您提出了有效点,但是您对标准化及其含义并不完全清楚,例如
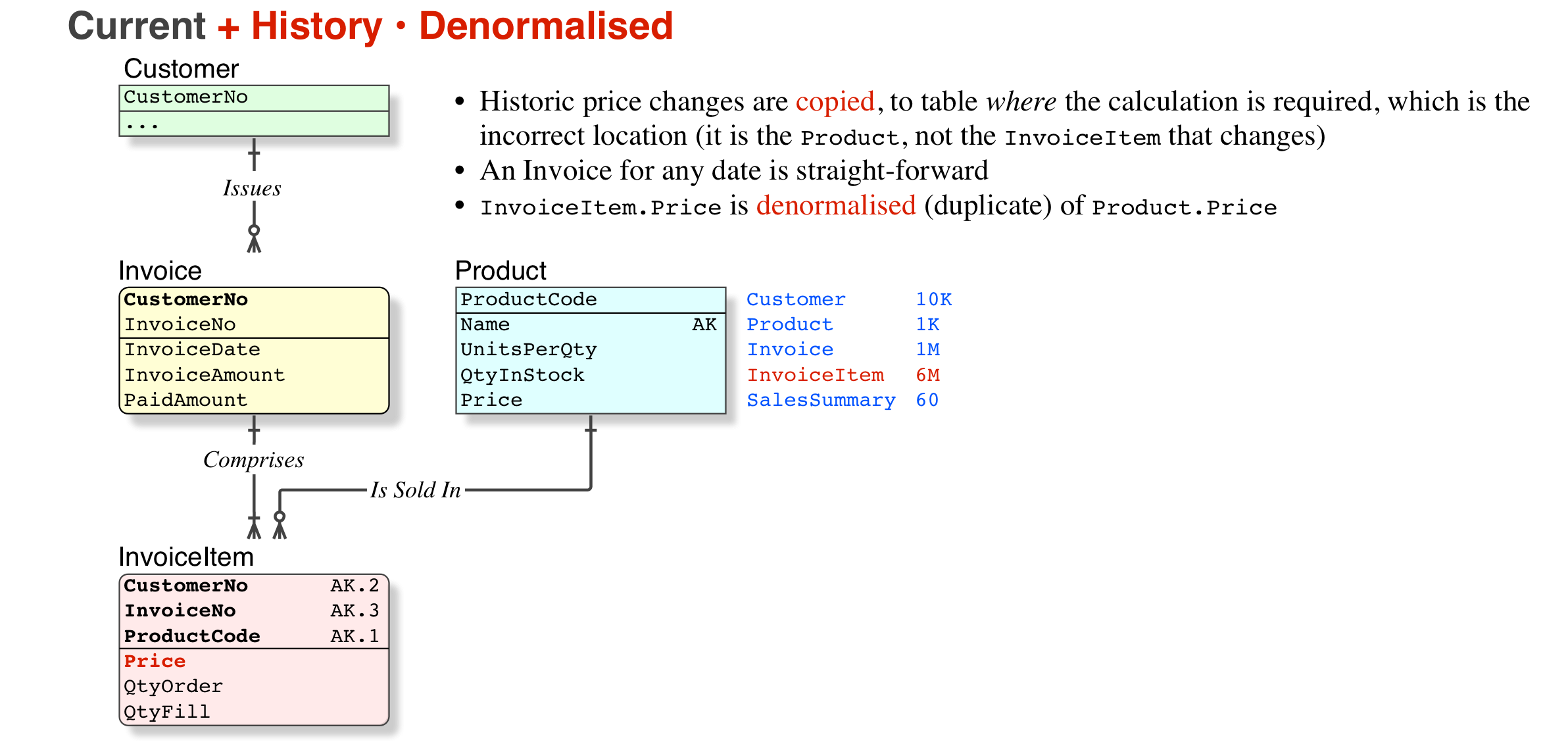
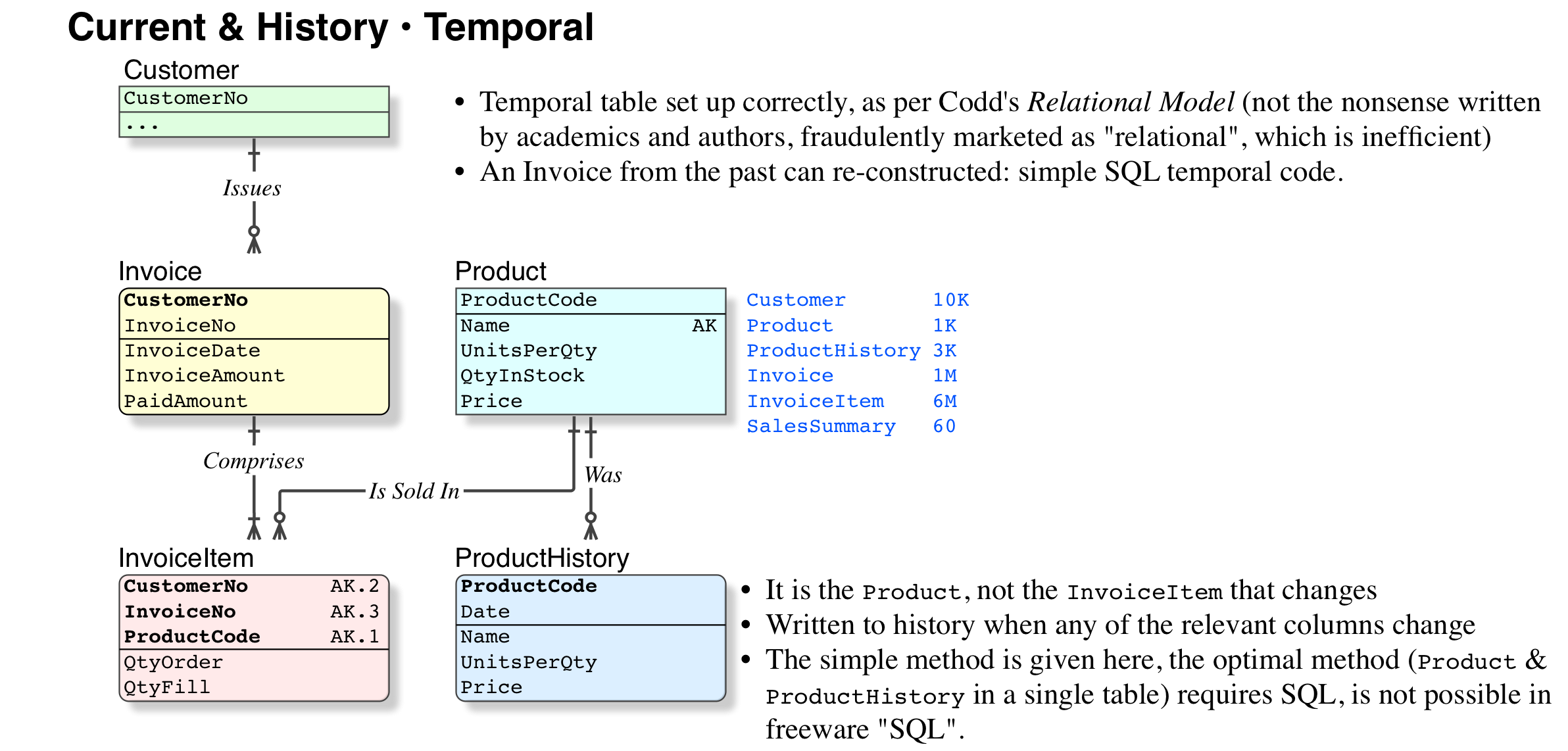
1) 声称保留发票原样使数据非规范化的说法是完全错误的。让我们以价格为例 - 如果您有一个业务要求,即您必须保留价格历史记录,那么只保留当前价格是错误的,它违反了要求。而且它与规范化无关,它根本没有设计好。非规范化是关于在您的模型(和其他工件)中引入歧义的可能性 - 在这种情况下,您根本没有正确地建模您的问题空间。
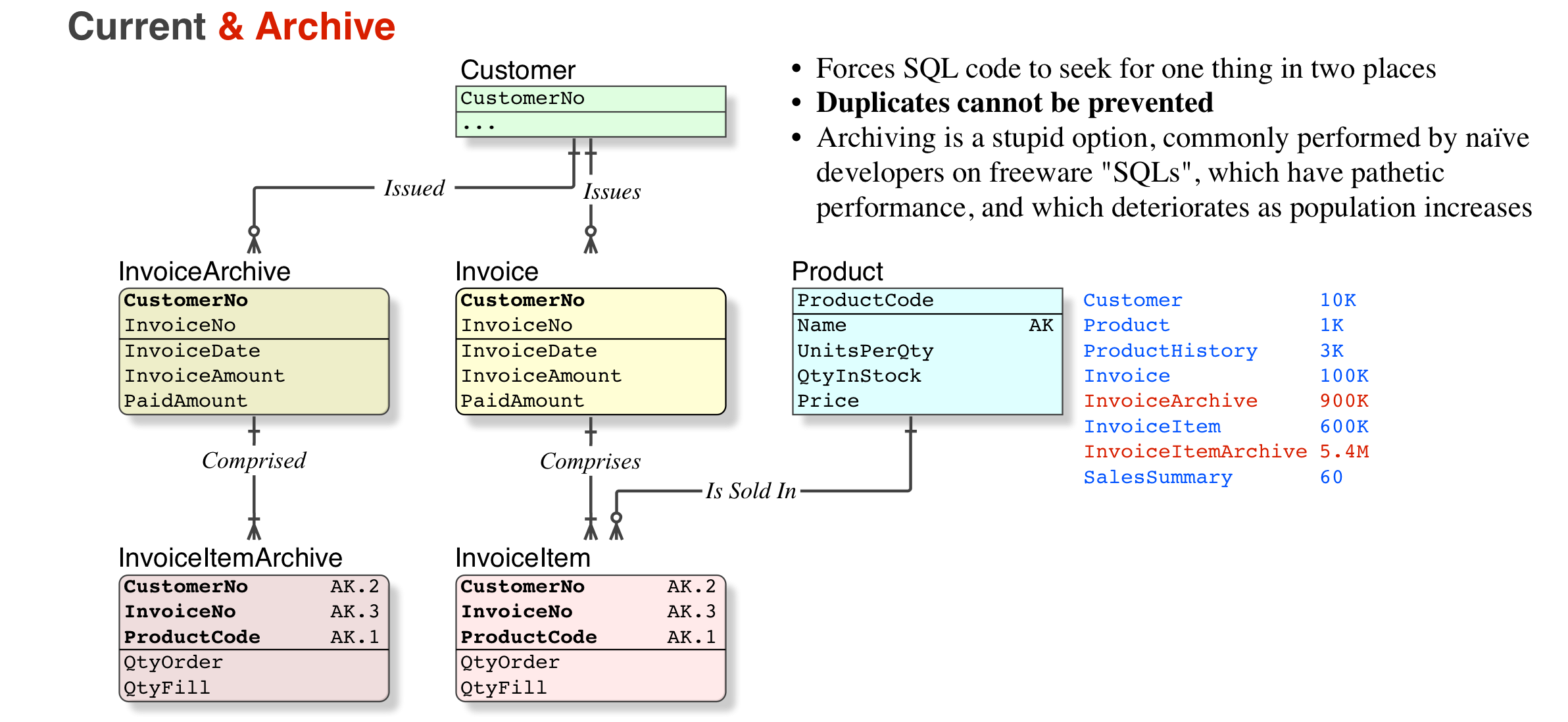
对数据库进行建模以支持时态数据(或版本控制和/或将数据库区域划分为存档/时态和工作集)并没有错。
看规范化而不看语义(就需求而言)是不可能的。
另外,如果您的高级开发人员看不出区别,那么我猜他没有在 RDBMS 开发方面获得资历;)
2)第二部分确实是非规范化。但是,如果您遇到过认真宣扬规范化的高级 DB 分析师,您会听到他/她说,只要您有意识地进行非规范化并确保有利于超重缺陷并且异常不会咬您,就可以完全接受非规范化。他们还将告诉您规范化逻辑模型,并且在物理模型中,您可以出于各种目的(性能、维护等)偏离理想值。在我的书中,规范化的主要目的是让你没有隐藏的异常(例如,参见这篇关于5NF的文章)
