我正在尝试通过将光栅化 PDF 转换为 PNG 格式然后使用 OpenCV 分析图像来检测光栅化 PDF 上的 CText 字段。
到目前为止,我已经能够使用以下代码生成一组相对准确的角:
image = cv2.imread(img_filename)
# add 10px border padding (white)
image = cv2.copyMakeBorder(image, 10, 10, 10, 10, cv2.BORDER_CONSTANT, value=[255, 255, 255])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = np.float32(gray)
corners = cv2.cornerHarris(gray, 2, 3, 0.1)
cond = corners>0.0001*corners.max()
image[cond] = [0,0,255]
cv2.imshow('dst', image)
cv2.waitKey(0)
这是我的输入:

这是输出:
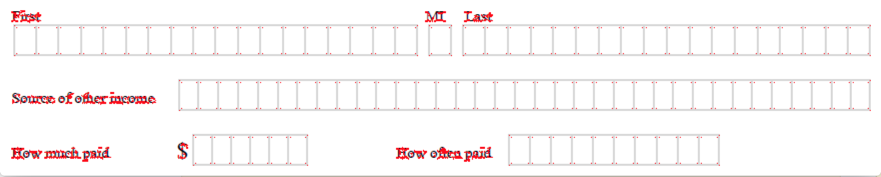
我希望能够从这组点中计算出哪些点是矩形的一部分。这将涉及检查每个角点是否存在其他三个角点:
- 同一行中的一个点(大约),但不同的列
- 同一列中的一个点(大约),但不同的行
- 上面 (1) 中的列和上面 (2) 中的行的点
目标是生成一组矩形,其中不包含任何 [显着] 数量的角点,除非这些角点本身属于一个矩形(在每个内部矩形的边界矩形的情况下,例如。 )
在 OpenCV 中执行此操作的最有效方法是什么?