问题标签 [gpudirect]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
cuda - AMD 的 OpenCL 是否提供类似于 CUDA 的 GPUDirect 的功能?
NVIDIA 提供GPUDirect以减少内存传输开销。我想知道 AMD/ATI 是否有类似的概念?具体来说:
1) AMD GPU 在与网卡接口时是否避免第二次内存传输,如此处所述。如果图形在某些时候丢失,这里描述了 GPUDirect 对从一台机器上的 GPU 获取数据以通过网络接口传输的影响:使用 GPUDirect,GPU 内存进入主机内存,然后直接进入网络接口卡。如果没有 GPUDirect,GPU 内存会在一个地址空间中转到 Host 内存,然后 CPU 必须进行复制以将内存获取到另一个 Host 内存地址空间,然后才能到网卡。
{kind=link}
2) 当两个 GPU 在同一 PCIe 总线上共享时,AMD GPU 是否允许 P2P 内存传输,如此处所述。如果图形在某些时候丢失,这里描述了 GPUDirect 对在同一 PCIe 总线上的 GPU 之间传输数据的影响:使用 GPUDirect,数据可以直接在同一 PCIe 总线上的 GPU 之间移动,而无需接触主机内存。如果没有 GPUDirect,数据总是必须先返回主机,然后才能到达另一个 GPU,无论该 GPU 位于何处。
{kind=link}
编辑:顺便说一句,我不完全确定 GPUDirect 有多少是蒸汽软件,有多少实际上是有用的。我从未真正听说过 GPU 程序员将它用于真正的事情。对此的想法也很受欢迎。
cuda - GPUDirect RDMA 从 GPU 传输到远程主机
设想:
我有两台机器,一个客户端和一个服务器,用 Infiniband 连接。服务器机器有一个 NVIDIA Fermi GPU,但客户端机器没有 GPU。我有一个在 GPU 机器上运行的应用程序,它使用 GPU 进行一些计算。GPU 上的结果数据从不被服务器机器使用,而是直接发送到客户端机器而不进行任何处理。现在我正在做一个cudaMemcpy将数据从 GPU 获取到服务器的系统内存,然后通过套接字将其发送到客户端。我正在使用SDP为这种通信启用RDMA。
问题:
在这种情况下,我是否可以利用 NVIDIA 的 GPUDirect 技术摆脱cudaMemcpy呼叫?我相信我已经正确安装了 GPUDirect 驱动程序,但我不知道如何在不先将其复制到主机的情况下启动数据传输。
我的猜测是不可能将 SDP 与 GPUDirect 结合使用,但是是否有其他方法可以启动从服务器机器的 GPU 到客户端机器的 RDMA 数据传输?
奖励:如果 somone 有一种简单的方法来测试我是否正确安装了 GPUDirect 依赖项,那也会很有帮助!
cuda - CUDA:GeForce GTX 690 上的 GPUDirect
GeForce GTX 690(来自 Zotac 和 EVGA 等供应商)可用于 CUDA 编程,很像 Tesla K10。
问:GeForce GTX 690 是否支持 GPUDirect?具体来说:如果我使用两张 GTX 690 卡,我将有 4 个 GPU(每张卡内有两个 GPU)。如果我将两个 GTX 690 卡连接到同一个 PCIe 交换机,GPUDirect 是否可以很好地用于 4 个 GPU 中的任何一对之间的通信?
