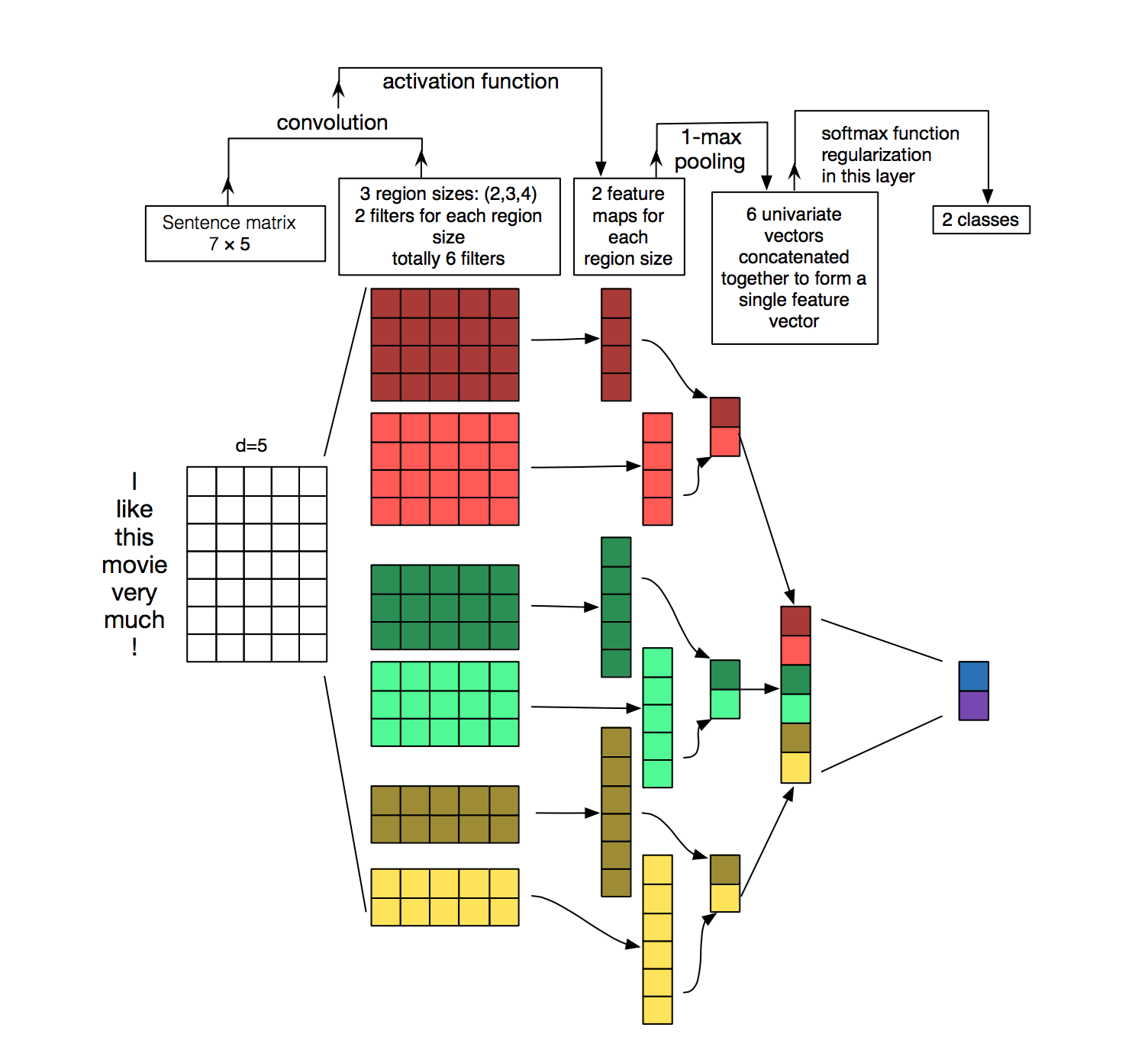
我正在尝试使用 CNN实现文本分类模型。据我所知,对于文本数据,我们应该使用 1d Convolutions。我在 pytorch 中看到了一个使用 Conv2d 的示例,但我想知道如何将 Conv1d 应用于文本?或者,实际上不可能?
{kind=link}
这是我的模型场景:
Number of in-channels: 1, Number of out-channels: 128
Kernel size : 3 (only want to consider trigrams)
Batch size : 16
因此,我将提供形状张量 <16, 1, 28, 300>,其中 28 是句子的长度。我想使用 Conv1d,它将为我提供 128 个长度为 26 的特征图(因为我正在考虑三元组)。
我不确定如何为此设置定义 nn.Conv1d() 。我可以使用 Conv2d 但想知道是否可以使用 Conv1d 实现相同的效果?