我想创建一些处理编码的示例程序,特别是我想使用宽字符串,例如:
wstring a=L"grüßen";
wstring b=L"שלום עולם!";
wstring c=L"中文";
因为这些是示例程序。
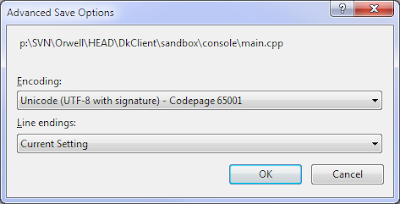
对于将源代码视为 UTF-8 编码文本的 gcc,这绝对是微不足道的。但是,直接编译在 MSVC 下不起作用。我知道我可以使用转义序列对它们进行编码,但我更愿意将它们保留为可读文本。
是否有任何选项可以指定为“cl”的命令行开关以使其工作?有没有像 gcc'c 这样的命令行开关-finput-charset?
如果不是,您如何建议使文本对用户自然?
注意:将 BOM 添加到 UTF-8 文件不是一个选项,因为它变得无法被其他编译器编译。
注2:我需要它在 MSVC 版本 >= 9 == VS 2008 中工作
真正的答案:没有解决方案