问题标签 [video-intelligence-api]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
c# - Google cloud video-intelligence, PollUntilCompleted, and ResourceExhausted, Received message greater than max (X vs. Y)
我处于一种谷歌云视频智能混乱中。我正在使用 c# 和 google.cloud.videointelligence.v1 (2.0.0) api 来请求视频的注释(功能 TEXT_DETECTION),所以这个客户端:
client = Google.Cloud.VideoIntelligence.V1.VideoIntelligenceServiceClient.Create()
操作开始,我可以在日志中看到它,一切都很好,所以我等待结束:
client.PollUntilCompleted()
或异步版本。问题是我遇到了臭名昭著的 ResourceExhausted 异常,这还不错,结果相当大......那么我如何告诉视频智能不返回它而只接收完成的事件?我想也许在这里使用这个字段:
它完成了他被要求做的事情,将结果写入文件中,但另一端仍然试图将它发送到客户端并且 PollUntilCompleted 崩溃(重复我自己,视频智能中的操作成功结束)。那么我该怎么办,只是接受客户端将尝试返回结果对象并崩溃?
PS 我相信我可以使用存储客户端在 OutputUri 中下载结果。试过一次,180 到 40 MB,速度很慢,但可能是我的网络或电脑的问题。
问题 n.2
与此同时,我尝试使用 gcloud 来了解发生了什么,所以(希望我记得正确的 cmdline):
但是 cli 似乎只是吃掉了它可以吃掉的所有内存并且永远不会返回:在半小时内它获得了 14.75 GB 的内存和我相信的其他一些虚拟内存,所以我终止了 python 进程。如果必须,我什至不知道如何删除操作,我无法从任何地方访问它。
我是否以错误的方式使用这些东西?这些是已知的错误吗?
python - 导入谷歌云视频智能时出错:ImportError: cannot import name 'init_grpc_aio' from 'grpc._cython.cygrpc'
我正在尝试运行:
我收到以下错误:
从 grpc._cython.cygrpc 导入(init_grpc_aio,shutdown_grpc_aio,EOF,
ImportError: 无法从 'grpc._cython.cygrpc' 导入名称 'init_grpc_aio' (C:\ProgramData\Anaconda3\lib\site-packages\grpc_cython\cygrpc.cp37-win_amd64.pyd)
当我尝试导入它时也会发生这种情况
我尝试再次安装 grpc [grpcio],但并没有解决问题。我还没有找到任何有用的解决方案。
我能做些什么来解决这个问题?
python - 谷歌云视频智能:ModuleNotFoundError:没有名为“google.api_core.operations_v1”的模块
我想使用 Google Cloud Videointelligence,但我不断收到错误消息。现在我明白了
我不知道如何安装所述模块,我找不到任何关于此的信息。
这是我到目前为止安装的:
google-cloud-platform - 如何使用谷歌云视频智能名人识别?
到目前为止,我一直在愉快且成功地使用 Google Cloud Video Intelligence Api。但是,如果我没记错的话,现在我注意到 Celebrity API 只对经过批准的选定媒体公司开放。Amazon Rekognition 向公众提供这种支持。这是非常令人难以置信的。这种服务怎么可能是像谷歌这样的公共云服务上的私有服务?
有谁知道如何使用 Google Cloud 中的 Celebrity Recognition API?
google-cloud-platform - GCP > Video Intelligence:准备 CSV 错误:在根级 csv 中有严重错误,预期 2 列,但仅找到 1 列
我正在尝试按照 GCP 链接下方的文档来准备我的视频训练数据。在文档中,它说如果你想使用 GCP 来标记视频,你可以使用 UNASSIGNED 功能。我有我的视频上传到一个桶。我有一个带有以下行的 traffic_video_labels.csv:
现在,在我的视频智能导入部分中,我想使用一个名为 check.csv 的 CSV,它具有以下行,因为它引用回视频位置。使用 UNNASIGNED 值应该让我在 GCP 中使用标签功能。
但是,当我尝试将 check.csv 作为文件进行检查时,出现错误:
有人可以帮忙吗?谢谢!
https://cloud.google.com/video-intelligence/automl/object-tracking/docs/prepare
python - Python 中的 Google Video Intelligence API:如何下载响应 JSON?
