前言:
我试图解决这个Windy-Grid-World 环境。实现了 Q 和 Q(λ) 算法后,结果几乎相同(我正在查看每集的步骤)。
问题:
根据我的阅读,我相信更高的 lambda 参数应该会更新更多的状态。因此,与常规 Q-learning 相比,步数的减少应该大大减少。这张图片显示了我在说什么。
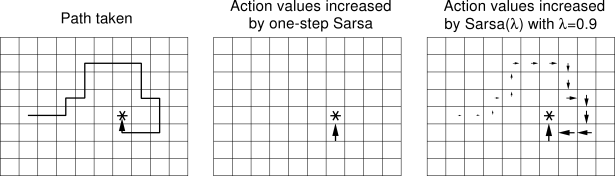{kind=link}
这对于这种环境是正常的还是我实施错了?
代码:
import matplotlib.pyplot as plt
import numpy as np
from lib.envs.windy_gridworld import WindyGridworldEnv
from collections import defaultdict
env = WindyGridworldEnv()
def epsilon_greedy_policy(Q, state, nA, epsilon):
'''
Create a policy in which epsilon dictates how likely it will
take a random action.
:param Q: links state -> action value (dictionary)
:param state: state character is in (int)
:param nA: number of actions (int)
:param epsilon: chance it will take a random move (float)
:return: probability of each action to be taken (list)
'''
probs = np.ones(nA) * epsilon / nA
best_action = np.argmax(Q[state])
probs[best_action] += 1.0 - epsilon
return probs
def Q_learning_lambda(episodes, learning_rate, discount, epsilon, _lambda):
'''
Learns to solve the environment using Q(λ)
:param episodes: Number of episodes to run (int)
:param learning_rate: How fast it will converge to a point (float [0, 1])
:param discount: How much future events lose their value (float [0, 1])
:param epsilon: chance a random move is selected (float [0, 1])
:param _lambda: How much credit to give states leading up to reward (float [0, 1])
:return: x,y points to graph
'''
# Link state to action values
Q = defaultdict(lambda: np.zeros(env.action_space.n))
# Eligibility trace
e = defaultdict(lambda: np.zeros(env.action_space.n))
# Points to plot
# number of episodes
x = np.arange(episodes)
# number of steps
y = np.zeros(episodes)
for episode in range(episodes):
state = env.reset()
# Select action
probs = epsilon_greedy_policy(Q, state, env.action_space.n, epsilon)
action = np.random.choice(len(probs), p=probs)
for step in range(10000):
# Take action
next_state, reward, done, _ = env.step(action)
# Select next action
probs = epsilon_greedy_policy(Q, next_state, env.action_space.n, epsilon)
next_action = np.random.choice(len(probs), p=probs)
# Get update value
best_next_action = np.argmax(Q[next_state])
td_target = reward + discount * Q[next_state][best_next_action]
td_error = td_target - Q[state][action]
e[state][action] += 1
# Update all states
for s in Q:
for a in range(len(Q[s])):
# Update Q value based on eligibility trace
Q[s][a] += learning_rate * td_error * e[s][a]
# Decay eligibility trace if best action is taken
if next_action is best_next_action:
e[s][a] = discount * _lambda * e[s][a]
# Reset eligibility trace if random action taken
else:
e[s][a] = 0
if done:
y[episode] = step
e.clear()
break
# Update action and state
action = next_action
state = next_state
return x, y
如果您想查看全部内容,可以在此处查看我的 Jupyter Notebook 。