我如何对变量进行排序以便绘制它们,例如热图/它们显示相似模式的位置,即:在顶部 A 和 D,然后是 B、C 和底部 E。希望避免将其作为真实数据手动执行是更多的变量。
Variable1 <- c(rep("A",7), rep("B",7),rep("C",7), rep("D",7), rep("E",7))
Variable2 <- c(rep(1:7, 5))
value <- c(15, 16, 11, 12, 13, 11, 12, 4, 3, 6, 5, 4, 3, 2, 3, 3, 2, 3, 3, 4, 3, 18, 17, 15, 2, 3, 4, 5, 2, 3, 4, 5, 6, 10, 18)
dff <- data.frame(Variable1, Variable2, value)
library(dplyr)
dff <- dff %>%group_by(Variable1)%>%
mutate(scaled_val = scale(value)) %>%
ungroup()
dff$Variable <- factor(dff$Variable1,levels=rev(unique(dff$Variable1)))
ggplot(dff, aes(x = Variable2, y = Variable1, label=NA)) +
geom_point(aes(size = scaled_val, colour = value)) +
geom_point(aes(size = scaled_val, colour = value), shape=21, colour="black") +
geom_text(hjust = 1, size = 2) +
theme_bw()+
scale_color_gradient(low = "lightblue", high = "darkblue")+
scale_x_discrete(expand=c(1,0))+
coord_fixed(ratio=4)

并希望:

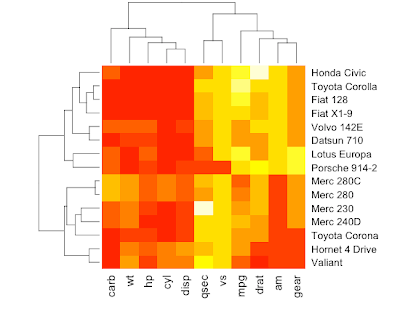
如果您查看具有相似性的聚集行的热图,例如:https ://3.bp.blogspot.com/-AI2dxe95VHk/TgTJtEkoBgI/AAAAAAAAC5w/XCyBw3qViGA/s400/heatmap_cluster2.png您会在顶部看到该行其模式是第一个 x 轴时间点,然后是最后一个 x 轴时间点的更高的时间点。
要做的事情:所以我想知道是否使用缩放值,我们可以这样做,顶部是变量2(1:2)中平均值较高的值,然后是变量2(3:5)和变量2(6:7)平均值较高的值。如果我在这里不清楚并且可以更好地解释,请告诉我。

{kind=link}