我正在尝试使用下面的 Python 文档来使用 OBJECT_TRACKING METHOD。该脚本有效,但我想知道如何下载 JSON。我刚开始使用 Python。
注意:下面的 Javier 现在已经回答了这个问题。我已经修改了下面的脚本,以向寻求相同解决方案的其他人显示答案。有一个 output_uri 变量,在操作函数中,添加了 output_uri 参数以在您之前声明的 GCS 位置创建一个 response.json。

google-cloud-platform - Python 中的 Google Cloud Video Intelligence API - 无法对文件夹中的多个视频运行对象跟踪
我正在尝试在包含多个视频的文件夹上运行对象跟踪。我的存储桶中有 5 个视频,按照此处的文档,它建议使用通配符 (*) 运算符。但是,当我运行整个脚本时,只有 1 个视频得到注释,而不是包含 5 个视频的整个文件夹。此外,response2.json 不会在我的 GCS 存储桶中创建为 output_uri。
为了识别多个视频,视频 URI 可以在 object-id 中包含通配符。支持的通配符:'*' 匹配 0 个或多个字符;“?” 匹配 1 个字符。 https://googleapis.dev/python/videointelligence/latest/gapic/v1/types.html
这是我在 input_uri 代码中所做的:
如果您检查屏幕截图,它应该是存储桶 ID 名称并在同一文件夹中显示多个视频。

任何人都可以帮助解决这个问题。谢谢。
完整脚本:
video-intelligence-api - 人脸检测模型返回空字典(Google Cloud Video Intelligence)
我在使用 Google Video Intelligence API 的人脸检测模型时遇到问题。
我正在使用Python 3.6.5, 和google-cloud-videointelligence==1.15.0.
有时我会收到来自人脸检测模型的错误响应。我正在解析来自 API 的响应,方法是使用google.protobuf.json_format.MessageToDict(). 我预计会发生以下两种行为之一:
A. 如果视频中出现人脸,我希望结果在 key 下'FaceDetectionAnnotations',并采用字典的形式;外部字典的键是“段号”(整数),内部字典看起来像这样:
B. 如果视频中没有人脸,我希望结果中的任何地方都没有这样'FaceDetectionAnnotations'的关键。
但是,偶尔我会看到第三种响应,其中'FaceDetectionAnnotations'键存在于结果中(表明人脸检测模型确实检测到了人脸),但是每个内部字典都是空的。每个段仍然有一个内部字典,但它们不包含任何常用信息,例如段的开始和结束时间,或任何坐标或置信度值。
我只在有面孔的视频中看到这个问题。
我可以确认此问题存在于 Google VI 的原始响应中(在使用MessageToDict()函数解析之前,我不确定是什么原因造成的。下面是展示此问题的示例视频的链接。
https://drive.google.com/file/d/1gsbe20iWp6lD9dH0PNvxvvQFUeB5F_cz/view?usp=sharing
如果有人以前见过这样的事情,或者知道如何解决这个问题,我将不胜感激。
google-cloud-platform - 如何使用 Google Video Intelligence API 跟踪眼球运动?
我有一个 3 人讲话的视频,我想在视频中注释人们眼睛的位置。我知道 Google Video Intelligence API 具有对象跟踪功能,但是可以使用 API 处理这样的眼球跟踪过程吗?
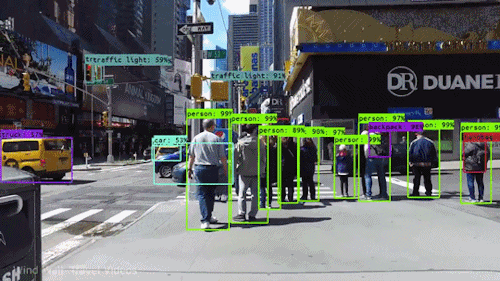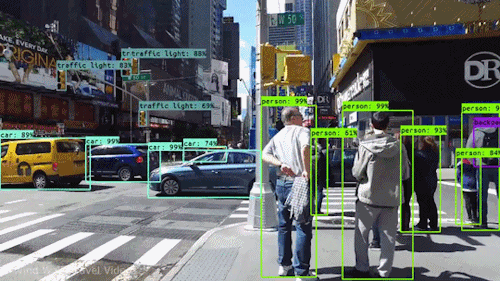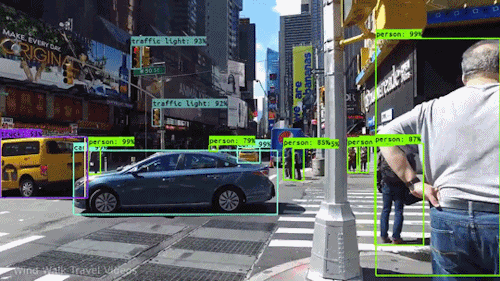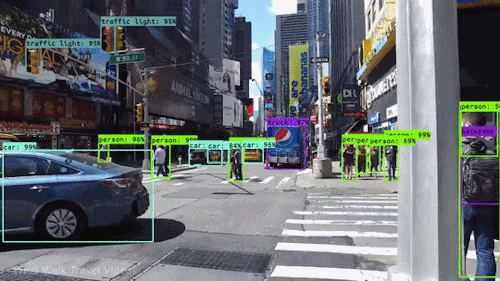
video - Google Cloud Video Intelligence API:VideoAnnotationResults 叠加在视频上
我已经使用 Video Intelligence API 对我的视频进行对象跟踪 - 并且收到了一个 JSON 输出,其中包含在我的视频中检测到的所有帧和对象。
有没有办法可以使用原始视频从我的 JSON 生成视频输出 - 以显示为视频跟踪的所有对象的示例?
如下所示:
https://cdn-images-1.medium.com/max/500/1*q1uVc-MU-tC-WwFp2yXJow.gif
{kind=link}