问题标签 [policy-gradient-descent]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
reinforcement-learning - 强化学习中策略梯度下降的奖励函数
我目前正在强化学习的背景下学习策略梯度下降。TL; DR,我的问题是:“奖励函数的限制是什么(在理论上和实践中),对于下面的案例,什么是好的奖励函数?”
详细信息:我想实现一个神经网络,它应该学习使用策略梯度下降来玩一个简单的棋盘游戏。我将省略 NN 的细节,因为它们无关紧要。据我所知,策略梯度下降的损失函数是负对数似然:loss = - avg(r * log(p))
我现在的问题是如何定义奖励r?由于游戏可能有 3 种不同的结果:胜利、失败或平局 - 似乎奖励 1 表示胜利,0 表示平局,-1 表示失败(以及导致这些结果的行动的一些折扣值)将是一个自然的选择。
但是,从数学上讲,我有疑问:
赢得奖励:1 - 这似乎是有道理的。这应该将概率推向 1,因为概率越接近 1,获胜所涉及的移动梯度越小。
抽奖奖励:0 - 这似乎没有意义。这只会抵消方程中的任何概率,并且不可能进行学习(因为梯度应该始终为 0)。
损失奖励:-1 - 这应该是一种工作。它应该将涉及损失的移动的概率推向 0。但是,与获胜案例相比,我担心梯度的不对称性。概率越接近 0,梯度越陡。我担心这会对避免损失的政策产生极其强烈的偏见——以至于获胜信号根本不重要。
tensorflow - 尝试在 Tensorflow 中实现体验回放
我正在尝试在 Tensorflow 中实现体验回放。我遇到的问题是存储模型试验的输出,然后同时更新梯度。我尝试过的几种方法是存储来自 sess.run(model) 的结果值,但是,这些不是张量,就张量流而言不能用于梯度下降。我目前正在尝试使用 tf.assign(),但是,我遇到的困难通过这个例子得到了最好的体现。
我对上述代码的问题如下: - 它在每次运行时打印不同的值,这看起来很奇怪 - 在 for 循环中的每一步都没有正确更新我感到困惑的部分原因是我理解你有运行分配操作以更新先前的引用,但是,我只是无法弄清楚如何在 for 循环的每个步骤中正确执行此操作。如果有更简单的方法,我愿意接受建议。此示例与我当前尝试输入一组输入并根据模型所做的每个预测获得总和的方式相同。如果对上述任何内容的澄清会有所帮助,我将非常乐意提供。
以下是上述代码运行 3 次的结果。
我期待的结果如下:
我感到困惑的主要原因是,有时它提供了所有 9,这让我认为它加载了最后一个分配的值 10 次,但是,有时它加载了不同的值,这似乎与这个理论形成对比。
我想做的是输入一组输入示例并同时计算所有示例的梯度。它需要同时进行,因为所使用的奖励取决于模型的输出,因此如果模型发生变化,结果奖励也会发生变化。
tensorflow - 用于 DRL 动作挑选的多类 Sigmoid
我正在研究深度强化学习问题,我想在最后一层使用 Sigmoid 而不是 softmax。我被困在用于动作选择的内容上。
具体来说,我应该如何替换这段代码的最后两行以及什么:
谢谢
artificial-intelligence - 在股票交易中如何保证股票数量
我正在使用机器学习方法进行股票市场分析和预测,尤其是强化学习。我试图预测空头、多头和持平。(买入、持有、卖出)。(感谢任何建议或材料),目前,我正在向我的代理提供历史数据,代理预测买入、卖出或持有信号。我的问题是如何衡量库存数量。例如,如果我的模型给出了买入信号,如何衡量我应该买多少股票。
python - 如何在小批量上累积我的损失然后计算我的梯度
我的主要问题是;平均损失与平均梯度相同吗?我如何在小批量上累积损失然后计算我的梯度?
