问题标签 [utf-32]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
c++ - 国际 UTF-32 字符串输出到 Linux 中的控制台
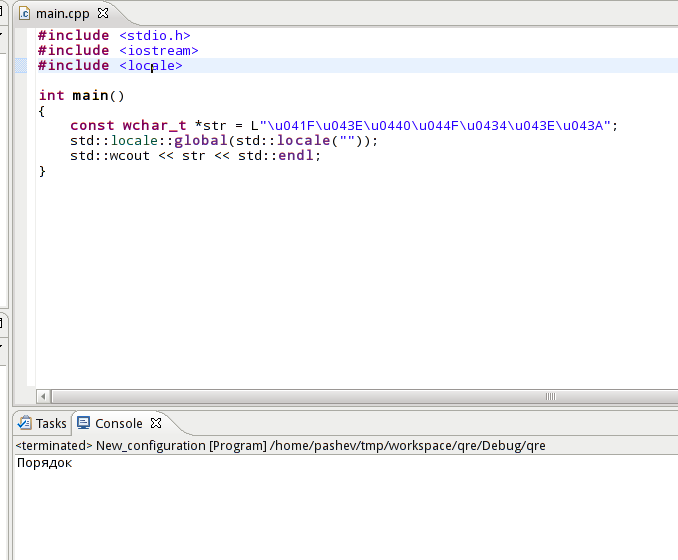
这是一段代码,它以 UTF-32 wchar_t 字符串输出俄语短语:
- 正确的:在 Ubuntu 11.10 中从 UTF-8 gnome 终端运行时的Порядок
- РџРѕСЂСЏРґРѕРє 在 Eclipse 中的测试运行如上
- 45=B8D8:0B>@ 在 Eclipse 中在一个真实的程序中(我什至不知道谁在哪里做什么,但我想有人确实弄乱了语言环境)
- ??????如果我不调用语言环境
- str 在 Eclipse Watch 窗口中显示为 Details:0x400960 L"\320\237\320\276\321\200\321\217\320\264\320\276\320\272"
- 在 Eclipse 内存窗口中显示为仅 ASCII字节字符(并且无法指定这是 UTF-32 字符串)
我相信这是 Eclipse 控制台或程序中的错误配置,因为例如,其他人只是在 Eclipse 中运行我的代码,他们确实看到了正确的输出。
{kind=link}
有人能解释一下这种混乱吗?设置所有部分(操作系统、gcc、终端、Eclipse、源...)以输出存储在 UTF-32 wchar_t 字符串中的国际符号的正确方法是什么?
附带说明一下,当我们拥有 UTF-32 时,我为什么还要关心所有这些,这足以知道里面有什么......
vba - 如何将 U+20000 之类的 utf-32 代码转换为 VBA 中的字符?
如果s包含20000并且j是Len(s)以下
不起作用。它返回 2 个字符,而 U+20000 是一个字符。
c# - UTF32 和 C# 问题
所以我在字符编码方面遇到了一些麻烦。当我将以下两个字符放入 UTF32 编码的文本文件时:
然后在它们上运行此代码:
我得到:
(相同的字符两次,即输入文件!=输出)
一些可能有帮助的事情:第一个字符的十六进制:
15 9E 02 00
对于第二个:
15 9E 00 00
我使用 gedit 创建文本文件,使用 mono 用于 C#,我使用的是 Ubuntu。
如果我为输入或输出文件指定编码也没关系,如果它是 UTF32 编码,它只是不喜欢它。如果输入文件采用 UTF-8 编码,它就可以工作。
输入文件如下:
FF FE 00 00 15 9E 02 00 0A 00 00 00 15 9E 00 00 0A 00 00 00
这是一个错误,还是只是我?
谢谢!
unicode - 为什么没有 UTF-24?
UTF-32 中的最大 Unicode 代码点为 0x10FFFF。UTF-32 有 21 个信息位和 11 个多余的空白位。那么为什么没有 UTF-24 编码(即去掉高字节的 UTF-32)将每个代码点存储在 3 个字节而不是 4 个字节中呢?
c++ - 将 UTF-8 转换为 UTF-32,预先计算每个字符中的“字符”数
我有一个将 UTF-8 字符串转换为 UTF-32 字符串的有效算法,但是,我必须提前为我的 UTF-32 字符串分配所有空间。有什么方法可以知道 UTF-8 字符串将占用多少个 UTF-32 字符。
例如,UTF-8 字符串“¥0”是 3 个字符,转换为 UTF-32 后是 2 个无符号整数。有什么方法可以知道在进行转换之前我需要多少 UTF-32 'chars'?还是我将不得不重新编写算法?
utf-8 - utf8_general_ci 或 utf8mb4 还是...?
utf16 还是 utf32?我正在尝试以多种语言存储内容。一些语言使用双宽字体(例如,日文字体通常是英文字体的两倍)。我不确定我应该使用哪种数据库。有关这四个字符集之间差异的任何信息...
java - Java 7 的内部字符编码
据我所知,当 JRE 执行 Java 应用程序时,该字符串在内部将被视为 USC2 字节数组。在wikipedia中,可以找到以下内容。
Java 最初使用 UCS-2,并在 J2SE 5.0 中添加了 UTF-16 补充字符支持。
随着 Java (Java 7) 的新发布版本,它的内部字符编码是什么?
Java有没有可能在内部开始使用UCS-4?
c# - 如何创建一个包含代理对的字符串?
我在 Jon Skeet 的博客上看到了这篇文章,他谈到了字符串反转。我想尝试他向自己展示的示例,但它似乎有效......这让我相信我不知道如何创建一个包含代理对的字符串,这实际上会导致字符串反转失败。实际上如何创建一个带有代理对的字符串,以便我自己可以看到失败?
javascript - 是否可以将包含“高”unicode 字符的字符串转换为由从 utf-32(“真实”)代码派生的 dec 值组成的数组?
请查看在(理论上可能的)字符串上运行的此脚本:
代替“55349,56421,56204,56800,65,56288,56689”,是否有可能得到“119909,995808,65,1081713”?我已经阅读了 more-utf-32-aware-javascript-string和Q:从 UTF-16 转换为字符代码的算法是什么?+问:没有更简单的方法吗?来自unicode.org/faq/utf_bom,但我不确定如何使用此信息。
utf-8 - 在 C++11 中读取/写入/打印 UTF-8
我一直在探索 C++11 的新 Unicode 功能,虽然其他 C++11 编码问题非常有帮助,但我对cppreference中的以下代码片段有疑问 。代码写入然后立即读取以 UTF-8 编码保存的文本文件。
我的问题很简单,为什么循环wchar_t中需要a ?可以使用简单的方式声明字符串文字for,并且 UTF-8 编码的位布局应该告诉系统字符的宽度。似乎有一些从 UTF-8 到 UTF-32 的自动转换(因此是),但如果是这种情况,为什么需要进行转换?u8char *wchar_t