问题标签 [spark-ui]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
apache-spark - 通过 conda 安装 pyspark 时没有 start-history-server.sh
我已经在 Ubuntu 的 miniconda 环境中通过conda install pyspark. 到目前为止一切正常:我可以运行作业,spark-submit并且可以检查正在运行的作业localhost:4040。但我找不到start-history-server.sh,我需要查看已完成的工作。
应该是在, spark的安装目录在{spark}/sbin哪里。{spark}我不确定通过 conda 安装 spark 时应该在哪里,但我已经搜索了整个 miniconda 目录,但似乎无法找到start-history-server.sh. 对于它的价值,这适用于 python 3.7 和 2.7 环境。
我的问题是:是否start-history-server.sh包含在 pyspark 的 conda 安装中?如果是,在哪里?如果不是,那么在事后评估火花工作的推荐替代方法是什么?
apache-spark - 从 Spark UI SQL 选项卡获取查询 DAG 数据的任何 API
spark UI 有一个 SQL 选项卡。它可以将查询详细信息显示为 DAG
应用程序完成后,DAG 还会使用统计信息注释其节点。例如,
Spark 有任何 API 来获取指标吗?Spark 具有可通过 RESTful API 访问的https://spark.apache.org/docs/latest/monitoring.html#executor-task-metrics 。Spark UI 上的 stage 选项卡还显示了每个任务的“Summary Metrics”。然而
1) 我不确定如何将任务 ID 与查询 DAG 上的 RDD 或节点相关联
2) Peak Execution Memory 指标始终为 0,而我们可以看到 SQL 选项卡可以显示
另一个问题是如何读取 DAG 节点上的指标。例如,
节点的最小值、中值、最大值是多少?它的值远小于总的24.1G...
apache-spark - 如何知道每个 Spark 任务/执行器运行什么样的工作
当我的应用程序在 Spark 集群上运行时,我知道以下内容
1) 执行计划
2)以节点为RDD或操作的DAG
3)所有作业/阶段/执行者/任务
但是,我不知道如何知道给定任务 ID 任务的工作类型(RDD 或操作)。
从一个任务中,我可以知道它的执行者 ID 和它运行的机器。在机器上,如果我们 grep Java 和 ID,我们可以得到
但它并没有告诉我它做了什么...... Spark 会公开信息吗?
apache-spark - Spark UI SQL 视图几乎不显示任何内容
我正在尝试使用 Spark SQL 优化一个程序,该程序基本上是一个巨大的 SQL 查询(连接像 10 个表,有很多案例等)。我更习惯于更多面向 DF-API 的程序,并且这些程序确实更好地显示了不同的阶段。
它的结构很好,我或多或少地理解它。但是我有一个问题,我总是使用 Spark UI SQL 视图来获得有关优化重点的提示。
但是在这种程序中,Spark UI SQL 什么也没显示,这是有原因的吗?(或一种强制它显示的方法)。
我希望看到每个连接/扫描后的输出行数等等......但我只看到一个完整的“WholeStageCodeGen”,用于“解析的逻辑计划”,就像 800 行
我无法显示代码,它有以下“点”:
有没有办法改善那里的追踪?(也许禁用 WholeStageCodegen?,但这可能会损害性能......)


谢谢!
java - 如何修复 SparkUI 执行器,java.io.FileNotFoundException
我已经使用 Apache Spark 部署了 Spring Boot 服务器,并且一切运行稳定。但是http://XXXX:4040/executors/
SparkUI executors端点抛出java.io.FileNotFoundException并且找不到/opt/x/x!/BOOT-INF/lib/spark-core_2.11-2.2.0.jar. 我检查了内罐。这个问题只发生在 Linux 上,在 Windows 上它可以正常工作。
{kind=link}
{kind=link}
{kind=link}
apache-spark - 在 Google Colab 上工作时如何打开 Spark UI?
