问题标签 [faster-rcnn]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
python - 对象检测 API:Faster-RCNN,图像尺寸问题
我已经在 Image Size: 720*700 pxs 上训练了我的模型,并修改了以下两个文件。一世。对象检测/核心/预处理器.py:
ii. 对象检测/训练/faster_rcnn_inception_v2_pets.config
两个代码片段的功能是什么?如果之前训练的图像是 600*600,这些代码会将我的图像调整为 3120*4160 吗?其次,当我在图像尺寸:3120*4160 上使用经过训练的模型进行检测和分类时,图像被随机裁剪,我没有在对象检测中获得整个图像。
任何帮助,将不胜感激。
tensorflow - 根据我的需要优化 Faster R-CNN Inception Resnet v2
我正在使用在 COCO 上预训练的Faster R-CNN Inception Resnet v2模型来训练我自己的对象检测器,目的是检测来自 3 个类别的对象。与图像的大小(分辨率)相比,对象很小。我对 ML 和 OD 比较陌生。
我想知道我应该对模型进行哪些更改以使其更适合我的目的。由于我只检测到 3 个类,因此降低模型某些部分的复杂性是个好主意吗?有没有更适合小物体的特征提取器?通常最好在预先训练的模型上进行训练,还是应该从头开始训练?
我知道将网络调整到特定需求是一个反复试验的过程,但是,由于训练网络需要大约 3 天的时间,我正在寻找一些有根据的猜测。
型号配置:
python - 如何在没有真实数据的张量流中学习隐藏模型变量(任务方差)
我正在使用automated focal loss最近从https://arxiv.org/pdf/1904.09048.pdf实施的更快 rcnn 类型的系统
在上面链接的论文中,3.4. Regression它指出
我们假设标签通过方差为 σ^2 的高斯分布围绕实际正确的基本事实分布。
和
然而,为了正确计算累积分布函数,需要估计任务的方差 σ^2。[...] 像网络的权重一样训练变量 σ^2。
我没有任务方差的数据σ^2。
我不完全理解如何在没有数据的情况下学习它。
我应该简单地制作变量trainable并假设优化知道该怎么做吗?
pytorch - 无法更改 Faster RCNN 中的锚点
我是 pytorch 的新手,我试图在 pytorch 的 Faster RCNN 网络上放置一些自定义锚点。基本上,我使用的是 resnet50 骨干网,当我尝试放置锚点时,出现不匹配错误。
这是我拥有的代码:
我得到的错误如下:形状'[1440000,-1]'对于大小为7674336的输入无效。
neural-network - 区域提议网络如何在 Faster R-CNN 中工作?
我试图了解如何从特征图生成锚框坐标,我对此过程有一些疑问。
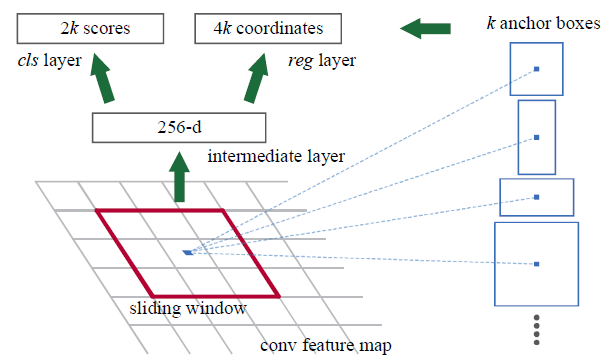
1-) 从上图中,特征图大小为 N x M x C,滑动窗口选择为 3x3。这个 3x3 窗口的任务是什么?我想,它是用来将尺寸从 NxMxC 缩小到 NxMx1 的吗?我对吗?如果不知道这个窗口的任务是什么?
2-) 要从特征图中获取 RGB 输入图像上的锚框坐标,3x3 窗口如何影响该坐标?