我一直在尝试在 Tensorflow 中实现策略梯度,但遇到了无法将所有游戏状态一次输入网络然后更新的问题。问题是如果我降低我的网络大小然后一次在所有帧上训练并取损失的平均值然后它开始很好地收敛。但是如果我在小批量上累积梯度然后平均它们,我的梯度会爆炸并且我的权重溢出。
任何帮助或见解将不胜感激。
还要记住,这是我第一次在这里提问。
python - keras 中的策略梯度只预测一个动作
我在使用 Atari 游戏的 keras 中使用 REINFORCE 算法时遇到问题。在大约 30 集之后,网络收敛到一个动作。但是相同的算法正在使用 CartPole-v1,并在第 350 集后以平均奖励 495,0 收敛。为什么雅达利游戏有问题?我不知道我在损失函数上做错了什么。这是我的代码:
政策示例
网络
训练
offline - Ray - RLlib - 自定义环境错误 - 连续动作空间 - DDPG - 离线体验培训?
为 DDPG 使用离线体验时出错。自定义环境维度(动作空间和状态空间)似乎与 DDPG RLLIB 培训师的预期不一致。
Ubuntu,Ray 0.7 版本(最新的 ray),DDPG 示例,离线数据集。用于离线数据集的采样器构建器。
用这个经验数据估计的 DQN 并运行通过。将环境动作空间更改为连续 (Box(,1)) 并且 DDPG 不起作用。
DDPG 迭代的预期结果。
实际 - 错误:-
reinforcement-learning - 得分函数如何帮助策略梯度?
我正在尝试学习用于强化学习的策略梯度方法,但我停留在分数函数部分。
在搜索函数中的最大或最小点时,我们取导数并将其设置为零,然后寻找保持该方程的点。
在策略梯度方法中,我们通过获取轨迹期望的梯度来做到这一点,我们得到:
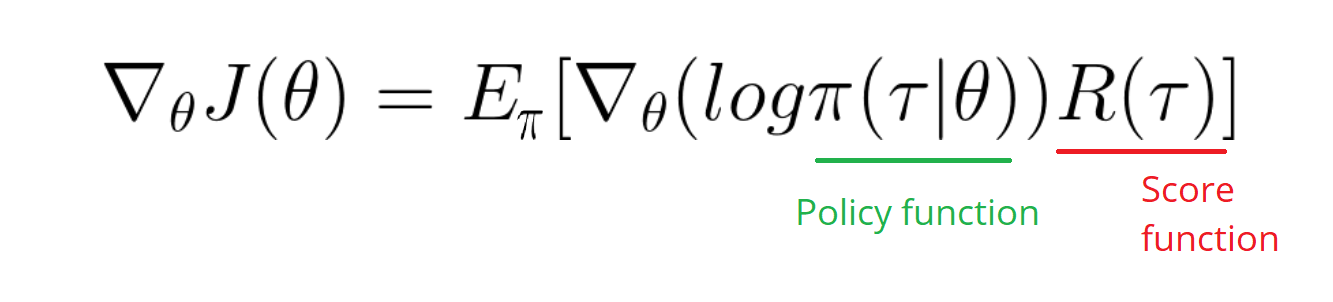{kind=link}
在这里,我无法理解这种对数策略的梯度如何改变分布(通过其参数 θ)以在数学上增加其样本的分数?正如我上面解释的那样,我们不是在寻找使这个目标函数的梯度为零的东西吗?
reinforcement-learning - 我们如何评估策略梯度方法的回报中的每个奖励?
嗨 StackOverflow 社区,
我对强化学习中的策略梯度方法有疑问。
在策略梯度方法中,我们基于从该步骤开始的回报(即总奖励)来增加/减少动作的对数概率。所以如果我们的回报很高,我们会增加它,但我在这一步遇到了问题。
假设我们的回报中有三个奖励。虽然这三个奖励加起来很高,但是第二个奖励实在是太差了。
我们如何处理这个问题?我们如何分别评估每个奖励?这种策略梯度方法是否有替代版本?
tensorflow - 损失策略梯度 - 强化学习
我正在使用策略梯度训练我的网络并将损失定义为:
我不明白的是,损失函数有时是正的,有时是负的。我不明白信号中的这种翻转。对我来说,它应该总是负数,因为我前面有减号tf.reduce_mean.
例子:
这是可能的还是我在我的代码中做错了什么?
谢谢。