问题标签 [dtw]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
r - 动态时间规整 (dtw):为什么某些 Rabiner-Juang 步进模式有效,而另一些则无效
我正在尝试对包括参与者年度报告收入的纵向调查的时间序列数据进行聚类。这些收入轨迹的长度各不相同,因此动态时间扭曲似乎是计算距离矩阵的合适工具。
一些实验表明,这些轨迹如何相互映射取决于分配的步进模式。因此,我想为我的数据集选择最合适的一个。我对动态时间扭曲不是很有经验,所以我决定尝试使用由一系列步进模式创建的距离矩阵对一个小样本进行聚类,看看哪个具有最佳性能指标。
为此,我使用了dtw包的rabinerJuangStepPattern功能,它可以实现 Rabiner 和 Juang(1993 年;我无法获得该文档的副本)中概述的“全面的步骤模式集”。因此,我创建了一个嵌套的 for 循环来遍历 Rabiner-Juang 集的所有配置,发现其中许多都抛出了以下错误:
我已经使用我的数据的玩具版本复制了这个问题,它只尝试计算相对于数据集中第一个参与者的距离:
此代码的输出表明系列 I、V 和 VII 的步进模式正常工作,而系列 II、III、IV 和 VI 的步进模式会产生错误。
因此,我的问题如下:
1)为什么这些家庭中的一些工作,而另一些则产生错误?这是因为某些家庭不适合这种数据,还是我的实施错误?
2) 有谁知道为什么在这个用例中某些步骤模式可能比其他模式更受欢迎的任何理论原因?
非常感谢您的宝贵时间!!!
引文:
Rabiner, LR, & Juang, B.-H. (1993 年)。语音识别基础。新泽西州恩格尔伍德悬崖:普伦蒂斯霍尔。
machine-learning - 在计算 2 个语音样本的 dtw 时出现错误“dtw() got an unexpected keyword argument 'dist'”
我在尝试计算 2 个 wav 文件的 dtw 时收到错误“dtw() got an unexpected keyword argument 'dist'”。我不知道为什么或该怎么做才能解决它。我附上下面的代码。
进口图书馆
导入 librosa.display
y1, sr1 = librosa.load('sample_data/Abir_Arshad_22.wav')
y2, sr2 = librosa.load('sample_data/Abir_Arshad_22.wav')
%pylab 内联
子图(1, 2, 1)
mfcc1 = librosa.feature.mfcc(y1, sr1)
librosa.display.specshow(mfcc1)
子图(1, 2, 2)
mfcc2 = librosa.feature.mfcc(y2, sr2)
librosa.display.specshow(mfcc2)
从 dtw 导入 dtw
从 numpy.linalg 导入规范
dist, 成本, acc_cost, 路径 = dtw(mfcc1.T, mfcc2.T, dist=lambda x, y: norm(x - y, ord=1))
print ('两个声音之间的标准化距离:', dist)
错误发生在倒数第二行。
mfcc - 如何使用 MFCC 转 DTW
我使用单个单词识别。我有一个学习语料库和一个测试语料库,每个单词都有一个音频。多亏了 Praat,我每个字都得到了 MFCC。例如:
然后我比较每个单词并得到 DTW(与 Praat)
但是,我不知道如何“阅读”结果。我怎么知道识别率是多少?如果我认识这个词,我应该采取哪些数据?
python - 如何使用 Kmeans 聚类为数据中的每个组找到最佳 K
我有一个数据集,它有 10 个不同的组和一年中 3 周的销售额。我正在尝试运行一个聚类算法,该算法根据每个组中存在的项目数对每个组进行聚类。基本上,我想以不同的方式对待每一组。
我尝试了一种手动方法,并将每个组的集群设置为相对于具有最多项目数的组,但我想让代码找到每个组的 kmeans 的最佳 k。我不确定如何确定每个组的最佳 k
这是数据:
这是我关于如何找到最佳 k 但运行时间非常高的试验。按照这个速度,运行可能需要一天或更长时间。我正在处理 3500 行数据。有没有更好/最佳的方法来实现我的结果?
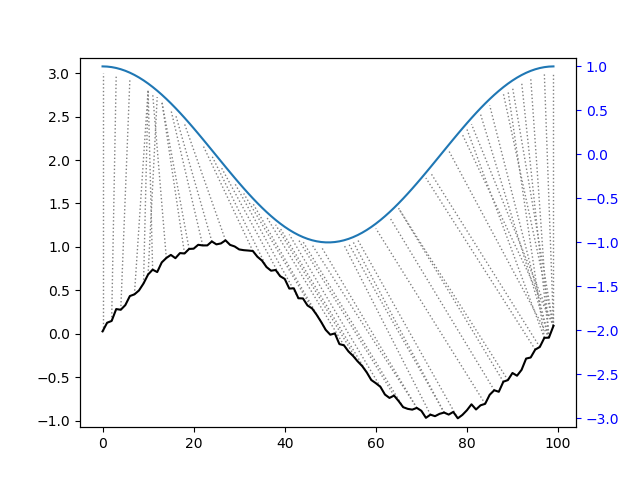
python - 尝试在python中运行和绘制两个数组的动态时间扭曲
我试图了解如何实现动态时间规整(DTW)来比较python中的时间序列曲线。我正在尝试获取两个数组的曲线,并测量它们之间的距离,然后用连接每个节点的线绘制两条曲线,正如您在特征 DTW 图中看到的那样。
我正在尝试以下实验代码:
我正在关注fastdtw文档中的一个示例:https ://pypi.org/project/fastdtw/
我有两个数组:“s”和“z”,我将它们视为时间序列数据,但没有时间戳,并且时间间隔相等。此代码采用我的两个数组“s”和“z”,并计算它们之间的距离,显示为:385.0
所以我可以找到这两条曲线之间的距离,但我不确定如何实际绘制这个距离,比如像这样的图(我相信这被称为“双向”DTW 图):https://动态时间扭曲.github.io/py-images/Figure_2.png
{kind=link}
这是使用fastdtw包,但我也想使用 dtw-python,因为这似乎也是一个不错的选择。我正在尝试使用此dtw-python文档示例:https ://dynamictimewarping.github.io/python/
我正在尝试这个实验代码:
这打印:
不过,这并不能告诉我太多,因为我想揭示曲线之间的 DTW 距离。
我还尝试使用以下方式绘制此 DTW 运行:
但我得到这个错误:ValueError: cannot convert float NaN to integer
这让我感到困惑,因为我认为我的数组中没有任何 NaN 值。
给定我的两个数组,它们基本上用作要绘制为曲线的 y 轴值,我如何找到它们之间的 DTW 距离并将它们绘制为 DTW 距离匹配图?
这个想法是在我的数据集中不断交换新数组并不断比较距离以查看哪些数组具有最相似的曲线形状。我想匹配具有最相似形状的曲线,据我了解,这意味着 DTW 距离最低。
r - 如何根据时间序列形状使用 tsclust 找到最真实的集群?(dtwclust)
最近我开始尝试 dtw 时间序列聚类,以找到更好的数据分区作为全局时间序列预测模型的输入。
由于我对这项技术也很陌生,因此将不胜感激一些提示和建议。
我的第一个问题是,找到最佳集群数量的最佳解决方案是什么。
我确实在我第一次尝试聚类时间序列时写了一个代表。在这种情况下,您可以从图中猜测 k 的数量,它应该是 2。
到目前为止,一切都很好。我只是不明白,为什么将第 4 个系列添加到具有系列 1 和 2 的集群中,它们几乎是直线。DTW 应该基于形状而不是时间序列的体积。
python - 尝试使用 dtw-python 在匹配曲线形状中提高动态时间扭曲的性能
我正在尝试使用dtw-python包以匹配具有不同振荡次数的曲线形状。我有时间序列数据,其中包含许多构成各种曲线形状的线。这些行从 x 轴上的不同时间戳开始,因此我将所有行发送到单独的数组,仅记录它们的 y 轴值,并假设每个观察值以相等的时间间隔出现,因此基本上将每一行作为如果它在同一个时间戳开始。所以这些数组中的每一个都代表不同的线。我想要做的是使用动态时间扭曲(DTW)将每条线配对在一起并分配一个DTW距离分数,以匹配相似/相似的曲线形状。例如,如果我有来自数组 X 和 Y 的两条看似平稳的曲线,那么应该为这对分配比数组 X 和数组 Z 之间的分数低得多的分数,其中 Z 将是波浪形曲线。这就是基本思想。我正在使用 dtw-python 包来执行此操作。这是我到目前为止所拥有的,其中“ts1”和“ts2”是要比较的时间序列数组,“111”和“222”只是数组的不同 ID:
然后我看到了这个:

