考虑以下示例数据集:
member like deposit age
1 1 9997 22
2 2 892 23
1 1 267 34
1 9 1728 54
3 1 9999 22
1 2 2123 34
9 2 445 13
1 1 928 22
1 1 276 34
2 1 . 23
2 1 3728 45
3 2 3652 34
. 1 451 35
. 1 231 67
2 9 234 17
3 2 3872 37
1 1 102 45
1 1 676 56
3 . . 35
2 . 9999 67
所有变量都是数字。变量标签和值标签是:
label var member "Are you a member of the club?"
label var like "Do you like it?"
label var deposit "How much in your account?"
label var age "Age"
label values member memberl, nofix
label define memberl 1 "member" 2 "nonmember" 3 "waiting" 9 "Refuse to answer"
label values like like, nofix
label define like 1 "like" 2 "don't like" 9 "don't know"
label value deposit dmoney, nofix
label define dmoney 9997 "N/A" 9999 "don't know"
年龄变量没有系统缺失值,也没有使用定义的缺失值。每个变量都有一个注释(调查问题编号):
notes member: QT35
notes like: QR22
notes deposit: Q6
notes age: info3
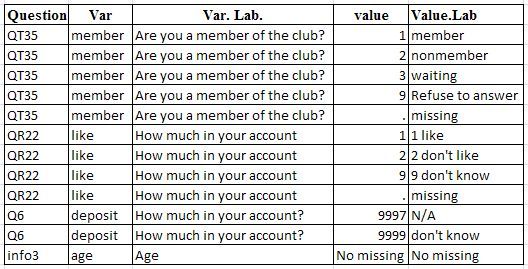
我的目标是将这些信息导出到单个数据集(或 Excel 表)中,如下所示。
以数据集形式:
http://i1279.photobucket.com/albums/y531/tpbest33/wanted_output_dataform_zps52953ecf.jpg
{kind=link}
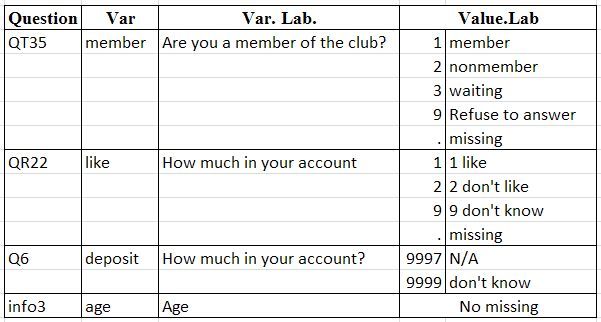
或者,在 Excel 表格形式中(这是可取的。):
http://i1279.photobucket.com/albums/y531/tpbest33/wanted_output_zps2c35208e.jpg
{kind=link}
(抱歉,我不知道如何编写 html 代码来显示图像。)
我正在试验几个 Stata 基本命令和包:.uselabel、.labutil2、.valtovar. 等。任何帮助,将不胜感激!