在内存被刷新之前,我的 CUDA 程序在执行期间崩溃了。结果,设备内存仍然被占用。
我在nvidia-smi --gpu-reset不支持的 GTX 580 上运行。
放置cudaDeviceReset()在程序的开头只会影响进程创建的当前上下文,不会刷新之前分配的内存。
我正在使用该 GPU 远程访问 Fedora 服务器,因此物理重置非常复杂。
所以,问题是 - 在这种情况下有什么方法可以刷新设备内存?
在内存被刷新之前,我的 CUDA 程序在执行期间崩溃了。结果,设备内存仍然被占用。
我在nvidia-smi --gpu-reset不支持的 GTX 580 上运行。
放置cudaDeviceReset()在程序的开头只会影响进程创建的当前上下文,不会刷新之前分配的内存。
我正在使用该 GPU 远程访问 Fedora 服务器,因此物理重置非常复杂。
所以,问题是 - 在这种情况下有什么方法可以刷新设备内存?
检查什么正在使用您的 GPU 内存
sudo fuser -v /dev/nvidia*
您的输出将如下所示:
USER PID ACCESS COMMAND
/dev/nvidia0: root 1256 F...m Xorg
username 2057 F...m compiz
username 2759 F...m chrome
username 2777 F...m chrome
username 20450 F...m python
username 20699 F...m python
然后杀死你不再需要的htopPID
sudo kill -9 PID.
在上面的例子中,Pycharm 吃掉了很多内存,所以我杀死了 20450 和 20699。
第一类
nvidia-smi
然后选择要杀死的PID
sudo kill -9 PID
尽管在特殊情况下没有必要这样做,但在 linux 主机上执行此操作的推荐方法是通过以下方式卸载 nvidia 驱动程序
$ rmmod nvidia
具有适当的root权限,然后重新加载它
$ modprobe nvidia
如果机器正在运行 X11,则需要事先手动停止,然后重新启动。驱动程序初始化过程应消除设备上的任何先前状态。
此答案已从评论中收集并发布为社区 wiki,以将此问题从 CUDA 标签的未回答列表中删除
我也有同样的问题,我在quora中看到了一个很好的解决方案,使用
sudo kill -9 PID.
请参阅https://www.quora.com/How-do-I-kill-all-the-computer-processes-shown-in-nvidia-smi
对于使用 python 的人:
import torch, gc
gc.collect()
torch.cuda.empty_cache()
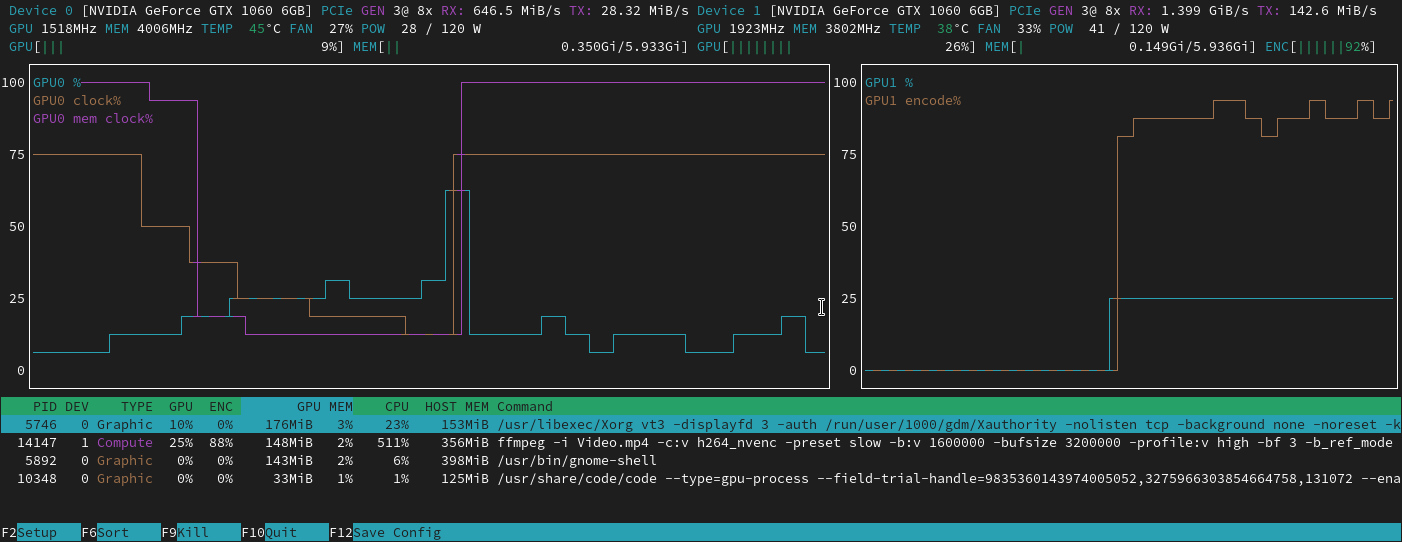
也可以使用nvtop,它提供了一个与 非常相似的界面htop,但显示了您的 GPU 使用情况,并带有漂亮的图表。您也可以直接从这里终止进程。
这是其 Github 的链接:https ://github.com/Syllo/nvtop
在macOS (/ OS X) 上,如果其他人遇到操作系统明显泄漏内存的问题:
对于操作系统:UBUNTU 20.04 在终端类型中
nvtop
如果直接杀死消耗活动不起作用,则查找并记下 GPU 使用率最高的活动 PID 的确切数量。
sudo kill PID -number