提前致谢。
python-3.x - 需要有关在 PyTorch 中迁移学习更快的 RCNN ResNet50FPN 的帮助
我是 PyTorch 的新手。我正在尝试将预训练的 Faster RCNN torchvision.models.detection.fasterrcnn_resnet50_fpn() 用于对象检测项目。我创建了一个 CustomDataset(Dataset) 类来处理自定义数据集。
这是自定义类实现
这是 train_model 函数
在执行 model_ft = train_model(model_ft, criteria, optimizer_ft, exp_lr_scheduler, num_epochs=25) 我收到“RuntimeError: _thnn_upsample_bilinear2d_forward not supported on CUDAType for Byte”
python - 使用 cuda 在 pytorch 1.0 上训练 frcnn:分段错误(核心转储)
我尝试使用这个repo在我的自定义 VOC 数据集上训练 FRCNN:
我已经安装了所需的依赖项和最新的 g++。而且我还有 cuda 工作(我能够运行 mmdetection 包)。如何诊断和修复此类崩溃?
tensorflow - 是否有必要在图像上标记一个类的每个对象?
我标记了一堆图像,用于训练一个 Faster-RCNN 网络,用于一个类的对象检测。每个图像上大约有数百或数千个此类对象。我必须给它们都贴上标签吗?
现在我在每个图像上标记了大约 20 到 80 个对象实例。因此,我选择了我认为易于识别的对象。
当我开始用这个数据集训练网络时,损失在 0.9 到 20,000,000 之间
通常损失应该变小,但在我的情况下它会减少并且具有极高的峰值。
mask - 来自 Mask R-CNN utils.py 的 mAP 和来自 (MS)COCO 的 mAP 有什么区别?
我用自己的数据训练了我的 Mask R-CNN 网络,我将其转换为 COCO Style 用于我的论文,现在我想评估我的结果。我找到了两种方法来做到这一点。一种方法是来自 COCO 本身的评估。Mask R-CNN 本身在他们的 coco.py 文件中展示了如何使用 COCO Metric 进行评估: https ://github.com/matterport/Mask_RCNN/blob/master/samples/coco/coco.py
我基本上使用第evaluate_coco(...)342 行中的函数。结果,我从 COCO 指标中获得了不同指标的平均精度和平均召回率的结果,请参见下图。对于参数 eval_type 我使用eval_type="segm".
对我来说,mAP 很有趣。我知道 mAP50 使用 0.5 作为 IuO(联合交叉点),它们的标准 mAP 是从 IuO = 0.5 到 0.95,步长为 0.05。
第二种方法来自 Mask R-CNN 本身在他们的 utils.py 中: https ://github.com/matterport/Mask_RCNN/blob/master/mrcnn/utils.py
函数的名称compute_ap(...)在第 715 行,上面写着 IoU 是 0.5。该函数返回一个 mAP 值。
这就提出了compute_ap()评估什么类型的问题。使用 COCO,您可以在“bbox”和“segm”之间进行选择。
我还想知道compute_ap(...)函数的 mAP 值和 COCO 的 mAP50 之间的区别,因为使用相同的数据我得到不同的结果。不幸的是我现在不能上传更好的图片,因为我只能在周一到周五去我的大学,周五我很匆忙,没有检查就拍照,但是所有 AP 的平均值compute_ap()是 0.91,我我很确定 COCO 的 AP50 是 0.81。
有人知道区别还是没有区别?


是不是因为maxDets=100这个参数?: 了解COCO评价“最大检测数” 我的图片只有4个类别,每张图片最多4个实例。
还是计算mAP的方式不同?
编辑:现在我对“Segm”类型和“BBox”类型的整个 COCO 度量有一个更好的图像,并将它与来自的结果进行compute_ap()比较,即“mAP:0,41416 ...”顺便说一句,如果有COCO 结果中的“-1”,这是否意味着该类型没有?

keras - 对象检测 - 在训练期间忽略特定图像区域
我正在尝试使用 Faster R-CNN 算法使用 keras 进行车辆检测。
我有一个包含不同文件夹的数据集,每个文件夹都包含多个图像。我已经设法将图像的注释文件转换为用于训练过程的 CSV 文件。注释文件包含有关训练期间图像中要忽略的区域的额外信息(附加图像中的黑色区域)。该图像根据从该图像的注释文件中获得的信息,在测试示例中显示了车辆的边界框以及图像中被忽略的区域。
有没有办法在算法训练期间指定要关注或忽略的特定区域?
