 字段中设置第 1 位(对应于 SPI_CS1)
最后,在从 SPI1_CS1 设备读取数据之前,我应该将 SPIDAT1.CSHOLD 设置为保持有效的片选信号
SETBIT(spi->SPIDAT1,0x10000000); //设置代表CSHOLD的第28位
这是正确的还是我错过了什么?可能我还需要对 PINMUX5(引脚复用控制 5 寄存器)做一些事情吗?谢谢!
linux-kernel - 内核哎呀哎呀:ARM嵌入式系统上的80000005
请帮我解决这个问题。我使用了一个 1 毫秒的高分辨率计时器并将其安装为带有“insmod”的单独模块。这每 1 毫秒触发一次,我必须用这个定时器中断做一些任务。还有其他进行图像传输的进程,我看到以太网驱动程序中断出现以发送图像。这个enet中断有一些高优先级,看起来它正在延迟上面的1 ms定时器中断,但我不确定。
在运行测试 3 到 3 小时后,我看到了下面的 Oops。如何从根本上解决这个问题?请帮忙。系统为ARM omap,运行Linux 2.6.33 交叉编译。
==========================================
=========================
我用上面的代码作为驱动模块,用insmod插入。我希望它每 1 毫秒触发一次,它工作正常,但有时当以太网流量太高时,它会给出一个内核糟糕的解释。请检查代码是否有任何问题?
我检查了 lsmod,我看到所有 5 个内核模块(我自己的)都加载在:0x7f000000 到 0x7f02xxxx 之间
在 oops 地址 0x7eb52754 处未加载任何模块。我从 /proc/kallsyms 文件中检查以验证这一点。如何检查 0x7eb5xxxx 到源文件的映射?我还能在哪里获得系统上的数据。
embedded - 配置 minicom 以使用硬件流控制
寻找一些帮助来测试具有OMAP L138的硬件流控制的 UART 实现。为了测试我minicom用来模拟串行链路另一端的实现,我正在寻找一些关于如何配置它的见解。
我有一个简单的应用程序,它通过 UART 将消息从 OMAP 发送到 minicom。如果 OMAP 和 minicom 都配置为不使用硬件流控制,这将按预期工作。当我打开硬件流控制时,我在 minicom 上看不到任何输出。
这是我遵循的步骤列表:
- 配置 minicom 使用硬件流控(Ctl AO 打开 minicom 串口设置菜单,F 启用硬件流控)。
- 使用
stty我启用 rts/cts 握手stty -F /dev/ttyS1 crtscts。使用命令stty -F /dev/ttyS1 -a我可以确认 crtscts 已启用。
上述两项更改确保在终端程序和 UART 驱动程序中启用硬件流控制。OMAP 上的 UART 也已配置为使用硬件流控制。
但是,上面列出的对 minicom 的更改似乎不足以使流量控制正常工作。启动应用程序后,来自 OMAP 的 RTS(请求发送)信号变低,向 minicom 指示它要发送数据。如果配置正确,minicom 应该将 OMAP 的 CTS(清除发送)信号拉低并开始接受数据,直到达到指定的接收缓冲区阈值。这不会发生。OMAP 的 CTS 输入始终为高电平。只是为了好玩,我尝试在 OMAP 上将 RTS 短接到 CTS,瞧,预期的消息确实出现在 minicom 上!这是一张显示两者如何连接的图像。

从我的尝试来看,我在配置 minicom 的方式上似乎遗漏了一些东西。任何建议表示赞赏。
android - 如何在 Pandaboard 上更改 Android 的分辨率?