DTW 得分:1074.0
然后我尝试与波浪形曲线进行比较并收到以下信息:

这获得了 16103.0 的 DTW 分数
好吧,这看起来有道理,高原形状匹配高原形状,波浪形状匹配波浪形状。好的,但是如果我试图匹配两条具有不同振荡次数的波浪形曲线呢?
我试试这个,看看:

得分为 73745.0(这看起来不太好!)
然后我尝试在代码中添加一些参数参数:
然后我看到了这个:

得分为 21365.0(现在要低得多!)
然后我尝试:
我看到了:
 12572.0的分数,现在更低了!我看到最后的振荡被忽略了,这很有趣,因为这可能是我正在寻找的方法。
12572.0的分数,现在更低了!我看到最后的振荡被忽略了,这很有趣,因为这可能是我正在寻找的方法。
最后我尝试:
我看到了:

得分为 19227.0,现在比以前更差,我对这里发生的事情有点困惑。
我的目标是改进我的代码,以便 DTW 函数理解这两条波浪曲线,尽管曲线振荡的数量不同,但实际上是相同的形状。根据我上面的发现,我上面尝试过的这个包的参数参数的哪个组合最适合改进 DTW 函数,以便我的曲线形状尽可能地正确匹配?我正在使用 python 来完成这项任务。
我很难从 dtw-python 的可用文档中找到有关这些论点的含义以及如何使用这些论点的足够背景和文档:https ://dynamictimewarping.github.io/python/#online-documentation
time-series - 序列长度保持动态时间规整
假设我们有两个长度相等的序列,我们希望将它们与动态时间规整 (DTW) 对齐。普通的 DTW 实现会创建比原始序列更长的比对。我正在寻找一种 DTW 的实现,它将两个相等长度的序列作为输入并产生与输入长度相同的对齐。这种实现是否存在,或者其他一些技术是否更适合这个问题?
javascript - 动态时间扭曲(matlab 代码)到 JavaScript?
我在 Matlab 中有一个动态时间规整代码,我需要将它用于我的 Web 应用程序。有什么我可以在 JavaScript 或其他东西中使用 matlab 代码的方法吗?或者一些技巧如何将 matlab 代码重写为 JavaScript?我是这方面的新手。谢谢大家。