问题标签 [wal]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
database - Difference between Redis AOF and Tarantool WAL log
I was reading this article about Tarantool and they seem to say that AOF and WAL log are not working the same way.
Tarantool: besides snapshots, it has a full-scale WAL (write ahead log). So it can secure data persistency after each transaction out-of-the-box. Redis: in fact, it has snapshots only. Technically, you have AOF (append-only file, where all the operations are written), but it requires manual control over it, including manual restore after reboot. Simply put, with Redis you need to manually suspend the server now and then, make snapshots and archive AOF.
Could someone explain more clearly what is the different between the 2 strategy and how each work at a high level.
I always assumed that Redis AOF was working the same way to a SQL database transaction log such as implemented in Postgresql but I might have been wrong.
database - 谁能解释为什么预写日志不使用强制?
我在网上搜了一下,STEAL和FORCE定义如下
FORCE or NO-FORCE:事务的所有更新都应该在事务提交之前强制到磁盘吗?
此外,有人告诉我
在所有日志记录都写入稳定存储之前,不会认为事务已提交
那么 WAL 与 FORCE 方法有什么不同呢?我觉得在这两种情况下,都必须在提交事务时将更改刷新到磁盘......
postgresql - 如何启用 pg_xlog 的自动清理
我正在尝试配置 PostgreSQL 9.6 数据库以限制 pg_xlog 文件夹的大小。我已经阅读了很多关于这个问题或类似问题的帖子,但我尝试过的没有任何帮助。
我为我的 Postgresql 9.6 服务实例编写了一个设置脚本。它执行 initdb,注册一个 Windows 服务,启动它,创建一个空数据库并将转储恢复到数据库中。脚本完成后,数据库结构正常,数据在那里,但 xlog 文件夹已经包含 55 个文件(880 mb)。
为了减小文件夹的大小,我尝试将 wal_keep_segments 设置为 0 或 1,将 max_wal_size 设置为 200mb,减少 checkpoint_timeout,将 archive_mode 设置为 off 并将 archive_command 设置为空字符串。当我查询 pg_settings 时,我可以看到属性已正确设置。
然后我通过 SQL 强制检查点,清空数据库,重新启动 Windows 服务并尝试 pg_archivecleanup,但没有任何效果。我的 xlog 文件夹缩小到 50 个文件(800 mb),而不是接近我在配置中设置的 200 mb 限制。
我不知道还能尝试什么。如果有人能告诉我我做错了什么,我将不胜感激。如果需要更多信息,我很乐意提供。
非常感谢
postgresql - postgresql xlog 转储的结果
我在 Ubuntu 中使用 PostgreSQL 数据库。我开始了解 WAL 日志和 pg_xlogdump。我使用 pg_xlogdump 在屏幕上打印 WAL 日志。但我不知道如何解释响应并知道进行了哪些交易。
postgresql - postgresql:从 WAL 日志中打印事务
我想知道是否有一种方法可以以更简单的方式从 WAL 日志中读取事务。我想要交易而不是二进制数据。我使用了 pg_xlogdump 但我不知道如何从看起来像这样的结果中获取事务
实际上我想要 SQL 中的事务。如果我了解每笔交易是什么以及字段的值就足够了。
hadoop - 更改 HBase WAL 位置
我打算将 HBase 与 gs:// 方案(谷歌存储桶)一起使用,但 gs:// fs 不能与 WAL 文件一起使用。
我发现它应该将 WAL 文件与 HBase 根目录分开存储,例如:https ://docs.aws.amazon.com/emr/latest/ReleaseGuide/images/hbase_s3.png
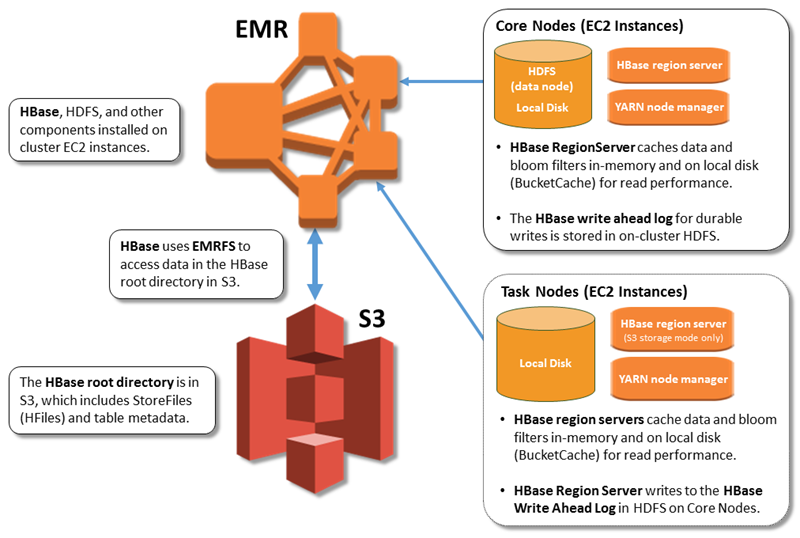{kind=link}
所以,我的问题是 - 如何分离数据文件和 WAL 文件。将数据存储在 gs:// 和 WAL 中 hdfs:// ......不幸的是我自己仍然找不到它......
