好的!!,你可以这样做
分割图像功能
def split_img_label(data_train,data_test,folder_train,foler_test):
os.mkdir(folder_train)
os.mkdir(folder_test)
train_ind=list(data_train.index)
test_ind=list(data_test.index)
# Train folder
for i in tqdm(range(len(train_ind))):
os.system('cp '+data_train[train_ind[i]]+' ./'+ folder_train + '/' +data_train[train_ind[i]].split('/')[2])
os.system('cp '+data_train[train_ind[i]].split('.jpg')[0]+'.txt'+' ./'+ folder_train + '/' +data_train[train_ind[i]].split('/')[2].split('.jpg')[0]+'.txt')
# Test folder
for j in tqdm(range(len(test_ind))):
os.system('cp '+data_test[test_ind[j]]+' ./'+ folder_test + '/' +data_test[test_ind[j]].split('/')[2])
os.system('cp '+data_test[test_ind[j]].split('.jpg')[0]+'.txt'+' ./'+ folder_test + '/' +data_test[test_ind[j]].split('/')[2].split('.jpg')[0]+'.txt')
代码
import pandas as pd
import os
PATH = './TrainingsData/'
list_img=[img for img in os.listdir(PATH) if img.endswith('.jpg')==True]
list_txt=[img for img in os.listdir(PATH) if img.endswith('.txt')==True]
path_img=[]
for i in range (len(list_img)):
path_img.append(PATH+list_img[i])
df=pd.DataFrame(path_img)
# split
data_train, data_test, labels_train, labels_test = train_test_split(df[0], df.index, test_size=0.20, random_state=42)
# Function split
split_img_label(data_train,data_test,folder_train_name,folder_test_name)
输出
len(list_img)
583
100%|████████████████████████████████████████████████████████████████████████████████| 466/466 [00:26<00:00, 17.42it/s]
100%|████████████████████████████████████████████████████████████████████████████████| 117/117 [00:07<00:00, 16.61it/s]
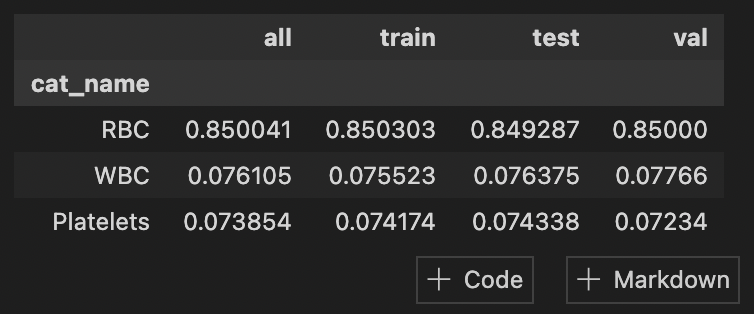
最后,您将拥有 2 个具有相同图像和标签的文件夹 ( folder_train_name,folder_test_name )。