问题标签 [segments]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
r - 使用segments函数画线
我试图在我的观察值和拟合值之间绘制线。但不知何故,我一直在出错。我segments用来做这个。下面是我的脚本:
谁能告诉我我在这里做错了什么?当我运行x0它显示NULL。x1和y1(NULL)相同。这是问题吗?我该如何纠正
谢谢
r - 在R中绘制弧度/度数
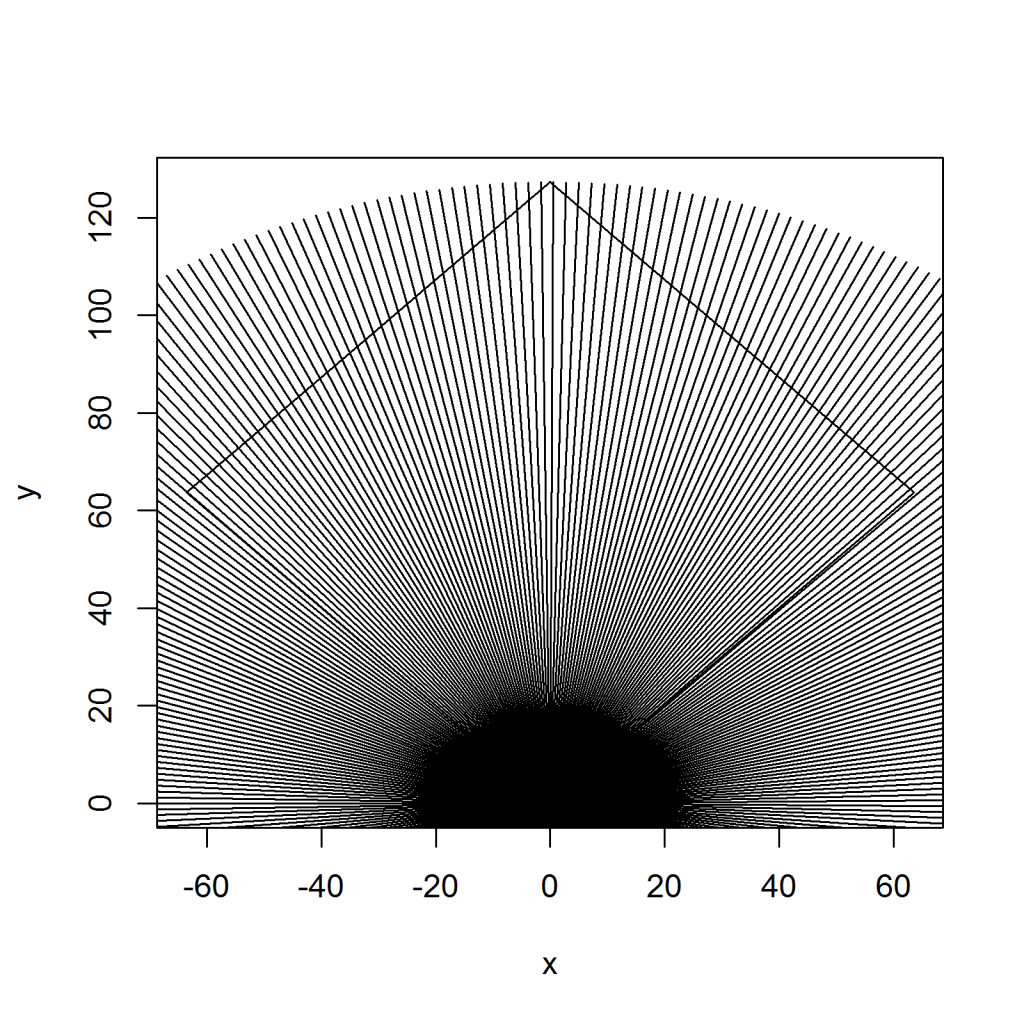
我很难产生一个圆的 X,Y 坐标,然后画线段。基本上我想做的是以完美的间距从圆心到圆外绘制 360 条线。这就是我目前的做法,但它不起作用。如果有不同的方法可以做到这一点,那也很好!我也希望 0 度从圆圈的左侧开始。
更新:
我在画线的地方遇到了一些问题。基本上,当我们绕着圆圈走时,误差会变大,所以当 pi/2 弧度发生并且它是直线向上时,该值稍微偏右 x=0。这可能无法获得,但我想我会问是否有办法解决这个问题!45 90 和 135 应该都在行上匹配。
session - 对行为不符合预期的用户进行细分
我想看看在过去任何(跟踪的)时间执行特定操作序列对用户保留和参与的影响。
动作序列是执行可选的新用户流的动作序列。
这通过向 Google Analytics 发送适当的事件来通知它。这很好用。事件按预期显示在报告中。
我的问题是当我使用这些事件创建细分时结果会发生什么。我已经尝试了两种不同的方法在高级细分中基于此创建细分,通过条件(通过结束事件定义细分,过滤用户而不是会话)和通过序列(定义开始和结束事件,再次过滤用户不会话)。
当我使用这些细分中的任何一个查看各种保留/忠诚度报告时,我得到的结果非常清楚地是在会话内进行此细分的结果,而不是跨使用会话。因此,对于 NUF 完成者,我在第 1 次会议上看到了我所有的忠诚度/新近度,其中人们最有可能进行 NUF,如果他们曾经这样做的话。这不是我想要的。(请注意,它在其他情况下可能非常有用,在另一个事件中!但不适用于新用户流。)
为了得到我想要的东西,我有哪些选择?我看到了两种可能的前进方式:
- 使用自定义维度,在新用户流程完成时在代码中分配自定义维度值。但是我不知道这是否会解决跨会话持久性问题。
- 注入用户 ID,我们目前不这样做,并且(不知何故!)使用注入用户 ID 时可用的报告来执行此操作。
这些路径中的任何一条都合理吗?有没有更好的前进方式?甚至尝试在 Google Analytics 中执行此操作是愚蠢的吗?我对 App Tracking 解决方案(例如 Flurry、Mixpanel、DeltaDNA)比使用 Google Analytics 更熟悉,这些解决方案是理所当然的,事实上这在 Google Analytics 中至少有点尴尬惊喜。
谢谢,
希瑟
c - 在运行时替换微控制器上函数指针后面的函数
我想知道是否有办法在运行时将 C 函数及其数据加载到正在运行的微控制器系统的文本段中。在函数被放置在文本段中并且数据被存储在数据段中之后,指向新加载函数的函数指针在主应用程序中被调用。除了在启动之前加载整个二进制文件之外,该功能将类似于引导加载程序。我知道您可以使用链接器的分散加载函数将函数指针放置在固定地址或更改节中的对齐方式。有谁知道这是否可能,如果不能,为什么?
非常感谢
matlab - CUMSUM 沿分段中的行 - MATLAB
