我需要了解由 2 个主成分创建的散点图传达的内容。
我正在研究“sklearn.datasets”库中的“波士顿住房”数据集。我对来自“sklearn.decomposition”库的预测变量和使用的“PCA”进行了标准化,以获得 2 个主成分并将它们绘制在图表上。
现在我想要的只是帮助用简单的语言解释情节的内容。在此处输入图像描述
PC 是特征的线性组合。基本上,您可以根据数据中捕获的差异对 PC 进行排序,并从最高到最低进行标记。PC1 将包含大部分方差,然后是 PC2 等。因此,对于每台 PC,它都知道它准确解释了多少方差。但是,当您在 2D 中散点图数据时,就像您在波士顿住房数据集中所做的那样,很难说“多少”和“哪些”功能在 PC 中做出了贡献。这是“双情节”发挥作用的地方。双标图可以通过向量的角度和长度为每个特征绘制其贡献。当您这样做时,您不仅会知道顶级 PC 解释了多少差异,而且还会知道哪些功能最重要。
试试“pca”库。这将绘制解释的方差,并创建一个双标图。
pip install pca
from pca import pca
# Initialize to reduce the data up to the number of componentes that explains 95% of the variance.
model = pca(n_components=0.95)
# Or reduce the data towards 2 PCs
model = pca(n_components=2)
# Fit transform
results = model.fit_transform(X)
# Plot explained variance
fig, ax = model.plot()
# Scatter first 2 PCs
fig, ax = model.scatter()
# Make biplot
fig, ax = model.biplot(n_feat=4)
每个主成分都可以理解为数据集中所有特征的线性组合。例如,如果您有三个变量 A、B 和 C,那么主成分的一种可能性可以通过 0.5A + 0.25B + 0.25C 来计算。一个值为 [1, 2, 4] 的数据点最终会在主成分上得到 0.5*1 + 0.25*2 + 0.25*4 = 2。
通过确定在数据中产生最高方差的特征组合来提取第一个主成分。这大致意味着我们调整每个变量的乘数(0.5、0.25、0.25),以使所有观察值之间的方差最大化。
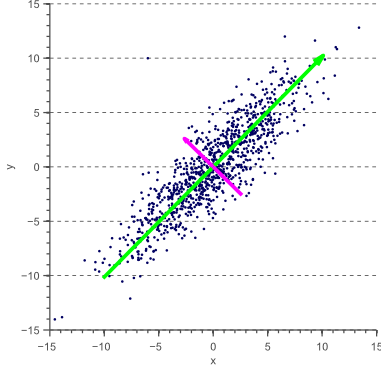
二维数据的第一个主成分(绿色)和第二个(粉红色)通过该图中数据的线条进行可视化
{kind=link}
{kind=link}