谢谢。
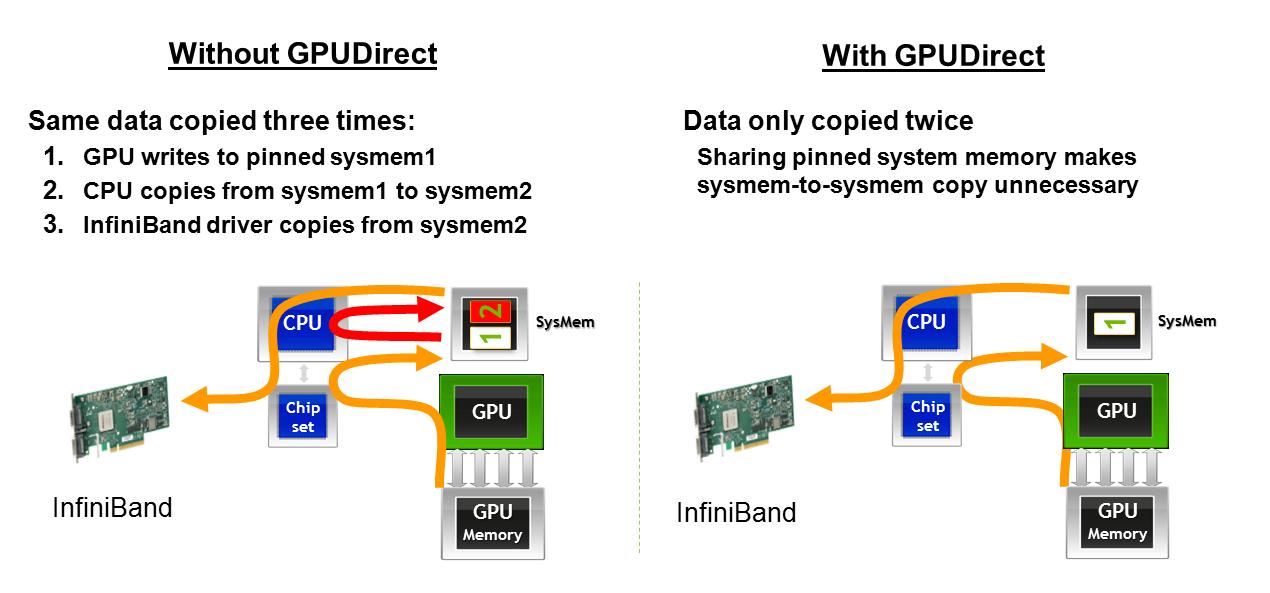
cuda - 没有 GPUDirect 的 cuda-mpi 编程模型
我正在使用不支持 GPUDirect 的 GPU 集群。从这个简报中可以看出,在跨节点传输 GPU 数据时会执行以下操作:
- GPU 写入固定的 sysmem1
- CPU 从 sysmem1 复制到 sysmem2
- 从 sysmem2 复制 Infiniband 驱动程序
现在我不确定当我使用 MPI 跨 Infiniband 传输 sysmem1 时第二步是否是隐式步骤。通过假设这一点,我当前的编程模型是这样的:
- cudaMemcpy(hostmem, devicemem, size, cudaMemcpyDeviceToHost)。
- MPI_Send(hostmem,...)
我的上述假设是否正确,我的编程模型是否可以正常工作而不会导致通信问题?
cuda - nVidia RDMA GPUDirect 是否总是只操作物理地址(在 CPU 的物理地址空间中)?
我们知道:http ://en.wikipedia.org/wiki/IOMMU#Advantages
IOMMU可以支持外设内存分页。使用 PCI-SIG PCIe 地址转换服务 (ATS) 页面请求接口 (PRI) 扩展的外围设备可以检测并发出对内存管理器服务的需求。

但是当我们使用 CUDA >= 5.0 的 nVidia GPU 时,我们可以使用 RDMA GPUDirect,并且知道:
http://docs.nvidia.com/cuda/gpudirect-rdma/index.html#how-gpudirect-rdma-works
传统上,像 BAR 窗口这样的资源使用 CPU 的 MMU 作为内存映射 I/O (MMIO) 地址映射到用户或内核地址空间。但是,由于当前的操作系统没有足够的机制在驱动程序之间交换 MMIO 区域,因此 NVIDIA 内核驱动程序导出函数来执行必要的地址转换和映射。
http://docs.nvidia.com/cuda/gpudirect-rdma/index.html#supported-systems
从 PCI 设备的角度来看,GPUDirect 的 RDMA 目前依赖于所有物理地址相同。这使得它与 IOMMU 不兼容,因此必须禁用 RDMA 才能使 GPUDirect 工作。
如果我们将 CPU-RAM 分配并映射到 UVA,如下所示:
我们在 Windwos7x64 中得到相等的指针,这意味着cudaHostGetDevicePointer()什么都不做:
host_src_ptr = 68719476736
uva_src_ptr = 68719476736
“在驱动程序之间交换 MMIO 区域的足够机制”是什么意思,这里的机制是什么意思,以及为什么我不能通过使用虚拟地址通过 PCIe 访问 BAR 的物理区域来使用 IOMMU - 通过 PCIe 的另一个内存映射设备?
