问题标签 [mobilenet]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
android - 浮动对象检测模型的变量的输入和输出形式应该是什么
https://storage.googleapis.com/download.tensorflow.org/models/tflite/mobilenet_ssd_tflite_v1.zip
我正在制作一个支持 gpu 委托的 android 对象检测应用程序。上面的链接是针对 tensorflow lite 对象检测浮点模型的。没有可用的文档。我想知道这个 tflite 模型的变量的输入和输出形式,以便我可以将它提供给解释器以进行 gpu 委托。提前致谢!
tensorflow - 使用自定义数据集量化大小问题训练的 mobilenetv1
我正在开发一个对象检测软件,基本上我在 Python 上使用带有 MobileNetV1 的 TensorFlow 对象检测 API,我已经用我自己的数据集训练了模型。
用我的数据集训练得到的 freeze_inference_graph.pb 文件就像 22 Mo。
我尝试通过量化将其转换为 TFLite,但它仍然像 21.2 Mo。
这两个尺寸都是 20+ Mo 正常吗?我从不同的来源了解到 MobileNet 量化模型大约是 5 Mo。这是因为我在自定义数据集上使用新对象对其进行了训练?而且,为什么量化它不会减小大小(最多小 4 倍)?
谢谢您的帮助
python - Tensorflow:尝试迁移学习时出错:JPEG 数据或裁剪窗口无效
我正在尝试使用他们在此处的教程将我自己的自定义图像数据集塑造成 Tensorflow 上预训练 MobileNet 模型的正确输入形状。我的代码:
之后我继续阅读关于迁移学习的 TF教程。但是,我遇到了这个问题,我怀疑 JPEG 图像已损坏或迭代器缺少/问题?:
感谢您的时间!编辑:重新运行代码几次后,它似乎会产生不同数据大小的相同错误,如 16384....
编辑:是的,问题在于某些 .jpeg 实际上是 .png 伪装的,或者它们只是完全损坏了。我强烈建议在使用数据训练任何模型之前检查数据完整性。
deep-learning - 人脸识别:验证准确率高,但在实时人脸识别上表现很差
我正在制作一个使用 Mobilenet 进行人脸识别的 CNN 模型。在训练时,我得到了高达 90% 的 val_acc,但是当我在来自网络摄像头的真实视频或一些测试视频上对其进行测试时,模型表现不佳。可能的原因是什么?我使用了没有顶层的 MobileNet,并在其中添加了我自己的 FC 层。然后我开始训练模型。
tensorflow - MobileNetV2 在 TF 2.2 上的预处理不一致
在本分割教程中,预处理将图像值标准化为[0, 1].
但是,根据 MobileNetV2 的文档(https://www.tensorflow.org/api_docs/python/tf/keras/applications/mobilenet_v2/preprocess_input),预处理步骤将数据标准化为区间[-1, 1]。
哪种预处理是正确的,为什么?
python - 加载后更改 MobileNet Dropout
我正在解决迁移学习问题。当我仅从 Mobilenet 创建一个新模型时,我设置了一个 dropout。
我在训练时使用model_checkpoint_callback. 当我训练时,我会发现过度拟合发生的地方,并调整冻结层的数量和学习率。当我再次保存加载的模型时,我还可以调整 dropout 吗?
我看到了这个答案,但是 Mobilenet 中没有实际的 dropout 层,所以这个
不做任何事情。
tensorflow - TensorFlow 迁移学习 ValueError
我正在尝试迁移学习,在图像分类问题上,在谷歌 colab 上,当我运行这段代码时:
我收到了这个错误:
我尝试安装 tf-nightly 和旧版本的 tensorflow 以查看它是否会运行,但这不起作用。我还尝试了旧版本的 tensorflow_hub,这也导致了更多错误。我试图将笔记本恢复出厂设置并重试,但我得到了同样的错误。如果我注释掉,错误不会出现model.build(INPUT_SHAPE)。除此之外,我不确定如何解决该问题。
tensorflow - SSD Mobilenet 输入图像大小
我想在自定义数据集上使用 Mobilenet SSD 模型训练对象检测器。
查看 Mobilenet 的配置文件,有一个名为 image_resizer{} 的块,我认为默认为 300x300,但我可用的图像为 224x224。
我可以在不更改配置文件的情况下进行培训,还是真的需要将其更改为 224x224 以匹配我的图像?
