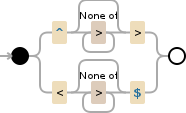
Try using a capturing group on anything between the characters you don't want. For example,
/>([\w|\d]+@[\w\d]+.\w+)</
Basically, any part that the regexp inside () matches is saved in a capturing group. This one matches anything that's inside >here< that starts with a bunch of characters or digits, has an @, has one or more word or digit characters, then a period, then some word characters. Should match any valid email address.
If you need characters besides >< to be matched, make a character class. That's what those square bracketed bits are. If you replace > with [.,></?;:'"] it'll match any of those characters.
Demo (Look at the match groups)