问题标签 [deflatestream]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
c# - C# - GZipStream 幻数不正确?
所以,我正在尝试制作一个程序,使用这个将计算机变成代理。除了 gzip/deflate 页面外,这一切都很好。
每当我尝试解压缩时,我都会收到一个 InvalidDataException,说明 GzipHeader 中的幻数不正确。
我使用这个功能:
解压缩数据。错误:

(来源:gyazo.com)
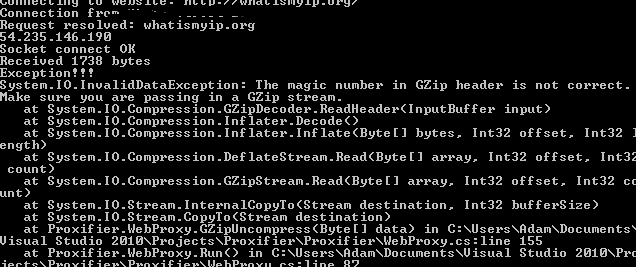{kind=link}
任何帮助,将不胜感激。
编辑:我似乎已经到了某个地方!
正如 usr 建议的那样,我应该编写一个 HTTP 解析器来获取正文并解压缩它。
解析前:http: //pastebin.com/Cb0E8WtT
解析后:http: //pastebin.com/k9e8wMvr
这是我用来到达身体的方法:
但是,我仍然收到一条错误消息,提示“GZip 标头中的幻数不正确。请确保您正在传递 GZip 流。”
编辑(2):从这里复制答案后,我成功地解压缩了身体。
新问题:火狐。

(来源:gyazo.com)
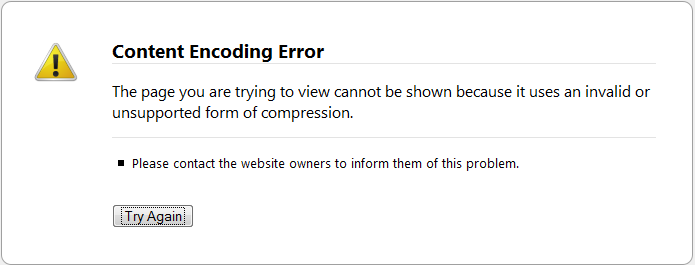{kind=link}
我现在不确定我是否需要解压缩 gzip 页面..
我现在哪里出错了?
c# - 从压缩文件中获取所有未压缩的字节
我创建了一种方法,用于从压缩文件中返回所有未压缩字节。
它工作正常,但它可能会在循环中被调用数百万次。大多数文件都很小,但有些可能高达 100Mb 左右,我不想为所有小文件预分配 100Mb。所以我有几个问题:
- 首先,框架中是否已经有这样的方法了?或者更好的方法来做到这一点?
- 有没有办法获得压缩文件的未压缩大小?(这样我就不必在循环中获取块并且可以调用
Read一次) - 我已经使用过
List<byte>,所以我不必手动重新分配字节数组。有没有更有效的附加字节的方法?
我会把我的新代码放在这里,即使它对大多数人来说可能不是一个难题。但也许有人发现了其他可以改进的地方,比如明确设置缓冲区大小(?)
c# - DeFlateStream.read 如何重定向到 System.Net.ConnectStream.Read?
在调试代码的过程中,在我看来 DeFlateStream.read 重定向到 System.Net.ConnectStream.Read?当我检查 MSDN 源代码时,我很难找到这个重定向。任何人都可以帮我找出这是怎么发生的?谢谢!
vb.net - zLib 从字符串而非文件解压缩到 DeflateStream
我已经尝试了 2 周来从 MP3 ID2,3 文件中解压缩这个用户定义的 TXXX 字符串。
感谢 Adler 博士在我将值转换为字符串时给出的正确答案。
我试过 MS DeflateStream 和 GZipstream 都没有成功。
我看到的每个示例都使用流文件。我没有使用文件,我在数组或字符串变量中都有上面的 zLib 代码。
GZipstream 给了我“没有幻数”,而 Deflatestream 给了我“块长度与其补码不匹配”。
我读了这篇文章: http: //george.chiramattel.com/blog/2007/09/deflatestream-block-length-does-not-match.html
尝试从头部删除字节,没有运气。(我阅读了无数篇关于向 Deflatestream 发送字符串的文章,但又一次“不走运”!
