问题标签 [libdispatch]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
android - libDispatch 在 Android 上服务于没有 dispatch_main 的主队列
我在 Android 平台上使用 libDispatch (GCD) 开源。因此,大多数复杂耗时的任务都是通过 NDK 完成的(我使用的是 libDispatch)。
对于某些调用,我使用的是 dispatch_async(get_main_queue)...这就是问题所在...我能够在并发队列中运行任务,但不能在主队列中运行。因为这需要调用 dispatch_main() ,我们不能在这里做,因为在这种情况下 Java 线程将被阻塞。那么,是否可以在某个辅助线程上运行 Java UI 并在此处挂钩 dispatch_main() 来为 dispatch_main_queue 提供服务?或者:我是否需要通过 JNI 继续从 JAva 主 UI 线程提供 main_queue 服务?
ios7 - libdispatch 中的这种崩溃是由可达性引起的吗?
谁能告诉我这个崩溃的堆栈是否是由可达性引起的?我正在运行苹果最新的可达性实现,可在https://developer.apple.com/library/ios/samplecode/reachability/Introduction/Intro.html下载
我有一个默认情况下未启用 ARC 的应用程序(它是一个旧版应用程序),但我在每个文件的基础上启用它。我为 Reachability.m 启用了 -fobjc-arc
当我查看这些线程时,我的代码无处可寻。我看到由于 WebHTMLView 发生了一些活动(可能是当前屏幕上的广告网络视图代码;它不是我的)。
在线程 10 上,我看到一个 SCNetworkReachabilityDeallocate,然后是一个 dispatch_semaphore_wait_slow,并且崩溃发生在 libdispatch 中的线程 14 上。
您是否认为此崩溃是由该可达性代码引起的,我是否错误地将 -fobjc-arc 与 Reachability.m 一起使用?
crash - libdispatch _dispatch_semaphore_wait_slow 崩溃
我有时会在 libdispatch 内部发生崩溃,以下回溯源于该SecItemCopyMatching函数。
这次崩溃似乎完全是随机的,我的同事从来没有发生过。它主要发生在 32 位 iOS 模拟器中,但也发生在设备上一次。
我查看了libdispatch 源代码,我可以看到可能会发生这样的崩溃:_dispatch_semaphore_wait_slow()→ DISPATCH_SEMAPHORE_VERIFY_KR→ DISPATCH_CRASH→ _dispatch_hardware_crash()→__builtin_trap()但我真的不明白为什么会这样。
有谁知道发生了什么?
编辑:使用以下回溯运行单元测试时也发生了同样的崩溃:
concurrency - OpenCL 与 Grand Central Dispatch 中的并发编程
随着 OpenCL 2.0 的引入,OpenCL 似乎具备了 Grand Central Dispatch (GCD) 的许多特性,例如 CLang/Apple 样式的块和队列。看看它们各自的功能集,我想知道 OpenCL 是否可以做 GCD/libdispatch 可以做的所有事情,但增加了将计算定向到 GPU 和 CPU 的能力——或者 GCD 是否可以提供更多与众不同的功能来自 OpenCL。
具体来说,我的问题是:
GCD 和 OpenCL 的并发特性有何不同?
如果一起使用它们是有价值的(假设 GCD 提供了附加功能),C 块可以路由到 GCD 队列或 OpenCL 队列吗?如果以 CPU 为目标,是否有理由通过 OpenCL 与直接运行
OpenCL 2.0 是否提供 GCD 样式的负载平衡,可以填充跨越 CPU 和 GPU 的线程?
ios - local dispatch_once value unsafe (transient memory) 触发警告
所以在我的业余时间,我正在研究一个 HTTP 请求“引擎”。我正在尝试构建的是一个“引擎”,它为 iphone 应用程序生成对通用对象的请求/解析响应。
最重要的是,它应该_allways _ 回调 UI。
不管发生了什么(NSURLRequest 超时/解析错误/ NSExcept 引发)(也许有一天也有 SIG?)
所以我用blocks和dispatch_once创造了一些血腥的东西。它有效,但我有这个 Clang 警告。我的意思是我的请求有效,如果出现异常,显然会调用一次 UI。
调用“dispatch_once”使用局部变量“once”作为谓词值。对谓词使用这种瞬态记忆是有潜在危险的
这是问题的核心
那里使用了一些宏:
提前感谢:p
memory-leaks - GCD dispatch_async 内存泄漏?
以下代码将占用 ~410MB 内存,不会再次释放。(使用dispatch_sync代替的版本dispatch_async将需要约 8MB 内存)
我预计会出现高内存使用高峰,但它应该会再次下降......泄漏在哪里?
