问题标签 [structured-data]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
semantic-web - HTML 中的结构化数据 - schema.org 或 GoodRelations
有没有人有经验,可以解释如何在 HTML 页面中正确使用结构数据。简单的事情很容易,但困难的事情怎么做呢?是否可以使用不同的标准,例如schema.org和GoodRelations。
我想有以下结构:
一个人,其职业是拥有医学职称的医生。专业是神经病学和儿科。
这个很简单(可能有一些错误):
下一节呢?此人在三个不同的地方工作:
- 私人办公室
- 医疗中心
- 一所医院
在每个地方,人出现在不同的时间和日子。每个地方都有不同的电话号码和不同的地理位置。这个人在每个地方都有不同的角色:
- 私人办公室的所有者
- 医疗中心的正式员工
- 医院神经科主任
在这里,我感到困惑。如何映射人和地点之间的所有关系?是否可以将结构数据放在不同的网页上?如果是这样,如何引用它们。
组织片段(可能还有很多错误):
php - 全局文件引用
我的基本文件结构类似于:
我想创建一个全局路径来建立我的 Web 根目录,无论它位于何处,我都可以在每个页面中动态引用它。我试图弄清楚如何使用 [例如] define(ROOT),以及如何从单个页面调用它。
知道所有页面都使用 [menu.php],我的障碍是,例如:
从 gala.php 页面 - 当我点击 [home] 时,它会查找:
但这不存在。
另外,如果可能的话,我会尽量避免这些 [2] 的事情:
像这样在gala.php中使用 html 文件引用:../../../../includes/menu.php [找到正确的全局包含]
并避免在menu.php中使用链接引用,如下所示:/images/global/nav/nav-img.jpg
**
更新
**
- 解决了
就像其他人发布的一样,我最终使用了:
当我从 html 调用它时效果很好:
这很棒,因为无论从哪里调用它们,我都可以找到我的包含...一旦我弄清楚如何使用它,这很容易。
**
剩下的问题
**
[对于上面的#2]唯一剩下的问题是我在包含中的所有html链接都被破坏了,其中包含是从ROOT以外的级别调用的。
我发现一种解决方法是只使用绝对路径,例如:
有没有一种方法可以为图像位置创建 DOCUMENT_ROOT 类型的文件引用,以便我的包含总能找到它们?
algorithm - 自然语言查询理解
我是 NLP 领域的新手,很抱歉我的问题可能很愚蠢或不正确。我期待任何可以为我提供正确方向的运动矢量的帮助。
现在我正在写我的论文,其中有一个重要的部分——自然语言查询解析器。以前我有一些搜索引擎算法的经验。但是现在我希望我的系统能够“理解”某些类型的查询,并且能够大致将其转换为数据库查询语言以执行结构化搜索。例如,对于查询“我住在俄罗斯的朋友”,系统只需查看“人”表并选择“国家=俄罗斯”的人。
我很清楚结构化搜索不像垃圾邮件过滤那样简单的 NLP 问题,但是现在已经诞生了很多这样的系统:Siri、Google Now、Facebook Graph Search。他们能够“理解”查询,而不仅仅是给出排名结果列表(就像经典搜索引擎所做的那样),而且能够正确呈现经过验证的信息类型。我对它们内部的工作方式很感兴趣,但找不到足够的信息。
我将不胜感激任何可以帮助我研究这些系统和论文进展的信息、任何参考资料和书籍。最好这些可以在实践中应用,而不是国防部封闭的发展:)
英语不是我的母语,如有错误请见谅,希望您能理解我的问题。
vb.net - 如何在VB中进行多项选择测试?
这是家庭作业的一部分。我必须有结构化数据,并阅读 .dat 文件中的问题。到目前为止,这就是我所拥有的。我的 Private Sub cmdNext_Click 函数遇到了最大的麻烦。有 4 个显示答案的单选按钮,以及必须显示每个问题的标签,当我单击下一个按钮时,它会显示下一个问题并记录提交的答案。最后,我必须显示一个包含答案和分数的消息框。
在一个模块中,我必须把我老师给我们的这段代码放进去:
然后以一种形式,我到目前为止有这个代码:
mysql - 如何通过 Syslog 发送结构化数据?
我有结构化数据,键值对,应该通过系统日志记录。最后,我们希望看到有关这些指标的统计数据。我们应该如何在接收端编码然后解码呢?