如何通过 Spark WEB UI 监控作业的进度?在本地运行 Spark,我可以通过端口 4040 访问 Spark UI,使用 http://localhost:4040。
scala - 流式传输选项卡未显示结构化流式传输
我正在使用结构化流来读取 csvs 和写入 kafka。Spark UI 中未显示流式处理选项卡(未使用流式处理上下文)。
如何在 UI 中获取流媒体指标?
apache-spark - SparkUI 在独立模式下运行时不显示选项卡(作业、阶段、存储、环境……)
我正在通过以下命令运行 spark master:
./sbin/start-master.sh
之后我去了http://localhost:8080,我看到了以下页面。
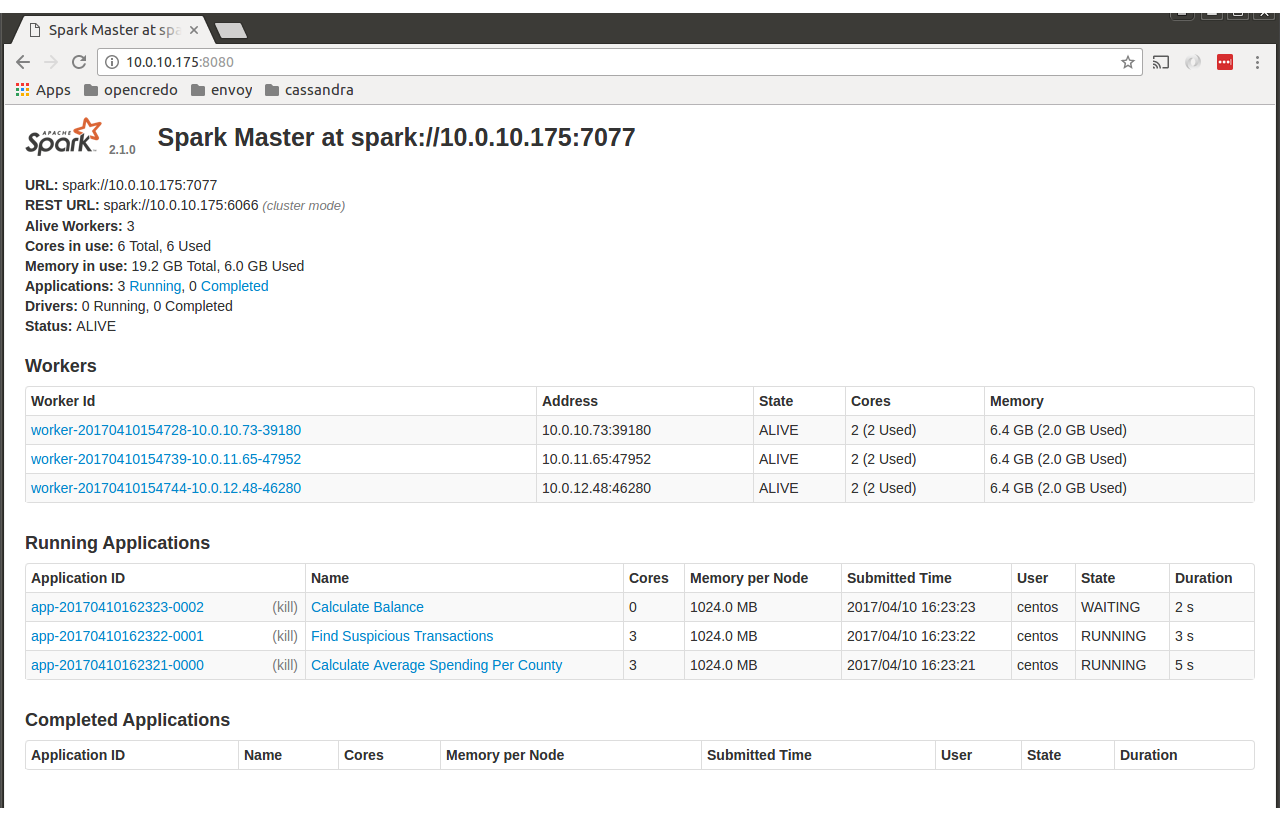
我期待看到带有 Jobs、Environments、... 的选项卡,如下所示
有人可以帮助我了解问题出在哪里吗?
我需要额外的配置吗?
谢谢
朱塞佩
apache-spark - 优化 Spark 作业 - Spark 2.1
我的 spark 工作目前在 59 分钟内运行。我想优化它,以便我花费更少的时间。我注意到作业的最后一步需要很长时间(55 分钟)(请参阅下面 Spark UI 中的 spark 作业的屏幕截图)。
我需要将一个大数据集与一个较小的数据集连接起来,在这个连接的数据集上应用转换(创建一个新列)。
最后,我应该有一个基于列重新分区的数据集PSP(参见下面的代码片段)。我还在最后执行排序(根据 3 列对每个分区进行排序)。
所有详细信息(基础架构、配置、代码)都可以在下面找到。
我的代码片段:
已编辑 - 重新分区逻辑
smallDF是我广播的一个小数据集(535MB)。
TransactionTypeuh是一个类,我根据 3 列 ( MMED, DEBCRED, ) 的值向我的数据框中添加一列新的字符串元素,NMTGP使用正则表达式检查这些列的值。
由于未找到随机播放块,我以前遇到过很多问题(工作失败)。我发现我正在溢出到磁盘并且有很多 GC 内存问题,所以我将“spark.sql.shuffle.partitions”增加到 4158。
为什么是 4158?