在这里找到配置文件。
tensorflow - 尝试使用 40x40px 图像自定义训练 MobilenetV2 - 训练后结果错误
我需要对 4 个不同类别的小图像进行分类,+1“背景”用于错误检测。
虽然训练损失迅速下降到 0.7,但即使在 800k 步后仍保持在那里。最后,冻结图似乎用背景标签对大多数图像进行了分类。
我可能遗漏了一些东西,我将在下面详细说明我使用的步骤,欢迎任何反馈。我是 tf-slim 的新手,所以这可能是一个明显的错误,也许样本太少了?我不是在寻找最高的准确性,只是为了原型设计。
源材料可以在这里找到:https ://www.dropbox.com/s/k55xoygdzb2efag/TilesDataset.zip?dl=0
我在 Windows 10 上使用了 tensorflow-gpu 1.15.3。
我使用以下方法创建了数据集:
python ./createTfRecords.py --tfrecord_filename=tilesV2_40 --dataset_dir=.\tilesV2\Tiles_40我在 models-master\research\slim\datasets 基于鲜花提供者添加了一个数据集提供者。
我修改了 models-master\research\slim\nets\mobilenet 中的 mobilnet_v2.py,更改了num_classes=5和mobilenet.default_image_size = 40
我用以下方法训练了网络:
python ./models-master/research/slim/train_image_classifier.py --model_name "mobilenet_v2" --learning_rate 0.045 --preprocessing_name "inception_v2" --label_smoothing 0.1 --moving_average_decay 0.9999 --batch_size 96 --learning_rate_decay_factor 0.98 --num_epochs_per_decay 2.5 --train_dir ./weight --dataset_name Tiles_40 --dataset_dir .\tilesV2\Tiles_40当我尝试这个时,
python .\models-master\research\slim\eval_image_classifier.py --alsologtostderr --checkpoint_path ./weight/model.ckpt-XXX --dataset_dir ./tilesV2/Tiles_40 --dataset_name Tiles_40 --dataset_split_name validation --model_name mobilenet_v2我得到eval/Recall_5[1]eval/Accuracy[1]然后我导出图表
python .\models-master\research\slim\export_inference_graph.py --alsologtostderr --model_name mobilenet_v2 --image_size 40 --output_file .\export\output.pb --dataset_name Tiles_40把它冷冻起来
freeze_graph --input_graph .\export\output.pb --input_checkpoint .\weight\model.ckpt-XXX --input_binary true --output_graph .\export\frozen.pb --output_node_names MobilenetV2/Predictions/Reshape_1然后我尝试使用来自数据集的图像的网络
python .\label_image.py --graph .\export\frozen.pb --labels .\tilesV2\Tiles_40\labels.txt --image .\tilesV2\Tiles_40\photos\lac\1_1.png --input_layer input --output_layer MobilenetV2/Predictions/Reshape_1。这是我得到错误分类的地方。,例如0:background 0.92839915 2:lac 0.020171663 1:house 0.019106707 3:road 0.01677236 4:start 0.0155500565数据集的“lac”图像
我尝试更改 depth_multiplier、学习率、在 cpu 上学习、--preprocessing_name "inception_v2"从学习命令中删除。我一点头绪都没有...
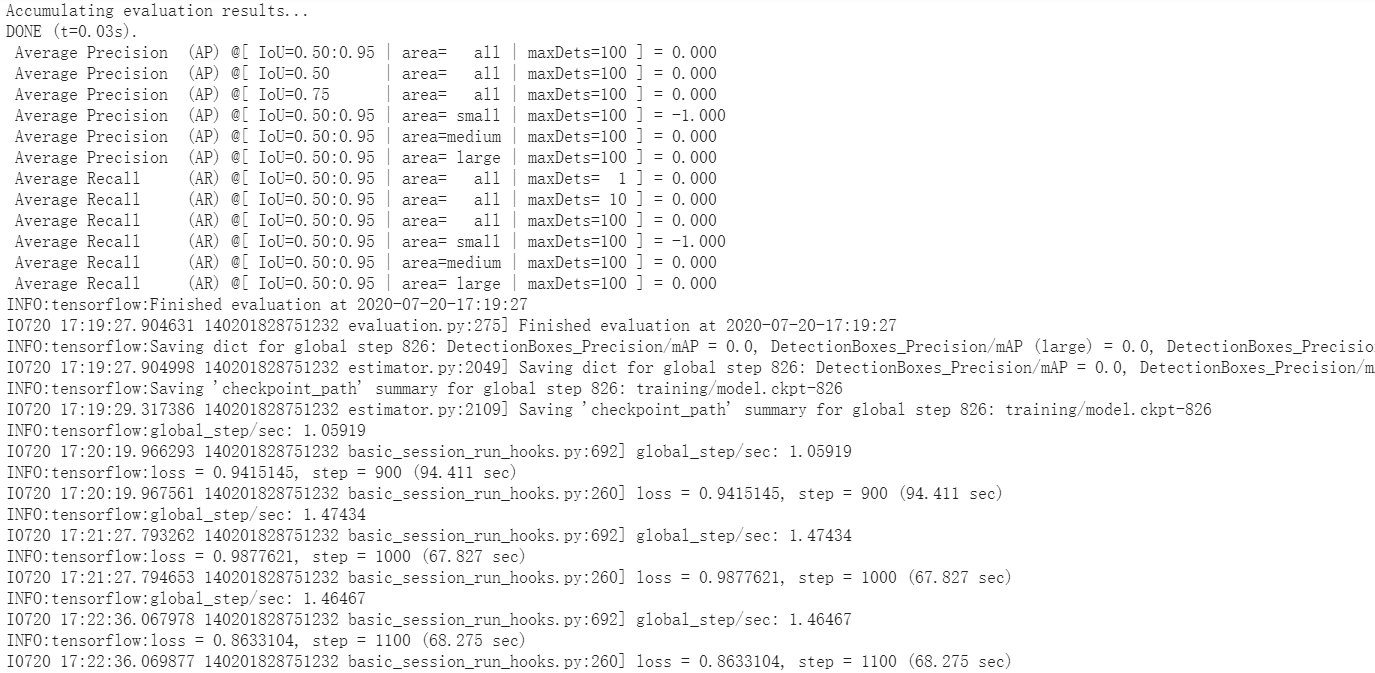
object-detection - 为什么我的目标检测训练损失非常低(<1),但精度仍然为 0?
我正在使用 colab 来训练对象检测模型,请查看colab。但是我发现loss很低,presion还是0,怎么回事?