问题标签 [cql3]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
cassandra - Cassandra:生成一个唯一的 ID?
我正在研究分布式数据库。我正在尝试生成一个唯一 ID,该 ID 将用作cassandra中的列族主键。
我阅读了一些关于使用 Java 执行此操作的文章,UUID但似乎存在冲突的可能性(即使它非常低)。
我想知道是否有办法根据时间生成唯一 ID?
cassandra - 在使用 Datastax API(使用新的二进制协议)时在 Cassandra 中创建列族或表
我已经开始使用 Cassandra 数据库。我打算使用Datastax API来更新/读取 cassandra 数据库。我对这个 Datastax API(它使用新的二进制协议)完全陌生,我也找不到很多文档,其中有一些适当的例子。
当我使用 Netflix 客户端(Astyanax 客户端)使用 Cassandra CLI 时,我创建了这样的列族 -
现在我尝试使用 Datastax API 做同样的事情。因此,要开始使用 Datastax API,我是否需要以上述不同的方式创建列族?或者,每当我尝试使用 Datastax API 将数据插入 Cassandra 数据库时,上面的列系列都可以正常工作。
如果上述列族不起作用,那么-
首先,我创建了如下所示的 KEYSPACE -
CREATE KEYSPACE USERS WITH strategy_class = 'SimpleStrategy' AND strategy_options:replication_factor = '1';
现在我很困惑如何创建表?我不确定哪种方法是正确的?
我应该这样创作吗?
CREATE TABLE profile (
id varchar,
account varchar,
advertising varchar,
behavior varchar,
info varchar,
PRIMARY KEY (id)
);
还是我应该这样创作?
CREATE COLUMN FAMILY profile (
id varchar,
account varchar,
advertising varchar,
behavior varchar,
info varchar,
PRIMARY KEY (id)
);
以及如何添加-
在使用 Datastax API 时在上面的表或列族中?
任何帮助将不胜感激。
java - 使用 Datastax API(使用新的二进制协议)Upsert/Read into/Read into/from Cassandra database
我已经开始使用Cassandra database. 我打算使用Datastax API进入upsert/read/从Cassandra database. 我对此完全陌生Datastax API(它使用新的二进制协议),我也找不到很多文档,其中有一些适当的例子。
现在下面是Singleton class我为连接到 Cassandra 数据库而创建的,Datastax API它使用新的二进制协议-
第一个问题- 让我知道在singleton class使用使用新二进制协议的 Datastax API 连接到 Cassandra 数据库时是否遗漏了上述任何内容。
第二个问题-现在我正在尝试upsert and read data进入/退出 Cassandra 数据库-
这些是我在 DAO 中使用的方法,它们将使用上面的 Singleton 类-
谁能帮我这个?我对这个使用新二进制协议的 Datastax API 完全陌生,所以在这方面有很多问题。
谢谢您的帮助。
python - 并行使用多个(python)客户端从 cassandra 加载所有行
当使用 Cassandra 推荐的 RandomPartitioner(或 Murmur3Partitioner)时,不可能对键进行有意义的范围查询,因为行使用键的 md5 散列分布在集群周围。这些哈希称为“令牌”。
尽管如此,通过为每个计算工作者分配一系列令牌来在许多计算工作者之间拆分一个大表将非常有用。使用 CQL3,似乎可以直接针对 tokens 发出查询,但是以下 python不起作用...编辑:在切换到针对 cassandra 数据库的最新版本(doh!)进行测试后工作,并且还更新每个语法以下注释:
理想情况下,我希望使用 pycassa 来完成这项工作,因为我更喜欢它的 Pythonic 界面。
有一个更好的方法吗?
cassandra - Cassandra 表中的多个列
我想知道当表中有多个非 PK 列时会发生什么。我读过这个例子:http: //johnsanda.blogspot.co.uk/2012/10/why-i-am-ready-to-move-to-cql-for.html
这表明单列:
我们得到:
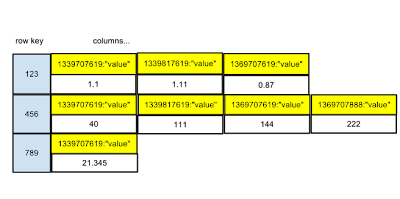
现在我想知道当我们有两列时会发生什么:
我们是否会得到类似的结果:
更确切地说:
等等。我想我要问的是这是否将是一个稀疏表,因为我一次只插入“value1”或“value2”。
在这种情况下,如果我想存储更多列(每种类型一个,例如 double、int、date 等),最好有单独的表而不是将所有内容存储在一个表中?
hadoop - 什么 cassandra 客户端用于 haoop 集成?