Partition_count = (stage input data) / (target size of your partition)
所以Shuffle partition_count = (shuffle stage input data) / 200 MB = 860000/200=4300
我有16*24 - 6 =378 cores availaible。因此,如果我想一次性运行所有任务,我应该将 4300 除以 378,大约是 11。然后11*378=4158
火花版本:2.1
集群配置:
- 24 个计算节点(工作者)
- 每个 16 个 vcore
- 每个节点 90 GB RAM
- 6 个内核已被其他进程/作业使用
当前 Spark 配置:
-主人:纱线
-执行器内存:26G
-执行器核心:5
-驱动内存:70G
-num-executors:70
-spark.kryoserializer.buffer.max=512
-spark.driver.cores=5
-spark.driver.maxResultSize=500m
-spark.memory.storageFraction=0.4
-spark.memory.fraction=0.9
-spark.hadoop.fs.permissions.umask-mode=007
作业如何执行:
我们使用 IntelliJ 构建一个工件(jar),然后将其发送到服务器。然后执行一个 bash 脚本。这个脚本:
导出一些环境变量(SPARK_HOME、HADOOP_CONF_DIR、PATH 和 SPARK_LOCAL_DIRS)
使用上面 spark 配置中定义的所有参数启动 spark-submit 命令
检索应用程序的纱线日志
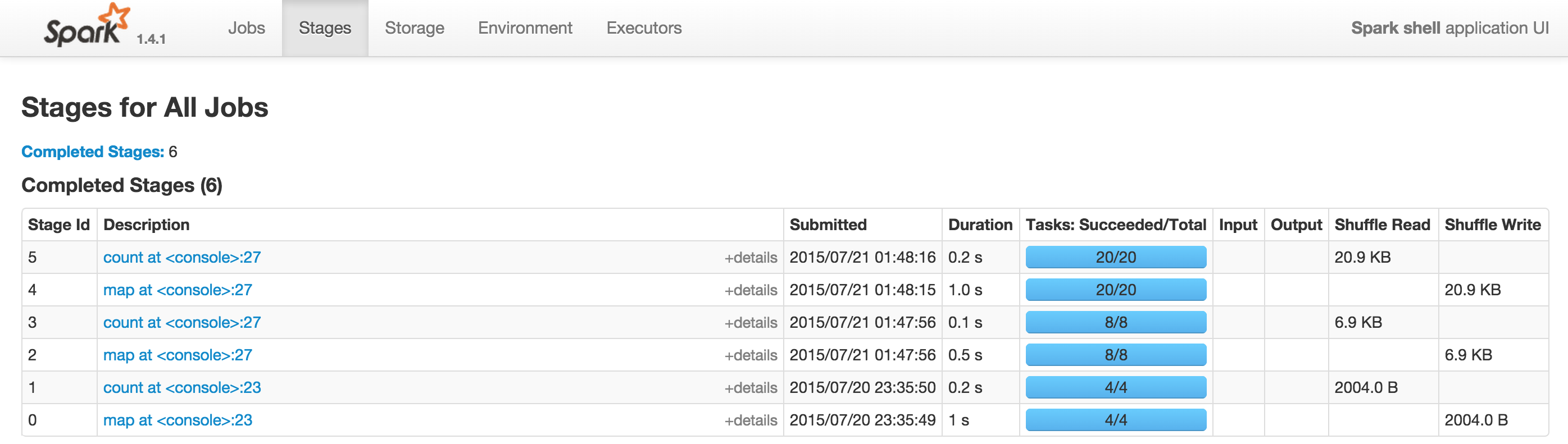
Spark 用户界面截图
有向无环图




apache-spark - Spark Job UI - 步骤名称下的时间/持续时间值
我有一个简单的问题 - Spark UI 中 WholeStageCodegen 矩形顶部的时间是多少?是处理时间吗?
