问题标签 [infobright]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
mysql - 用于分析的数据库
我正在建立一个大型数据库,它将根据传入的数据生成统计报告。
该系统的大部分操作如下:
- 每天早上将上传大约 400k-500k 行 - 大约 30 列,主要是 varchar(5-30) 和 datetime。它在平面文件形式时大约为 60MB,但在添加了合适的索引后在数据库中急剧增长。
- 将从当天的数据生成各种统计数据。
- 将生成并存储来自这些统计数据的报告。
- 当前数据集将被复制到分区历史表中。
- 在一天中,最终用户可以查询当前数据集(被复制,而不是移动),以获取不太可能包括常量但字段之间关系的信息。
- 用户可以从历史表中请求专门的搜索,但查询将由 DBA 制作。
- 在第二天的上传之前,当前数据表被截断。
这基本上是我们现有系统的第 2 版。
现在,我们正在使用 MySQL 5.0 MyISAM 表(Innodb 仅在空间使用上就被扼杀了)并且在 #6 和 #4 上遭受了很大的痛苦。#4 目前不是分区表,因为 5.0 不支持它。为了避免将记录插入历史记录所花费的大量时间(数小时和数小时),我们每天都将写入一个未索引的 history_queue 表,然后在我们最慢的时间的周末将队列写入历史表。问题是一周内生成的任何历史查询都可能晚几天。我们无法减少历史表上的索引,否则它的查询将变得不可用。
对于下一个版本,我们肯定会至少迁移到 MySQL 5.1(如果我们继续使用 MySQL),但强烈考虑使用 PostgreSQL。我知道辩论已经进行到死,但我想知道是否有人对这种情况有任何建议。大多数研究都围绕网站使用展开。索引确实是我们使用 MySQL 的主要优势,似乎 PostgreSQL 可以通过部分索引和基于函数的索引来帮助我们。
我已经阅读了数十篇关于两者之间差异的文章,但大多数都是旧的。PostgreSQL 长期以来一直被贴上“更高级但更慢”的标签 - 将 MySQL 5.1 与 PostgreSQL 8.3 进行比较还是普遍情况还是现在更平衡?
商业数据库(Oracle 和 MS SQL)根本不是一种选择——尽管我希望 Oracle 是。
对我们来说 MyISAM 与 Innodb 的注意事项:我们正在运行 Innodb,对我们来说,我们发现它慢得多,比如慢 3-4 倍。但是,我们对 MySQL 也较新,坦率地说,我不确定我们是否为 Innodb 适当调整了 db。
我们在正常运行时间非常长的环境中运行 - 电池备份、故障转移网络连接、备用发电机、完全冗余系统等。因此,MyISAM 的完整性问题被权衡并被认为是可以接受的。
关于 5.1:我听说过 5.1 的稳定性问题。一般来说,我认为任何最近(过去 12 个月内)的软件都不是坚如磐石的稳定。考虑到重新设计项目的机会,5.1 中的更新功能集实在是太多了,不容错过。
关于 PostgreSQL 陷阱:没有任何 where 子句的 COUNT(*) 对我们来说是非常罕见的情况。我不认为这是一个问题。COPY FROM 不如 LOAD DATA INFILE 灵活,但中间加载表可以解决这个问题。我最担心的是缺少 INSERT IGNORE。我们在构建一些处理表时经常使用它,这样我们就可以避免将多条记录放入两次,然后不得不在最后做一个巨大的 GROUP BY 来删除一些重复。我认为它的使用频率很低,以至于缺乏它是可以容忍的。
hadoop - 免费数据仓库——Infobright、Hadoop/Hive 还是什么?
我需要存储大量的小数据对象(每月数百万行)。一旦他们被保存,他们就不会改变。我需要 :
- 安全地存放它们
- 使用它们进行分析(主要是面向时间的)
- 偶尔检索一些原始数据
- 如果它可以与 JasperReports 或 BIRT 一起使用就好了
我的第一个镜头是 Infobright Community - 只是 MySQL 的一个面向列的只读存储机制
另一方面,人们说 NoSQL 方法可能会更好。Hadoop+Hive 看起来很有希望,但文档看起来很差,版本号小于 1.0 。
我听说过 Hypertable、Pentaho、MongoDB ......
你有什么建议 ?
(是的,我在这里找到了一些主题,但那是一两年前的事了)
编辑:其他解决方案:MonetDB、InfiniDB、LucidDB - 你怎么看?
