您可能需要估计 ctr 的置信区间表示。威尔逊得分区间是一个很好的尝试。
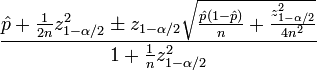
您需要以下统计数据来计算置信度分数:
\hat p是观察到的 ctr(#clicked 与 #impressions 的分数)n是总展示次数zα/2是(1-α/2)标准正态分布的分位数
python中的一个简单实现如下所示,我使用z(1-α/2) =1.96,对应于95%的置信区间。我在代码末尾附上了 3 个测试结果。
# clicks # impressions # conf interval
2 10 (0.07, 0.45)
20 100 (0.14, 0.27)
200 1000 (0.18, 0.22)
现在您可以设置一些阈值来使用计算的置信区间。
from math import sqrt
def confidence(clicks, impressions):
n = impressions
if n == 0: return 0
z = 1.96 #1.96 -> 95% confidence
phat = float(clicks) / n
denorm = 1. + (z*z/n)
enum1 = phat + z*z/(2*n)
enum2 = z * sqrt(phat*(1-phat)/n + z*z/(4*n*n))
return (enum1-enum2)/denorm, (enum1+enum2)/denorm
def wilson(clicks, impressions):
if impressions == 0:
return 0
else:
return confidence(clicks, impressions)
if __name__ == '__main__':
print wilson(2,10)
print wilson(20,100)
print wilson(200,1000)
"""
--------------------
results:
(0.07048879557839793, 0.4518041980521754)
(0.14384999046998084, 0.27112660859398174)
(0.1805388068716823, 0.22099327100894336)
"""
{kind=link}
{kind=link}