这是否意味着 RDMA GPUDirect 始终只操作物理地址(在 CPU 的物理地址空间中),但是为什么我们向内核函数发送uva_src_ptr等于host_src_ptr- CPU 虚拟地址空间中的简单指针?
cuda - 我可以在两台 Quadro K1100M 或两台 GeForce GT 745M 之间使用 GPUDirect v2 点对点通信吗?
我可以在单个 PCIe 总线上使用GPUDirect v2 - 点对点通信吗?:
- 两者之间:移动 nVidia Quadro K1100M
- 两者之间:移动 nVidia GeForce GT 745M
gpu - GPUDirect 如何在共享设备上强制隔离
我一直在这里https://developer.nvidia.com/gpudirect阅读有关 GPUDirect 的信息,在此示例中,有一个网卡连接到 PCIe 以及两个 GPU 和一个 CPU。
如何在尝试访问网络设备的所有客户端之间实施隔离?他们都访问设备的同一个 PCI BAR 吗?
网络设备是否使用某种 SR-IOV 机制来强制隔离?
cuda - 我可以通过 GPUDirect 2.0 P2P 在远程 GPU-RAM 上使用 CUDA 原子操作吗?
例如,我可以在其全局内存 (GPU-RAM) 上使用 CUDA 原子操作atomicAdd(ptr, val), atomicCAS(ptr, old, new), ...。使用 CUDA 6.5。
但是我可以通过GPUDirect 2.0 P2P将这些原子操作用于远程全局内存吗?
cuda - 如何在 Infiniband 中使用 GPUDirect RDMA
我有两台机器。每台机器上有多张特斯拉卡。每台机器上还有一张 InfiniBand 卡。我想通过 InfiniBand 在不同机器上的 GPU 卡之间进行通信。只需点对点单播就可以了。我当然想使用 GPUDirect RDMA,这样我就可以省去额外的复制操作。
我知道Mellanox 现在为其 InfiniBand 卡提供了一个驱动程序。但它没有提供详细的开发指南。我也知道 OpenMPI 支持我要求的功能。但是 OpenMPI 对于这个简单的任务来说太重了,它不支持单个进程中的多个 GPU。
我想知道直接使用驱动程序进行通信是否可以得到任何帮助。代码示例,教程,任何东西都会很好。另外,如果有人可以帮助我在 OpenMPI 中找到处理此问题的代码,我将不胜感激。
directx - Nvidia GPUDirect 和相机捕捉到 GPU
我有一个 USB3 相机,我需要将捕获的图像加载到 DirectX 纹理中。目前我只是在用户模式下的代码中执行此操作 - 抓取图像并将它们上传到 GPU,这当然是 CPU 的某些开销和约 5-7 毫秒的延迟。
在新 PC 上有 Nvidia Quadro GPU 卡,GPUDirect据我了解,它支持 GPU 和 CPU 之间更快的内存共享,但我不确定如何利用它。为了将图像直接捕获到 GPU 缓冲区,相机驱动程序是否需要支持它?或者这是我可以在我的代码中配置的东西?