即使在规范化的数据库上,甚至是规范化的最大传播者也允许缓存中间结果——您可以在应用程序层(作为某种缓存)进行缓存,也可以在数据库级别进行缓存,或者您可以拥有一个数据仓库这样的目的。这些都是有效的选择,与规范化逻辑模型无关。
此外,至于您的会计师 - 您应该能够说服他他所声称的不是一个好的测试并开发一组测试(可能与他一起),这将在没有用户干预的情况下自动化系统测试并为您提供对您的系统没有错误的信心更高。
另一方面,我知道要求用户输入重复信息的系统,例如在输入实际行之前或之后输入发票上的行数,以确保输入是完整的。此数据是“重复的”,如果您有一个可以验证输入的过程,则不必存储它。如果该过程稍后出现,则允许存储“非规范化”数据 - 再次,语义证明它是合理的,您可以将模型视为规范化。(了解这个概念是有益的)
编辑:
(2)中的“非规范化”一词是不正确的,如果您查看范式的正式定义,并且如果您认为如果设计破坏了任何范式,则该设计是非规范化的(对某些人来说,这是显而易见的并且没有其他方式)。
不过,您可能希望习惯这样的想法,即很多人而不是不必要的无用文本将使用术语规范化来尝试减少数据库中的冗余(例如,您会发现科学论文,通过我并不是说它们一定是正确的,只是作为一个警告,即调用派生属性是一种非规范化的形式是很常见的,请参见此处)。
