问题标签 [bayesian]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
statistics - 人工智能/确定颜色名称的统计方法
我正在考虑编写一个小库来从预定的候选列表中猜测(RGB 值)颜色的名称。
我的第一次尝试纯粹基于 3 维 RGB 颜色空间内的毕达哥拉斯距离——这并没有取得巨大成功,因为大多数命名的颜色点都位于空间的边缘(例如蓝色在 0、0、255),所以,对于空间中间的大多数颜色,它最接近的命名颜色也是相当随意的。
所以,我正在考虑更好的方法,并提出了一些候选人
HSV 颜色空间内的圆柱距离 - 这可能与上述问题类似,但是,HSV 在人类意义上似乎比 RGB 更有意义,这可能是有用的。
上述任何一种,但每个命名的颜色点都使用任意值加权,该值表示其对周围空间中点的吸引力强度。这种模型有名字吗?我意识到这有点模糊,但对我来说这似乎是一个相当直观的想法。
一个贝叶斯网络,它检查 HSV 颜色的属性并返回最可能的颜色名称(我想象的节点类似于,例如 P(Black | Saturation < 10), P(Red | Hue = 0),但是,这似乎不太理想 - 例如,给定颜色为红色的概率与其色调与 0 的接近程度成正比,而不是离散值。有没有一种方法可以调整贝叶斯网络来处理在正在测试的变量?
最后,我想知道在 HSV 或 RGB 颜色空间中是否有某种基于支持向量机的分类,但对这些分类并不十分熟悉,我不确定这是否会比基于勾股距离的方法提供任何特别的优势我最初尝试过,特别是因为我只处理三维空间。
因此,我想知道,你们中是否有人遇到过类似的问题,或者知道任何可以帮助我决定方法的资源?如果有人能指出我正确的方向(无论是上述之一,还是完全不同的东西),我将非常感激。
干杯!
蒂姆
algorithm - 为自动标记实现问题分析器
实施问题分析器有哪些好的资源?
我试图弄清楚如何自动标记问题,以使非技术用户更容易提问。我发现使用贝叶斯定理可以实现这一点,但我不知道如何实现它。
有任何开源库或研究论文吗?
algorithm - 贝叶斯评级系统,每个评级都有多个类别
我正在实施要在我的网站上使用的评级系统,我认为贝叶斯平均值是最好的方法。用户将根据六个不同的类别对每个项目进行评分。不过,我不希望只有一个高评分的项目能登上榜首,这就是我想要实施贝叶斯系统的原因。
这是公式:
因为这些项目将被分为 6 个不同的类别,我应该使用这些类别总和的平均值作为贝叶斯系统的“this_rating”吗?例如,取一项有两个评级(0-5 级)的项目:
“this_rating”应该只是上面列出的总和的平均值吗?我的想法是正确的,还是应该为每个类别实施贝叶斯系统(或者是过度思考)?
php - 贝叶斯分类器的 PHP 实现:将主题分配给文本
在我的新闻页面项目中,我有一个数据库表news,其结构如下:
此外,还有一个包含词频信息的表格贝叶斯:
现在我希望我的 PHP 脚本对所有新闻条目进行分类,并为它们分配几个可能的类别(主题)之一。
这是正确的实现吗?你能改进它吗?
培训是手动完成的,它不包含在此代码中。如果将文本“你可以通过出售房地产赚钱”分配给类别/主题“经济学”,那么所有单词(you,can,make,...)都将插入到表贝叶斯中,其中“经济学”为主题和 1作为标准计数。如果单词已经与相同的主题组合在一起,则计数会增加。
样本学习数据:
字数主题
卡钦斯基政治 1
索尼技术 1
银行经济学 1
电话技术1
索尼经济学 3
爱立信科技2
样本输出/结果:
文字标题:电话测试索尼爱立信阿斯彭-敏感温贝里
政治
....电话 ....测试 ....索尼 ....爱立信 ....阿斯彭 ....敏感 ....winberry
技术
....发现手机 ....测试 ....索尼发现 ....爱立信发现 ....aspen ....敏感 ....winberry
经济学
....电话 ....测试 ....发现索尼 ....爱立信 ....阿斯彭 ....敏感 ....温莓
结果:文本属于主题技术,可能性为 0.013888888888889
非常感谢您!
c# - 为 Twitter 情感分析项目寻找 C# 中的开源朴素贝叶斯分类器
我在这里找到了一个类似的项目:Python 中 Twitter 的情绪分析。但是,我正在使用 C# 并且需要使用以相同语言开源的朴素贝叶斯分类器。除非有人能阐明我如何利用 python 贝叶斯分类器来实现相同的目标。有任何想法吗?