我在数组中有数据A = 100 X 612。我需要在12列段中累积添加51时间并将结果存储在一个新数组B = 100 X 612中。最终数组B沿列累计求和,12然后再次cumsum沿列继续使用,13:24并像这样继续直到结束列601:612。这是按行顺序重复100的次数。
我已经多次尝试使用循环但无法得到答案 - 必须有一种更简单的方法来获得解决方案..太依赖于循环!
pointers - 64 位 Intel(和非 Intel)处理器中的分段
我试图了解 64 位架构中进程段的实现。我遇到了这两个讨论:
但是,我仍然不清楚。在 Intel 80286/80386 时代,引入分段是为了克服使用 16 位地址的 64K 内存的限制。此后,出于兼容性原因,32 位 Intel 机器仍继续使用它。
现在转向 64 位:手册说这里很少实现分段(参考:http ://en.wikipedia.org/wiki/X86_memory_segmentation )。虚拟内存和分页可以提供对整个地址空间的访问以及保护。
所以我的问题是:64 位编译器如何编译 64 位程序?他们是否仍然像以前一样使用“段”的概念(因为我仍然看到提到数据段、堆栈段等),但使用更高的#位段指针?或者,“段”这个词是否指的是完全不同的 64 位架构?
任何帮助表示赞赏。
caching - ElasticSearch 中的 Translog:实时 CRUD 和廉价 fsyncs?
在浏览 ElasticSearch 的权威指南时,我偶然发现了一些谜团。首先确定搜索是接近实时的,因为更改需要作为新段刷新到文件系统缓存中(默认情况下是每秒一次),只有在此之后它才能被搜索机制看到,并且不使用 fsync,因为这太昂贵了。
然后出现translog。出于某种原因,它可以用来进行实时 CRUD。因此引擎首先遍历文件系统缓存中它所知道的所有段,并将它发现的更改添加到事务日志中。如果 translog 可以实时保持最新,那么保持片段实时保持最新的内在问题是什么?是为了防止缓存中的段过多吗?
另外,为什么translog默认每5秒fsync一次没有问题,而segment却不行?
c# - downloadfileasync,下载部分
我是否只能使用以下命令下载文件的一半:
我只需要文件的一部分。
kernel - Windows 驱动程序的重定位机制
我试图了解一点内核驱动程序的加载过程。据我所知,内核驱动程序加载在高端内存区域(在win32上> 0x80000000)实际上它们的基地址在编译时是未知的。我查看了一些系统驱动程序头的数据,似乎它们没有重定位目录。
那么内核如何正确加载它们呢?还是驱动程序代码与位置无关?我不这么认为,因为存在各种数据段。
谢谢 !
aem - AEM 6.1 中的个性化
我已经按照下面提到Youtube的链接创建Personalization. 在 geometrixx 站点中创建演示页面并放置内容后,我看不到在内容的右键单击上定位内容的选项。请让我知道我该怎么做?
https://www.youtube.com/watch?v=HWXMAQcRmEU
仅供参考 - 我是 AEM 6.1
另外,我遵循了下面提到的 Adobe 文档。在预告片创建部分,他们使用“预告片页面模板”创建了一个新页面,但我在本地看不到该模板。我可以看到“体验模板”。让我知道我怎样才能拥有这个模板。
https://docs.adobe.com/docs/en/aem/6-1/author/personalization/campaigns/teasers-and-strategies.html