我正在尝试以非常简化和简单的方式Canny Edge Detection使用OpenCL 内核来实现。
我正在使用原始SobelFilter内核来执行非最大抑制和阈值处理等步骤。
但是我对达到像素并对其进行数学计算感到迷茫:
__kernel void sobel_filter(__global uchar4* inputImage, __global uchar4* outputImage)
你能给我一些想法或展示简单的例子来实现这一点吗?将不胜感激。问候。
我正在尝试以非常简化和简单的方式Canny Edge Detection使用OpenCL 内核来实现。
我正在使用原始SobelFilter内核来执行非最大抑制和阈值处理等步骤。
但是我对达到像素并对其进行数学计算感到迷茫:
__kernel void sobel_filter(__global uchar4* inputImage, __global uchar4* outputImage)
你能给我一些想法或展示简单的例子来实现这一点吗?将不胜感激。问候。
Sobel 滤波器在内核执行中本质上可分离为 X 和 Y 维度。因此,可以仅在 X 维度上或仅在 Y 维度上或两者都在同一内核循环中进行扫描,以实现边缘特征检测。
azer89在此处使用用户的解决方案:图像处理 - 实施 Sobel 过滤器
我准备了这个内核:
__kernel void postProcess(__global uchar * input, __global uchar * output)
{
int resultImgSize=1024;
int pixelX=get_global_id(0)%resultImgSize; // 1-D id list to 2D workitems(each process a single pixel)
int pixelY=get_global_id(0)/resultImgSize;
int imgW=resultImgSize;
int imgH=resultImgSize;
float kernelx[3][3] = {{-1, 0, 1},
{-2, 0, 2},
{-1, 0, 1}};
float kernely[3][3] = {{-1, -2, -1},
{0, 0, 0},
{1, 2, 1}};
// also colors are separable
int magXr=0,magYr=0; // red
int magXg=0,magYg=0;
int magXb=0,magYb=0;
// Sobel filter
// this conditional leaves 10-pixel-wide edges out of processing
if( (pixelX<imgW-10) && (pixelY<imgH-10) && (pixelX>10) && (pixelY>10) )
{
for(int a = 0; a < 3; a++)
{
for(int b = 0; b < 3; b++)
{
int xn = pixelX + a - 1;
int yn = pixelY + b - 1;
int index = xn + yn * resultImgSize;
magXr += input[index*4] * kernelx[a][b];
magXg += input[index*4+1] * kernelx[a][b];
magXb += input[index*4+2] * kernelx[a][b];
magYr += input[index*4] * kernely[a][b];
magYg += input[index*4+1] * kernely[a][b];
magYb += input[index*4+2] * kernely[a][b];
}
}
}
// magnitude of x+y vector
output[(pixelX+pixelY*resultImgSize)*4] =sqrt((float)(magXr*magXr + magYr*magYr)) ;
output[(pixelX+pixelY*resultImgSize)*4+1]=sqrt((float)(magXg*magXg + magYg*magYg)) ;
output[(pixelX+pixelY*resultImgSize)*4+2]=sqrt((float)(magXb*magXb + magYb*magYb)) ;
output[(pixelX+pixelY*resultImgSize)*4+3]=255;
}
索引在这里与 4 相乘,因为它们被解释为uchar 数组作为内核参数。uchar是 OpenCL 中的一个字节(至少对于我的系统而言)。
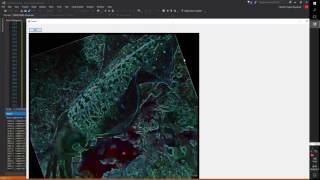
这是一个视频:
如果它也适用于您,您应该接受azer89的解决方案。但这不是很优化,对于低端 GPU 可能需要 1-2 毫秒,而对于 1024x1024 图像只有 CPU 则更长时间。图像数据使用字节数组(C# 语言)发送到 OpenCL 缓冲区(不是图像缓冲区),内核启动选项为:
这里的 kernelx 和 kernely 2D 数组也float使得它们char可以使其更快。如果结果看起来比预期的要丰富多彩,您也可以检查结果(钳位,除法,...)。主机端表示/解释对于处理颜色的下溢和溢出也很重要。
ARM 计算库具有 Canny 实现 Canny CL 内核