python - 针对特定应用程序的贝叶斯网络的 Pythonic 实现
这就是我问这个问题的原因: 去年我编写了一些 C++ 代码来计算特定类型模型(由贝叶斯网络描述)的后验概率。该模型运行良好,其他一些人开始使用我的软件。现在我想改进我的模型。由于我已经为新模型编写了稍微不同的推理算法,因此我决定使用 python,因为运行时并不是至关重要的,python 可以让我编写更优雅和更易于管理的代码。
通常在这种情况下,我会在 python 中搜索现有的贝叶斯网络包,但我使用的推理算法是我自己的,我还认为这将是一个了解更多关于 python 良好设计的好机会。
我已经为网络图 (networkx) 找到了一个很棒的 python 模块,它允许您将字典附加到每个节点和每个边。本质上,这可以让我给出节点和边的属性。
对于特定网络及其观察数据,我需要编写一个函数来计算模型中未分配变量的可能性。
例如,在经典的“亚洲”网络(http://www.bayesserver.com/Resources/Images/AsiaNetwork.png)中,已知“X 射线结果”和“呼吸困难”的状态,我需要编写一个函数计算其他变量具有某些值的可能性(根据某些模型)。
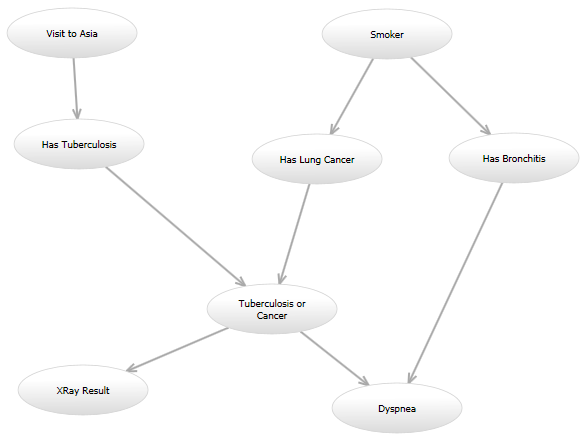{kind=link}
这是我的编程问题: 我将尝试一些模型,将来我可能会想尝试另一种模型。例如,一种模型可能看起来与亚洲网络完全一样。在另一个模型中,可能会从“访问亚洲”到“患有肺癌”添加有向边。另一个模型可能使用原始的有向图,但给定“肺结核或癌症”和“患有支气管炎”节点的“呼吸困难”节点的概率模型可能不同。所有这些模型都将以不同的方式计算可能性。
所有模型将有大量重叠;例如,如果所有输入均为“0”,则进入“或”节点的多条边将始终为“0”,否则为“1”。但是有些模型的节点会在某个范围内采用整数值,而其他模型将是布尔值。
在过去,我一直在为如何编写这样的东西而苦苦挣扎。我不会说谎;有相当多的复制和粘贴代码,有时我需要将单个方法中的更改传播到多个文件。这次我真的很想花时间以正确的方式做到这一点。
一些选项:
- 我已经以正确的方式这样做了。先写代码,再问问题。复制和粘贴代码并为每个模型设置一个类会更快。世界是一个黑暗而杂乱无章的地方……
- 每个模型都是它自己的类,也是一般贝叶斯网络模型的子类。这个通用模型将使用一些将被覆盖的函数。Stroustrup 会感到自豪。
- 在同一个类中创建几个计算不同可能性的函数。
- 编写一个通用的 BayesianNetwork 库并将我的推理问题实现为该库读取的特定图表。节点和边应该被赋予像“Boolean”和“OrFunction”这样的属性,给定父节点的已知状态,可以用来计算不同结果的概率。这些属性字符串,例如“OrFunction”,甚至可以用来查找和调用正确的函数。也许几年后我会做出类似于 1988 年版 Mathematica 的东西!
非常感谢你的帮助。
更新: 面向对象的思想在这里有很大帮助(每个节点都有一组指定的特定节点子类型的前驱节点,并且每个节点都有一个似然函数,可以根据前驱节点的状态计算其不同结果状态的可能性等。 )。哎呀!
java - 将 Ruby 代码翻译成 Java
我从未使用过 ruby,但需要将此代码转换为 java。
谁能帮我。
这是 Ruby 中的代码。
我从这里得到它,所以也许可以在那里找到一些线索。关于计算平均值
这就是解决方案。万一有人需要
python - 拉普拉斯平滑到 Biopython
我正在尝试为我的生物信息学项目添加对 Biopython 的朴素贝叶斯代码1的拉普拉斯平滑支持。
我已经阅读了许多关于朴素贝叶斯算法和拉普拉斯平滑的文档,我想我已经有了基本的想法,但是我无法将它与该代码集成(实际上我看不到我将添加 1 -拉普拉斯数的哪一部分)。
我不熟悉 Python,我是一个新手编码器。如果有熟悉 Biopython 的人能给我一些建议,我将不胜感激。
c# - 文本作者识别的贝叶斯分类
我有兴趣使用 C# 构建自己的文本作者识别系统。我假设我可能不得不使用某种类型的贝叶斯分类算法来完成这个。
有谁知道有任何资源或现有的图书馆可以做类似的事情?