我们在 syslog 中解析日志的消息部分并基于该解析将其插入到关系数据库表中的一种选择。
我们的第二个想法是以 JSON 格式发送数据,在接收方,我们将关系数据库表视为作业队列,在插入单独的表之前必须解析记录。
此外,键值对可能会根据我们想要记录的内容而改变。
html - 重复事件的结构化数据
我是 smctheatre.com 的网站管理员。我们是一个社区剧院,每年都会上演几场戏剧。我正在将学习结构化数据添加到我的工具箱中。微格式、微数据或 RDFa,我对其中一个没有任何强烈的偏好。我确实喜欢 RDFa Lite 和 microfomat 的语法,而不是微数据和成熟的 RDFa。
我唯一无法得到答案的是如何标记在多个日期发生的事件,有时在不同的时间发生。
这是该网站的精简片段:
戏剧的持续时间通常为两个小时,但鉴于这些是现场表演,没有硬性和快速的结束时间。
如何标记内容以指示日期和时间?
seo - Can I use rel=author for a Google+ business page?
As I use the Structured Data Testing Tool, I noticed that the preview does allow my website logo to be appeared in the Google search result instead of the author's headshot:
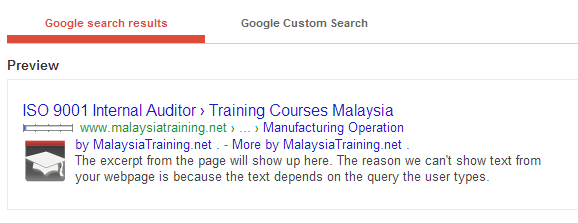{kind=link}
Although I've implemented rel="publisher" on my Google+ badge, if I'm not mistaken, the rich snippets "by MalaysiaTraining.net" and "More by MalaysiaTraining.net" are actually came from rel=author, which is to be implemented as the URL paramter to a Google+ profile URL but not the rel="publisher" attribute in the anchor tag (correct me if I'm wrong).
In order to achieve the exact effects as shown in the preview, I wonder if I can do something like that:
If this is illegal due to the author vs. publisher conflict, what if I remove the rel="publisher" attribute, leaving the rel=author parameter to be used only with my Google+ business page URL? Will this violate the Google SEO guidelines and cause a penalty?
Please advise me and thanks in advance!
google-plus - Google 结构化数据测试工具无法识别作者数据
我已经搜索了所有地方,但我无法弄清楚我做错了什么。不管怎样,我仍然Page does not contain authorship markup对结构化数据测试工具有所了解
我有两个页面几乎相同的网站。标签的rel=author插入方式相同。
这是一个有效的页面示例:http: //bit.ly/18odGef
这是一个没有的页面示例:http: //bit.ly/12vXdAm
我尝试添加?rel=author到 Google+ 个人资料网址的末尾,这似乎在这两个网站上都不起作用。我没有通过nofollowor阻止任何东西robots.txt。该工具没有被防火墙或任何东西阻止。谁能看到我在这里做错了什么以及为什么它适用于一个站点,而不适用于另一个站点?
仅供参考,无法正常工作的网站过去可以正常工作。在我意识到它不再起作用之前,我没有改变作者标记的组织方式。
html - 可以使用`itemscope = "false" itemtype = "false"`来指定没有结构化数据的页面吗?
我刚开始使用 schema.org 元标记来突出显示我网站上的结构化数据。
我正在使用 node.js、express 和 jam 来生成我的内容。我正在一些但不是所有页面上设置这些标签。我不想向搜索引擎歪曲未标记的页面。
我还没有找到一种优雅的方法来仅在情境中将itemscope属性插入到我的 html 文档中。
编辑- @martinhepp 建议将属性字符串传递给 Jade 并将其插入标签内。我想这样做,但我不知道怎么做。这是我的尝试和输出。
所以这将是可取的。但是,如果这不起作用或没有人知道该怎么做,对于我不想指定特定模式的页面,设置itemscope为 false 就足够了吗?
这就是我现在正在做的事情。
这会混淆搜索引擎还是他们会认识到我在这里禁用了元素的itemscope和itemtype属性?<html>
rich-snippets - Google 结构化数据标记助手 - 营业时间
我正在尝试使用 Google 的结构化标记助手(突出显示工具)向我的餐厅列表网站添加一些结构化标记。
当我突出显示餐厅的工作日和营业时间时,标记助手告诉我,营业时间“需要”日、月和年(什么?)。无论如何,当我尝试生成 HTML 时,助手会显示嵌入在标记中的错误:
我无法解决这个问题。为什么我要输入日/月/年作为开放时间?开放时间与工作日有关,而不是日/月/年。
好像这个人有同样的问题,但没有发布解决方案。
帮助?