如果你想参考一些更连贯和公认的权威(同样,并非所有人都认可),也许CJDate的话可以做出明确的区分:
许多设计理论都与减少冗余有关。归一化减少了relvars内的冗余,正交性减少了relvars之间的冗余。
深度引用自数据库:从业者的关系理论
在下一页
正如未能始终规范化意味着冗余并可能导致某些异常一样,未能坚持正交性也是如此。
因此,跨 relvar 的冗余的正确术语是正交性(基本上所有范式都谈论单个 relvar,因此如果您严格查看规范化,它永远不会因为两个不同 relvar 之间的依赖关系而提出任何改进)。
无论如何,当您考虑数据库设计时,其他重要概念之一也是逻辑数据库模型和物理数据库模型之间的区别。许多在物理级别上有用的东西,例如带有小计或索引的表在逻辑模型中没有位置 - 您尝试建立和调查您尝试建模的概念之间的关系。这就是为什么你可以说它们是允许的并且它们不会破坏设计。
在什么是逻辑模型和什么是物理模型上,界限有时会有些模糊。特别好的例子是带有小计的表格。要将其视为物理实现的一部分并在逻辑级别上忽略它,您必须:
- 确保用户(和应用程序)不能以与其谓词不一致的方式直接更新小计表(换句话说,在小计过程中存在错误)
- 确保用户(和应用程序)在不更新小计的情况下无法更新它们所依赖的表(换句话说,某些应用程序不会在不更新总计的情况下从明细表中删除一行)