我试过了:
- 在循环周围和内部添加@autoreleasepool
- 添加
NSRunLoop run到循环
我尝试了几种组合,但从未发现内存减少(即使等待几分钟后)。我知道包含以下语句的 GCD 参考指南:
尽管 GCD 调度队列有自己的自动释放池,但它们不能保证这些池何时耗尽。
此代码中是否存在内存泄漏?如果没有,有没有办法强制队列释放/排出完成的块?
grand-central-dispatch - 使用 GCD 在程序上获取单个主线程
以此为参考,以下示例 {could not} / {would not} 是否有任何理由导致 GCD 线程池仅在主线程上运行?
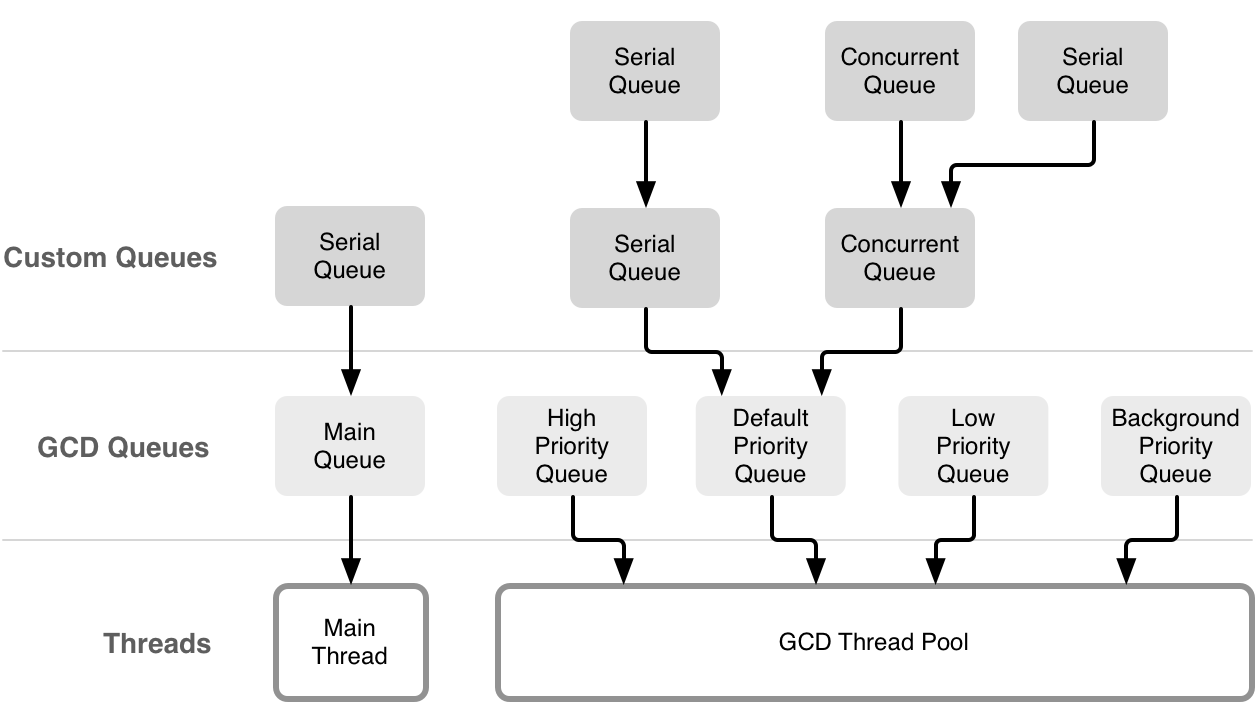{kind=link}
我的理解是,GCD 会尽可能地优化性能,将块(如果有好处)交给任何可用的线程。然而,在 xcode 中监视这一点表明这可能只在主线程上运行。直到调度调用变为async使用第二个线程。
我只想了解何时/为什么可能会或可能不会调用第二个线程。在此之前,我假设总是会调用第二个线程。
c++ - 在 amd64 架构上的 C++ 中将图像缓冲区 blit 到另一个缓冲区的 xy 偏移的最快方法
我有任意大小的图像缓冲区,我以 x,y 偏移量将其复制到相同大小或更大的缓冲区中。颜色空间是 BGRA。我目前的复制方法是:
它运行得很快,但我很好奇是否可以做任何事情来改进它并获得额外的几毫秒。如果它涉及到汇编代码,我宁愿避免这种情况,但我愿意添加额外的库。
objective-c - 取消 dispatch_io_read
我正在使用 GCD 函数解析一个非常大的 CSV 文件(请参见下面的代码)。
如果遇到错误,我想取消dispatch_io_read. 有没有办法做到这一点?
libdispatch - 苹果的 libdispatch 中的凭证是什么意思?
我刚刚阅读了libdispatch的源代码,但我发现有一个词,“凭证”,只是出现了很多次,但我不知道它实际上是什么意思。所以谁能告诉我这个词的真正含义,非常感谢您的大力帮助。
最好的问候轴