问题标签 [lexer]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
compiler-construction - ANTLR 词法分析器不匹配标记
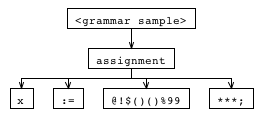
我有一个简单的 ANTLR 语法,我已将其简化为基本要素,以证明我遇到的这个问题。我正在使用 ANTLRworks 1.3.1。
显然,这个语句被文法所接受:
但这也是:
ANTLRworks 解释器的输出:

(来源:cs.sierracollege.edu 的 barry)
{kind=link}
我究竟做错了什么?甚至 ANTLR 附带的其他示例语法(例如 CMinus 语法)也表现出这种行为。
php - 在 PHP 中标记 CSS 的性能
这是一个从未编写过解析器/词法分析器的人提出的菜鸟问题。
我正在为 PHP 中的 CSS 编写标记器/解析器(请不要重复“OMG,为什么在 PHP 中?”)。W3C在此处 (CSS2.1)和此处 (CSS3, draft)巧妙地编写了语法。
这是 21 个可能的标记的列表,所有(除了两个)都不能表示为静态字符串。
我目前的方法是一遍又一遍地循环遍历包含 21 种模式的数组,并if (preg_match())通过匹配减少源字符串匹配。原则上,这真的很好。然而,对于一个 1000 行的 CSS 字符串,这需要 2 到 8 秒,这对我的项目来说太长了。
现在我正在思考其他解析器如何在几分之一秒内标记和解析 CSS。好吧,C总是比 PHP 快,但是,有什么明显的D'Oh!是我掉进去的吗?
我做了一些优化,比如检查 '@'、'#' 或 '"' 作为剩余字符串的第一个字符,然后只应用相关的正则表达式,但这并没有带来任何巨大的性能提升。
到目前为止我的代码(片段):
gcc - 无法编译 lex 的输出
当我尝试编译这个微不足道的 lex 程序的输出时:
使用:
我得到:
lex --version 告诉我我实际上使用的是“flex 2.5.35”,尽管 ls -fla `which lex` 不是符号链接。为什么输出无法编译的任何想法?
c# - 手动编码解析器
对于所有编译器专家,我想编写一个递归下降解析器,我只想用代码来完成。没有从其他语法生成词法分析器和解析器,也不要告诉我阅读龙书,我最终会解决这个问题。
我想深入了解有关为一种合理的简单语言(例如 CSS)实现词法分析器和解析器的细节。我想正确地做到这一点。
这可能最终会成为一系列问题,但现在我从词法分析器开始。可以在此处找到 CSS 的标记化规则。
我发现我自己编写的代码是这样的(希望你可以从这段代码中推断出其余的):
这个叫什么?我离合理理解的东西还有多远?我正在尝试平衡一些在效率方面公平且易于使用的东西,使用堆栈来实现某种状态机效果很好,但我不确定如何继续这样。
我拥有的是一个输入流,我一次可以从中读取 1 个字符。我现在不做任何头,我只是阅读角色然后根据当前状态尝试对此做些什么。
我真的很想进入编写可重用代码片段的思维模式。这个Transition方法目前的意思是这样做,它会弹出堆栈的当前状态,然后以相反的顺序推送参数。这样,当我编写Transition(ParserState.SubIdent, ParserState.Init)它时,它将“调用”一个子例程SubIdent,该例程完成后将返回到该Init状态。
解析器将以几乎相同的方式实现,目前,将所有内容都放在一个大方法中,这样我可以在找到一个标记时轻松返回一个标记,但它也迫使我将所有内容保存在一个大方法中。有没有一种很好的方法可以将这些标记化规则拆分为单独的方法?
lexer - 词法分析器/解析器歧义
词法分析器如何解决这种歧义?
为什么它不只是说,哦,是的,那是多行注释的开头,然后是另一个多行注释。
贪婪的词法分析器不会只返回以下标记吗?
- /*
- /*
- /
我正在为 CSS 编写一个 shift-reduce 解析器,但是这个简单的注释事情妨碍了我。如果您不想了解更多背景信息,可以阅读此问题。
更新
很抱歉一开始就忽略了这个。我打算以这种形式向 CSS 语言添加扩展,/* @ func ( args, ... ) */但我不想混淆理解 CSS 但不理解我的扩展注释的编辑器。这就是为什么词法分析器不能忽略注释的原因。
scala - scala StdLexical中的词法换行符?
我正在尝试 lex(然后解析)类似 C 的语言。在 C 中,有一些预处理器指令,其中换行符很重要,然后是实际代码,它们只是空格。
这样做的一种方法是像早期的 C 编译器一样执行两遍过程 - 为 # 指令设置一个单独的预处理器,然后对它的输出进行 lex。
但是,我想知道是否可以在单个词法分析器中完成。我对编写 scala 解析器组合器代码感到非常满意,但我不太确定如何StdLexical处理空格。
有人可以编写一些简单的示例代码,说可以#include使用一行(使用换行符)和一些琐碎的代码(忽略换行符)吗?或者这是不可能的,最好采用 2-pass 方法?
c# - 解析 C# 代码以评估表达式(基本上,实现 Intellisense)
我试图在输入 C# 代码时对其进行评估,把它想象成我正在尝试编写一个 IDE。
所以一个人敲代码,我想看看他刚才写了什么代码:
我现在想注册 x 是一种字符串。现在每次用户再次键入 x,我想向他展示他可以用 x 做的所有事情,基本上就像 Visual Studio Intellisense。
我需要一些词法分析器或解析器吗?这会让事情变得更容易吗?我听说 VS 2010 有一些微软已经发布的特性。有任何想法吗?
grammar - Flex,多行规则
嗨,我的词法分析器定义中有一个 flex 规则:
有没有办法将这个规则拆分为更多行以使其更清晰?我尝试使用 \ 就像宏一样,但它似乎不被 flex 接受:(
PS:我不想将规则拆分为更多的子规则,而只是将其正则表达式拆分为更多行以保持代码更清晰。
javascript - 在不使用 () 包装的情况下调用本机 Javascript 类型的方法
在 Javascript 中,我们可以直接在字符串文字上调用方法,而无需将其括在圆括号中。但不适用于其他类型,例如数字或函数。这是一个语法错误,但是否有理由说明为什么 Javascript 词法分析器需要将这些其他类型括在圆括号中?
例如,如果我们使用 alert 方法扩展 Number、String 和 Function 并尝试在字面量上调用此方法,则它对于 Number 和 Function 是 SyntaxError,而它适用于 String。
我们可以直接在字符串对象上调用 alert:
但这是数字和函数的语法错误。
要使用这些类型,我们必须将其括在括号中:
更新:
@Crescent 的链接和@Dav 和@Timothy 的回答解释了为什么7.alert()失败,因为它正在寻找一个数字常量,并且要通过它,插入额外的空格或额外的点。
为什么在对函数调用方法之前需要将函数括在括号中,是否存在类似的语法原因?
我不太熟悉解释器和词法分析器,不知道这是否是一个可以通过某种前瞻来解决的问题,因为 Ruby 是一种动态语言并且可以解决这个问题。例如:-
更新 2:
@CMS 的答案在理解为什么上面的函数不起作用。以下陈述有效: