问题标签 [tree-traversal]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
regex - 编号正则表达式子匹配
正则表达式中是否存在子匹配表达式的规范排序?
例如:
"(([0-9]{3}).([0-9]{3}).([0-9]{3}).([0- 9]{3}))\s+([AZ]+)" ?
或者
c# - 在c#中遍历对象树
我有一棵由多个对象组成的树,其中每个对象都有一个名称 ( string)、id ( int),可能还有一个相同类型的子数组。我如何遍历整个树并打印出所有的 ID 和名称?
我是编程新手,坦率地说,我很难解决这个问题,因为我不知道有多少级别。现在我正在使用foreach循环来获取根目录下的父对象,但这意味着我无法获取子对象。
data-structures - 中序树遍历:哪个定义是正确的?
我有以下来自我不久前参加的关于二叉树(不是 BST)的中序遍历(他们也称之为 pancaking)的学术课程的文本:
中序树遍历
在树的外面画一条线。从根的左侧开始,然后绕过树的外部,最终到达根的右侧。尽可能靠近树,但不要越过树。(把树——它的分支和节点——想象成一个坚固的屏障。)节点的顺序是这条线在它们下面经过的顺序。如果您不确定何时走到节点“下方”,请记住“向左”的节点总是先出现。
这是使用的示例(与下面的树略有不同)
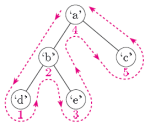
然而,当我在谷歌上搜索时,我得到了一个相互矛盾的定义。例如维基百科示例:

中序遍历序列:A、B、C、D、E、F、G、H、I(leftchild、rootnode、right node)
但根据(我对)定义#1的理解,这应该是
A、B、D、C、E、F、G、I、H
谁能澄清哪个定义是正确的?它们可能都描述了不同的遍历方法,但碰巧使用了相同的名称。我无法相信同行评审的学术文本是错误的,但不能确定。
c# - C# 大树迭代
我有一个以父/子关系组装的大型结果集。我需要遍历树并向用户显示结果。
我在使用递归之前已经这样做了,但是因为我的结果集可能很大,所以我想避免收到 StackOverflowException 的可能性。
我在使用堆栈的 MSDN 上找到了以下示例。我遇到的问题是因为堆栈是后进先出的,我的数据没有正确显示。我希望它看起来像下面这样:
但它看起来像:
有任何想法吗?
这是我的代码示例。假设DataTable dt具有以下列:ID、ParentID 和 Text
c - “重新传递”函数参数
我正在使用经典的 C 进行此类分配,并且遇到了关于采用可变参数计数和类型的回调函数的问题。
基本上,我正在研究一个散列树(每个节点都是一个散列树的树),并且我有一个特定的遍历策略,将多次用于不同的目的,所以我将它实现为ht_walk(HashTree tree, (*callback)(Element e)),这样称为回调的函数将以任何必要的方式处理元素。
问题是,在我的问题中的大多数情况下,回调函数必须采用不同的参数。我知道如何使用“可变参数”函数(使用 stdarg、printf-way)设计一个带有可变参数列表的函数,但我不知道如何将这些参数“重新传递”给回调函数。
让我提供一个具体的例子:假设我有一个名为 的回调函数addToList(Element e, List list),并且我的 ht_walk 声明是 now ht_walk(HashTree tree, (*callback)(Element e), ...)。考虑我想在以下代码段中使用 ht_walk :
有没有办法做到这一点?提前致谢!
algorithm - 广度优先与深度优先
遍历树/图时,广度优先和深度优先有什么区别?任何编码或伪代码示例都会很棒。
tree - 修改评论系统的前置遍历
我正在尝试为博客制作评论系统。我有修改后的预购遍历系统工作(使用本指南: http: //mikehillyer.com/articles/managing-hierarchical-data-in-mysql/)。
不过我有几个问题。我不认为该指南解释了如何管理不同的博客帖子,以及添加不是回复的评论。
我的评论表如下所示:
这是管理此问题的好方法吗:
我在评论表中添加了名为“blog_post_id”和“root”的列。当我发表一篇博文时,我会在评论表中添加一个带有 blog_post_id 的条目,并将 root 设置为 true。然后,lft 是comment_id,右边是comment_id + 1。
要加载博客文章的评论,我会在 blog_post_id = x 和 root = true 的地方找到 lft 和 rgt,然后选择 lft 和 rgt 之间 blog_post_id 为 x 的所有评论...
我只是想出了这个方法,所以我很确定一定有更好的方法。
谢谢
performance - 没有递归/堆栈使用的树遍历(C#)?
我正在使用 WPF,并且正在开发一个复杂的用户控件,它由具有丰富功能的树等组成。为此,我使用了 View-Model 设计模式,因为某些操作无法直接在 WPF 中实现。所以我采用 IHierarchyItem (这是一个节点并将其传递给此构造函数以创建树结构)
问题是这个构造函数大约需要 3 秒!我的双核上有 200 个项目。我做错了什么还是递归构造函数调用这么慢?非常感谢你!
algorithm - 不保留已访问标志的迭代后序遍历
为什么有必要为迭代后序遍历而不是为中序或前序迭代遍历保留已访问标志。
是否可以在不保留已访问标志的情况下进行后订单遍历?
c - 构建随机“整数”树 - 深度优先/广度优先
这是我第一次尝试用 c 编写递归函数。以下代码有效。我为长时间的发布道歉,但我试图尽可能清楚。
我正在尝试生成一个树,其中每个节点(inode)都有一个整数字段“n”。相应地,每个 inode 都有一个指向“n”个其他 inode 的指针数组。函数inode *I = gen_tree(inode *I, int nlevels);生成一棵树,每个级别都有随机数的 inode。树以深度优先的方式生成。我有几个问题。
(a) 有没有更好的方法来编写函数?任何反馈/建议将不胜感激。
(b) 可以在 BF 时尚中生成树吗?
(c)I->i应该有一个遍历树的索引。我怎样才能写一个函数来计算I->i?
(d)I->c应该具有给定节点下所有 inode 的累积和。我怎样才能写一个函数来计算I->c?
提前致谢,
〜拉斯