data-warehouse - 数据仓库中的时间和日期维度
我正在建立一个数据仓库。每个事实都有它的timestamp。我需要按天、月、季度但也按小时创建报告。查看示例,我发现日期倾向于保存在维度表中。(来源:etl-tools.info)
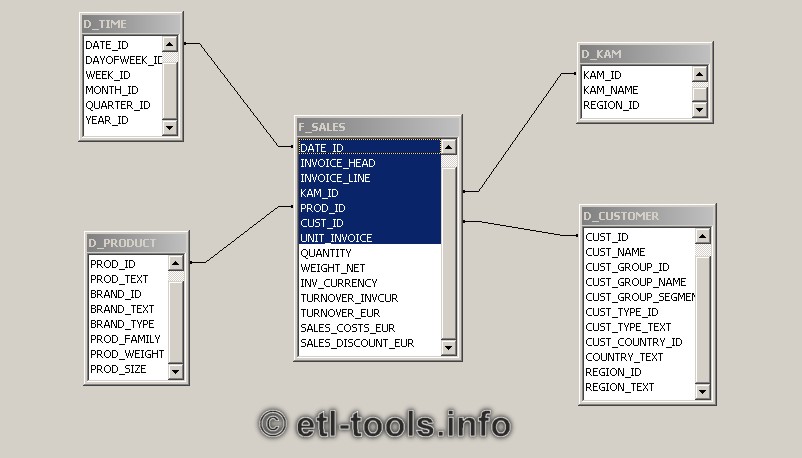{kind=link}
但我认为,这对于时间来说是没有意义的。维度表会不断增长。另一方面,使用日期维度表 JOIN 比使用日期/时间函数更有效SQL。
您的意见/解决方案是什么?
(我正在使用 Infobright)
java - 从 Java 访问 infobright
有人会建议我从 java 访问 Infobright 的技术吗?据我了解,我应该使用普通的 jdbc 连接并执行查询,而不是使用 hibernate 之类的高级东西。我对吗?
mysql - Infobright Enterprise Edition (IEE) 服务无法启动?
我去了 www.infobright.com,下载了 Infobright Enterprise Edition (IEE),并安装了它。但是,该服务不会启动,并且它绝对没有提示我错误是什么以及为什么。
performance - 混合面向列和面向行的数据库?
我目前正在尝试提高 Web 应用程序的性能。该应用程序的目标是提供(real time) analytics. 我们有一个类似于star schema少量事实表和多维表的数据库模型。数据库Mysql与MyIsam引擎一起运行。
Fact 表的大小很容易达到上百万,一些维度表也可以达到上百万。
现在的重点是,如果维度表在事实表上连接并且聚合完成,则选择查询会变得非常慢。听到这个时首先想到的是,为什么不预先计算数据呢?这是不可能的,因为允许用户使用几个可自由定制的过滤器。
所以我需要的是一个适合各种用途的一体化系统;)遗憾的是,它还没有被发明出来。所以我想到了结合两个现有系统的想法。混合 arow oriented和column oriented数据库(例如 likeinfinidb或infobright)。保留 mysql MyIsam 解决方案(用于快速插入和基于行的查询)并向其添加面向列的数据库(用于在少数列上进行快速聚合操作)并通过 cronjob 定期(每晚)填充它。问题是当查询当前数据(它必须是实时的)时,因此我可能需要从两个数据库中获取数据,这会使事情变得复杂。
使用 infinidb 进行的第一次测试显示在聚合几列时性能非常好,所以我真的认为这可以帮助我加快应用程序的速度。
所以问题是,这是个好主意吗?有人可能已经这样做了吗?也许有更好的方法来做到这一点。
我还没有面向列的数据库的经验,我也不确定它的架构应该是什么样子。第一次测试显示在相同star schema like结构上的良好性能,而且在结构上也表现出良好的性能big table like。
我希望这个问题适合SO。
mysql - 如何通过 perl 连接 infobright DB?
如何通过 perl 连接 infobright DB?
mysql - 在 InfoBright ICE 中加载数据时遇到问题
ICE 版本: infobright-3.5.2-p1-win_32
我正在尝试加载一个大文件,但一直遇到错误问题,例如:
错误的数据或列定义。行:989,字段:5。
这是第 989 行,第 5 字段:
“(450)568-3***”
注意:最后 3 个字符也是数字,但不想在此处发布某人的电话号码。
它与该字段中的任何其他条目确实没有什么不同。
该字段的数据类型是 VARCHAR(255) NOT NULL
jasper-reports - 如何在 Jasper Reports 中执行多个 mysql 查询(不是你想的那样......)
我有一个复杂的查询,需要在其中排名。我了解到这样做的标准方法是使用此页面上的技术:http: //thinkdiff.net/mysql/how-to-get-rank-using-mysql-query/。我使用 Infobright 作为后端,但它并没有像预期的那样工作。也就是说,虽然标准的 MySQL 引擎会将排名显示为 1、2、3、4 等...... Brighthouse(Infobright 的引擎)会返回 1、1、1、1 等......所以我想出了一种设置变量、函数,然后在查询中执行的策略。这是一个概念验证查询,它就是这样做的:
然后我将该函数复制并粘贴到 Jasper Report 的 iReport 中,然后编译我的报告。执行后,出现语法错误。所以我想也许是;把它扔掉了。所以在查询的顶部,我输入了 DELIMITER ;。这也不起作用。
我想做的甚至可能吗?如果是这样,怎么做?如果有一种 Infobright 方法可以在不编写函数的情况下获得排名,我也会对此持开放态度。
rdbms - infobright 中的最大列数
我们将数十亿行存储在一个 infobright 表中,该表目前大约有 45 列。我们想再添加 50 列。添加这些列会降低读取性能吗?为这些列创建新表是更好的选择吗?或者,由于 infobright 是一个面向列的数据库,增加 50 个额外的列并不重要?
谢谢!