我有上面的字符串,那么如何将它发送到 Deflatestream?我会发布我尝试过的两百个不同的代码示例,但这很愚蠢。
有趣的是,我在不到两周的时间里构建了我的 webAudio 提示标记编辑器,这是我做的最后一件事(我的程序必须从一个具有人类已知最差音频编辑器的程序中获取标记位置(他们嵌入了它们)出于某种(不好的)原因在 MP3 中)。因此,我编写了自己的代码来更改音频提示标记,这样我就可以节省数小时的工作挫败感。但是,我最近睡眠不足。
请帮我睡一觉。
c# - 不能用单声道压缩?
我正在尝试像这样以单声道压缩一些数据:
我只是得到异常“CreateZStream”。没有内在的例外。这里发生了什么 ?
堆栈跟踪:
c# - DeflateStream / GZipStream 到 CryptoStream,反之亦然
我想使用以下简单代码一次性压缩和加密文件:
以下行将加密和压缩文件恢复为原始文件:
这也适用于 GZipStream。
xml - 使用 VB.net 将二进制数据转换为 XML
我正在尝试从 SQL 中检索 VARBINARY 列,然后将二进制数据转换为 XML。我可以轻松检索数据并将其转换为 XML,但最近它开始截断转换后的 XML 文件的最后几个字符。下面是代码和说明。
这就是我检索二进制数据的方式。
然后,我将其转换为 MemoryStream。
然后,我解压缩它(因为它处于压缩模式)。
但是,它会截断 xml 文件中的最后几个字符。(XMLdataReader 只是一个包含文件名的字符串)。下面是截断的结果。我希望它完整,因为我想将该 XML 转换为数据表。
你们能帮忙吗。我用谷歌搜索了很多,直到我确定我只是在兜圈子,我才提出问题。除此之外,无论如何我可以将这个解压缩的二进制数据转换为 XML,而无需将其保存在文件中,然后将其转换为数据表。多谢你们。:)
xml - 压缩方法丢失一个或多个字节 VB.NET
以下是我用于压缩和解压缩目的的代码。我的目标是将数据表转换为 XML,然后转换为二进制压缩格式,然后将其读回并将二进制转换回 XML。因此,基本上,我将 XML 转换为二进制压缩,然后将压缩二进制转换回 XML。从逻辑上讲,数据大小应该相同,但新解压缩的 XML 文件由于某种原因丢失了一个字节或更多字节。你们能帮帮我吗。
在第一个 XML(原始文件)中,结束行正确地结束了 documentelement 标记,就像在新解压缩的 XML 文件中的DocumentElement但一样,此标记中缺少最后几个字符,看起来像遵循DocumentElem 这在我尝试时会导致错误再读一遍。请协助。
c# - DeflateStream.ReadAsync(.NET 4.5 System.IO.Compression)读取的字节返回值与等效的读取方法不同?
在将一些旧代码转换为在 c# 中使用异步时,我开始看到 DeflateStream 的 Read() 和 ReadAsync() 方法的返回值变化问题。
我认为从同步代码的过渡就像
bytesRead = deflateStream.Read(buffer, 0, uncompressedSize);
到它的等效异步版本
bytesRead = await deflateStream.ReadAsync(buffer, 0, uncompressedSize);
应该总是返回相同的值。
查看添加到问题底部的更新代码 - 以正确的方式使用流 - 因此使初始问题无关紧要
我发现经过多次迭代后,这并不成立,在我的具体情况下,导致转换后的应用程序出现随机错误。
我在这里错过了什么吗?
下面是简单的重现案例(在控制台应用程序中),在迭代 #412Assert的方法中将为我中断ReadAsync,输出如下所示:
我的问题是,为什么此时该DeflateStream.ReadAsync方法返回 453 个字节?
注意:这只发生在某些输入字符串上——其中的大量StringBuilder内容CreateProblemDataString是我能想到的为这篇文章构建字符串的最佳方式。
更新代码以正确地将流读入缓冲区
输出现在看起来像这样:
powershell - How to read meta data of an epub with XmlReader and DeflateStream in a powershell Cmdlet
I've tried to write a commandlet for getting meta information from an epub file. I would like to use the commandlet like this:
So Get-EpubMetaInfo should
- open the epub file (which is actually a simple a zip archive)
- read meta info from it
- close the opened stream
- passthru the meta infos
Here is the relevant part of the process block:
This works fine if I don't pipe it into the Rename-Item. With Rename-Item I get the following error:
What should I do, to close the zip properly?
The whole code can be examined here https://github.com/mattia72/powershell
Update:
If I call $Reader.Close() after $Stream.Close() then the first rename is ok, the second fails again, and so on...
It may be an asynchronous reader issue?