我正在从针对 Pandaboard ES 的 AOSP 构建 Android 4.2.1,我必须将 HDMI 输出上的物理显示分辨率从 1920x1080 更改为 800x600。
我尝试将 , 或 附加omapfb.mode=hdmi:800x600@60到omapfb.mode=800x600@60由video=omapfb:mode:800x600@60OMAP内核源CONFIG_CMDLINE生成的 .config 中make panda_defconfig,但每次 adb 似乎不再识别该设备,并且它在启动后立即从“lsusb”命令中消失。
谢谢你。
linux-kernel - 嵌入式:OMAP3 EVM 引导参数
我是初学者。我正在使用OMAP3 EVM. 目前,我可以通过NFS. 但是,我希望它来自SD card. 我boot.scr在将其更改为 SD 启动时删除了该文件。它正在正确启动。但是,在该行之后,'Uncompressing Linux...'它会等待一段时间,然后直接加载文件系统并要求登录。过去在该行之后的这么多行初始化日志'Uncompressing Linux...'完全丢失了。但是,根文件系统已完全加载,我可以像以前一样使用它。因此,我尝试通过单独删除与 nfs 相关的参数来制作 boot.scr 文件。
之前的boot.scr命令,
现在的boot.scr命令,
我没有修改uEnv.txt. 它的内容是,
现在,它已经完全停止在该行之后启动'Uncompressing Linux...'。请指导我哪里出错了。