如果您违反上述任何规则,您最终将得到不一致的数据库,这将提供不一致的事实。(在这种情况下,如果您想正式设计一个程序来修复或检查引起的问题,您不会认为它只是一个附加表,它会存在于逻辑级别;它不应该存在)。
此外,规范化始终取决于您尝试建模的语义和业务规则。例如,DBAPerformance 给出了一个例子,其中将 存储TaxAmount在事务表中不是非规范化设计,但他没有提到这取决于您尝试建模的系统类型(这很明显吗?);例如,如果交易有另一个名为TaxRate它的属性,它通常会被非规范化,因为对一组非关键属性(TaxAmount = Amount * TaxRate => FD: Amount,TaxRate -> TaxAmount)存在功能依赖,其中一个应该被删除或保证是一致的。
显然,您可能会说,但是,如果您正在构建的系统是为审计公司而构建的,那么您可能没有功能依赖性——他们可能正在审计正在使用手动计算或软件有问题或必须有能力记录不完整数据的人并且最初的计算可能是错误的,作为审计公司,您必须记录发生的事实。
因此,由需求确定的语义(谓词)将影响是否有任何范式被破坏 - 通过影响功能依赖关系(换句话说,当您争取规范化数据库时,正确建立功能依赖关系是建模的非常重要的部分)。