我正在尝试对版本历史进行关联挖掘。我在 mysql 中有我的交易数据。Weka apriori 算法需要一定格式的 arff 或 csv 文件。它必须有每个项目的列。对于事务中的每个项目,值将被指定为 TRUE 或 FALSE。我正在寻找一种使用 Weka InstanceQuery 创建此文件的方法。如果交易数据很大,还有哪些选择。
4536 次
2 回答
1
我可以回答第二部分:交易数据巨大时的选项。Weka 是一个很好的软件,但是它们的先验实现速度非常慢。我推荐http://fimi.ua.ac.be/src/上的实现(我使用了 Ferenc Bodon 列表中的第一个)。
Bodon 的实现使用 Trie 数据结构而不是 Weka 使用的哈希表。正因为如此,我在工作中发现,Weka 需要 3 天时间才能完成 Bodon 的实现可以在不到一个小时内完成的事情(是的,差别如此之大!!)。
此外,Bodon 的实现使用了一种简单的输入格式:每笔交易一行,项目用空格分隔。
于 2013-03-29T00:04:10.897 回答
0
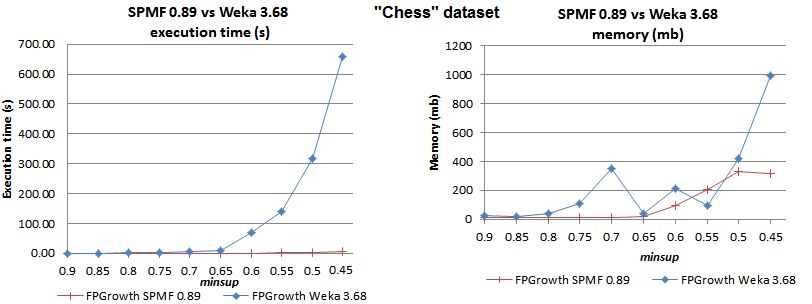
如果您想要 FPGrowth 或 Apriori 的快速 Java 实现,请查看我的项目 SPMF。SPMF 中的 FPGrowth 实现在某些数据集上比 Weka 实现高出两个数量级。例如,您可以看到以下性能比较:
http://www.philippe-fournier-viger.com/spmf/performance/chess_fpgrowth_spmf_vs_weka.png
{kind=link}
这是主要的项目网页:
http://www.philippe-fournier-viger.com/spmf/index.php
此外,请注意,SPMF 提供了超过 50 种算法用于项集挖掘、关联规则挖掘、顺序模式挖掘等。此外,SPMF 的 GUI 版本还支持 Weka 使用的 ARFF 格式。
于 2013-06-06T03:19:52.700 回答