提前谢谢了
postgresql - Postgres 在克隆的 VM 上使用 WAL 恢复/更新,而不是使用 basebackup
环境: 800GB Postgres 数据库(OpenSuse)
正常恢复过程:
- 你有 pg_basebackup 来恢复(比方说:每周六)
- 你有从上周六到今天的WAL文件
- 第一:使用 pg_basebackup 恢复
- 然后:使用WAL文件更新数据库以获得最新数据。(带有recovery.conf)
我的想法:
当您每天使用一些备份软件进行增量备份时,为什么每周都要进行大型 pg_basebackup 并通过 Internet 将 800GB 复制到 NAS。
- 恢复完整的数据库-vm(昨天站着)
- 添加 WAL 文件(恢复)以使此 vm-clone 保持最新。
现在我已经完成了:
- 我恢复了一个虚拟机
创建recovery.conf
restore_command = 'cp /.../%f %p'
rcpostgresql 启动
我收到以下错误:
在pg_resetxlog之后,下一个 WAL 文件被恢复。我得到同样的错误(下一个 wal 文件名)
有什么办法可以让这个工作吗?
postgresql-9.4 - Barman 恢复命令未将“所有”WAL 文件从 Barman 服务器复制到备用数据库服务器
不传输这些 WAL 文件的恢复命令有什么问题?
这是我的过程...
主数据库已关闭(模拟故障),但最近有一个备份,并且 WAL 文件已从 main-db 服务器传送。
在 Barman 服务器上,我们可以看到自上次
barman backup main-db运行以来归档了 6 个 WAL 文件。
现在我将运行recover命令,使用最新的备份+WAL文件来恢复备用数据库服务器,如下:
现在关注备用数据库服务器上的 Postgresql 数据目录(/var/lib/postgresql/9.4/main)。
我们可以看到以下 WAL 文件都没有使用恢复命令传输。
- 0000000100000001000000E3
- 0000000100000001000000E4
- 0000000100000001000000E5
- 0000000100000001000000E6
- 0000000100000001000000E7
- 0000000100000001000000E8
- 0000000100000001000000E9
但是,我可以使用 barman-cli 的barman-restore-wal命令来拉动它们。所以这告诉我他们在酒保服务器上是明确可用的。这是我用来恢复 WAL 文件的 recovery.conf 文件。
现在我们可以看到所有的 WAL 文件都是从酒保服务器中提取的。
postgresql - PostgreSQL / WAL-archiving:我可以在进行映像快照备份时将 archive_command 留空吗?
我有一个在 Azure VM 上运行的 PostgreSQL 9.5 实例。如此处所述,我必须指定一个 post- 和一个 prescript 来告诉 Azure:“是的,我已经将 VM 置于一个状态,因此整个 VM/blob 可以作为可以恢复的快照进行备份作为一个正在工作的新虚拟机”和“现在我完成了”,因此 Azure 会将备份标记为应用程序一致。
就 PostgreSQL 而言,我已经阅读了有关连续归档的文档,其中说明了为什么以及如何启用 WAL 归档以允许备份。我的问题来了:
如果我设置archive_mode = onand wal_level = archive,我可以archive_command留空吗,这是否有意义?或者 - 我应该在此处进行某种归档(例如将日志段复制到另一个位置/磁盘),并且在我的场景中恢复 VM 时确保数据库正常工作是否有必要进行归档?
我只需要告诉 PostgreSQL “等一下/保持你的数据写入(或其他任何事情),同时我会创建整个 VM 的快照”。该计划是先执行pg_start_backup(),然后拍摄快照pg_stop_backup()。
我确实意识到,这种方法(如果它甚至是有效的)本质上是一个文件系统级别的备份,并且根据 docs,必须关闭 postgres-service 才能使 fs-backup 有效。我读到的另一个地方pg_start_backup()应该足以保证有效的独立物理备份。
postgresql - wal-e 备份推送未终止(等待归档所需的 WAL 段)
试图为 postgres 设置wal-e。
遵循各种教程,我终于要对干净的 9.6 postgres 安装进行第一次备份了。
按照一些教程,最后阅读做一个初始wal-e backup-push,如下:
sudo -u postgres -i
envdir /etc/wal-e.d/env wal-e backup-push /var/lib/postgresql/9.6/main
我希望该命令能够很快终止,因为它是一个空数据库。
然而,它似乎无限期地等待。显示waiting for required WAL segments to be archived
老实说,我在这里有点超出我的深度。Afaik,上面应该做一个初始备份,但不要等待显然不断更新的 WAL 文件。(我已经archive_mode=on在我的 postgres 配置中设置archive_command = 'envdir /etc/wal-e.d/env wal-e wal-push %p'了应该执行增量推送的设置。再次 afaik。)。
我怎样才能完成这个初始备份命令?