我正在尝试使用 cassandra 作为后端存储来构建数据服务层。我是 Cassandra 的新手,不确定要为 cassandra 使用什么客户端 - thrift 还是 cql 3?我们有很多使用 Amazon 弹性 mapreduce (EMR) 的 mapreduce 作业,它们将从 cassandra 中大量读取/写入数据。总数据量将 > 100 TB,Cassandra 中有数十亿行。mapreduce 作业可能会以高 qps (>1000 qps) 进行大量读取或写入。要求如下:
- 客户端代码的简单性。thrift 似乎与 Hadoop 进行了内置集成,以便使用 sstableloader ( http://www.datastax.com/dev/blog/bulk-loading ) 进行批量数据加载。
- 能够在运行时定义新列。根据应用要求,我们可能需要添加更多列。似乎 cql3 不允许在运行时动态定义列。
- 批量读/写的性能。不确定哪个客户端更好。但是,我发现这篇文章声称 thrift 客户端在大数据量方面具有更好的性能:http: //jira.pentaho.com/browse/PDI-7610 ?page=com.atlassian.jira.plugin.system.issuetabpanels:all-标签面板
我找不到任何权威的信息来源来回答这个问题。感谢您是否可以提供帮助,因为我相信这对大多数人来说是一个常见问题,并且会造福整个社区。
提前谢谢了。
-Prateek
nosql - CQL3 与 CQL2 和 Thrift 有何不同?
“紧凑存储将整行存储在磁盘上的单个列中,而不是将每个非主键列存储在与磁盘上的一列对应的列中。使用紧凑存储可防止您添加不属于 PRIMARY KEY 的新列。”
我无法理解上面的说法,这是真的吗?!
参考:http ://www.edwardcapriolo.com/roller/edwardcapriolo/entry/legacy_tables
cassandra - Cassandra中UPDATE和INSERT的区别?
UPDATE对 Cassandra 执行 CQL和INSERT执行 CQL之间有什么区别?
看起来以前没有区别,但现在文档说不INSERT支持计数器,而支持UPDATE。
是否有“首选”方法可以使用?或者在某些情况下应该使用一个而不是另一个?
非常感谢!
cassandra - 使用 Cassandra CQL 收集嵌入对象
我正在尝试使用 CQL 将我的域模型放入 Cassandra。假设我有 USER_FAVOURITES 表。每个收藏夹都有 ID 作为主键。我想按顺序存储多个字段的最多10条记录的列表,field_name,field_location等。
对这样的表格进行建模是个好主意吗
并且对象将从匹配索引的列表项中构造(例如
我总是一起查询收藏夹。我可能想将项目添加到某个位置、开始、结束或中间。
这是一个好习惯吗?看起来不像,但我只是不确定在这种情况下如何对对象进行分组,当我想通过例如 field_location 或更复杂的排序规则来保持它们的顺序时
java - 在 Java 中使用 Hector 和 CQL3
我正在运行 Cassandra 1.2.0 (CQL3),我正在使用 Hector 1.0.5。这是我的表定义:
我不知道如何连接到 cassandra 集群并创建一行。Hector 的文档到处都是,或者在 CQL3 的情况下不完整。我似乎找不到使用现有表连接到现有键空间并使用 CQL3 添加记录的完整示例。
更新
经过更多的挖掘和诅咒,我找到了这个使用 cassandra 驱动程序核心的示例项目。我会玩弄它,但这更多的是我的想法。目前它只是在 beta2 中,但由于这只是为了个人学习,我会试一试,看看它是如何进行的。