beagleboard - BeagleBone GPIO 输出同步与 PRU (TI AM335x)
我正在使用 AM335x 上的一个 PRU 单元来驱动 BeagleBone 上的 4 个 GPIO 引脚(GPIO1_2、GPIO1_3、GPIO1_6、GPIO1_7),并且我想同步边缘转换(我的完整源代码在底部)。
使用 Beaglebone 将引脚上的输出设置为 HI,将地址 0x4804c194 处的相应位设置为 1,然后将其设置为 LO,将地址 0x4804c190 处的位设置为 1。所以我的 PRU 汇编代码首先设置输出 HI 位,然后设置输出 LO 位:
由于运行每个周期需要多少个周期,LO 周期明显长于 HI(50ns 对 110ns)。不幸的是,我太新了,无法发布图片,这是上一个代码中逻辑分析仪屏幕截图的链接
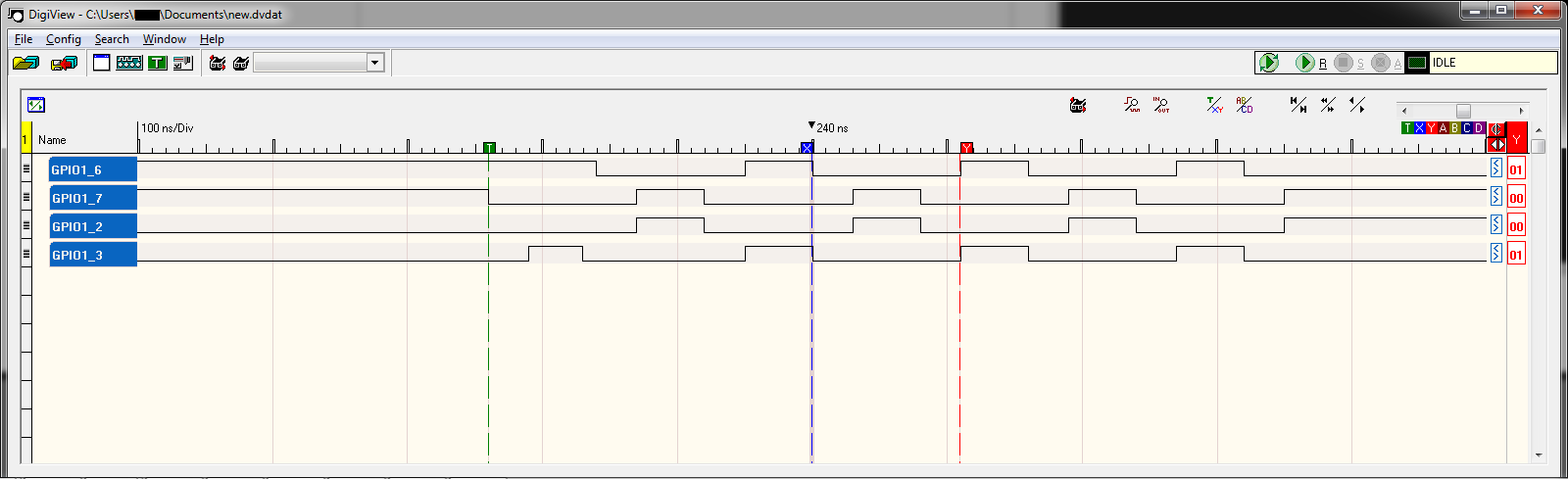{kind=link}
为了均匀超时,我交替设置 HI 和 LO 位,使周期相等,为 80ns,但 HI 和 LO 转换相互偏移 80ns:
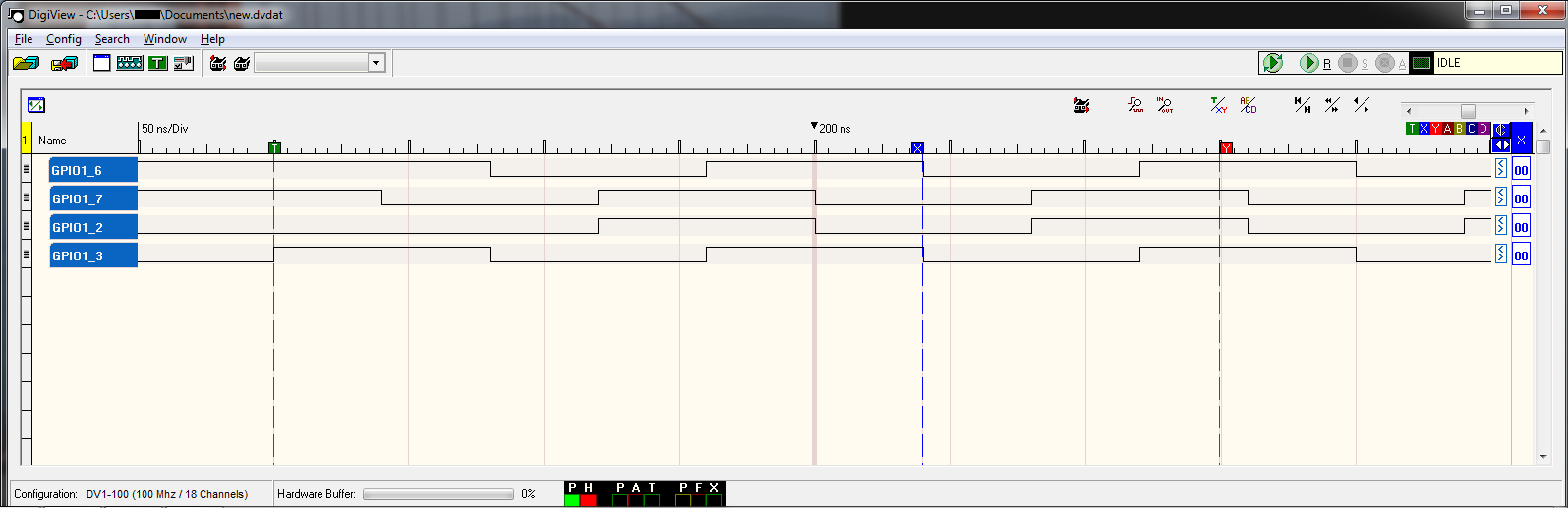{kind=link}
所以我的问题是如何让边缘转换同时发生?即,如果您比较 GPIO1_6 和 GPIO_7,屏幕截图的中心是 200ns,此时 GPIO1_7 转换为 LO,然后 50ns 之前,GPIO1_6 转换为 HI,我希望它们同时转换。我不介意放慢速度来实现这一点。
这是我的源代码:
文件:main.p
文件 main.c:
文件 main.hp: