问题标签 [cortex-a8]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
arm - ARM Cortex-A8 中的 Valgrind 问题“配置:错误:不支持的主机架构”
我在带有 linux 的 ARM CortexA8 的实际程序中发现了以下问题:
我在网上搜索它,我发现管理这个问题的最有用的程序是 Valgrind。
然后我尝试在交叉编译中编译到我的系统,在配置中使用以下选项。我正在使用 Valgrind 3.8.1
@-virtual-machine:~/valgrind-3.8.1$ CC=arm-cortexa8-linux-gnueabi-gcc CFLAGS="-pipe -Os -mtune=cortex-a8 -march=armv7-a -mabi=aapcs-linux -msoft-float -I/opt/OSELAS.Toolchain-2011.11.3/arm-cortexa8-linux-gnueabi/gcc-4.6.2-glibc-2.14.1-binutils-2.21.1a-kernel-2.6.39-sanitez /sysroot-arm-cortexa8-linux-gnueabi/usr/include" LDFLAGS="-L/opt/OSELAS.Toolchain-2011.11.3/arm-cortexa8-linux-gnueabi/gcc-4.6.2-glibc-2.14.1 -binutils-2.21.1a-kernel-2.6.39-sanitez/sysroot-arm-cortexa8-linux-gnueabi/usr/lib" ./configure -prefix=/opt/valgrid -host=arm-cortexa8-linux-gnueabi -目标=arm-none-linux-gnueabi-build=x86_64-ubuntu-linux
这个配置的输出是:
在此输出的最后一行,我的问题出现了,尽管我查找了一些信息,并且 Cortexa8 它是受支持的平台之一。
出于这个原因,我的问题是我的板是否不受支持,因为我使用的库不兼容,或者可能是其他原因。或者另一方面,我可以毫无畏惧地编译 valgrind 并跳过这个检查。
谢谢你的时间
-问候
布雷西01010...
android - 在 ARM cortex-a8 上读取周期计数寄存器
我正在尝试从模拟器上的 android 本机库中读取 ARM cortex-a8 CPU 上的周期计数寄存器,模拟 Nexus S。
以下是有关我尝试读写的两个寄存器的链接: http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0344b/ Bgbcjifb.html http://infocenter .arm.com/help/index.jsp?topic=/com.arm.doc.ddi0344b/Bgbjjhaj.html
这是我所做的:
使用修改后的金鱼内核启动模拟器,将 CONFIG_MODULES=y 行插入 .config 文件以启用模块加载。
从以下 C 文件创建了一个模块:android_module.c
/li>该库有以下几行尝试读取循环计数器:
/li>我使用以下命令行选项从 eclipse 启动模拟器:
/li>然后我将模块推入模拟器:
/li>
最后一行是:
所以我知道该模块已安装。但是,当我运行使用该库的应用程序时,我在 Logcat 中收到以下消息并且应用程序终止。
有谁知道为什么我仍然收到此错误?当我删除试图访问循环计数寄存器的行时,它就消失了,所以即使我认为我做了一切都允许读取,我仍然不能被允许读取它。
beagleboard - BeagleBone GPIO 输出同步与 PRU (TI AM335x)
我正在使用 AM335x 上的一个 PRU 单元来驱动 BeagleBone 上的 4 个 GPIO 引脚(GPIO1_2、GPIO1_3、GPIO1_6、GPIO1_7),并且我想同步边缘转换(我的完整源代码在底部)。
使用 Beaglebone 将引脚上的输出设置为 HI,将地址 0x4804c194 处的相应位设置为 1,然后将其设置为 LO,将地址 0x4804c190 处的位设置为 1。所以我的 PRU 汇编代码首先设置输出 HI 位,然后设置输出 LO 位:
由于运行每个周期需要多少个周期,LO 周期明显长于 HI(50ns 对 110ns)。不幸的是,我太新了,无法发布图片,这是上一个代码中逻辑分析仪屏幕截图的链接
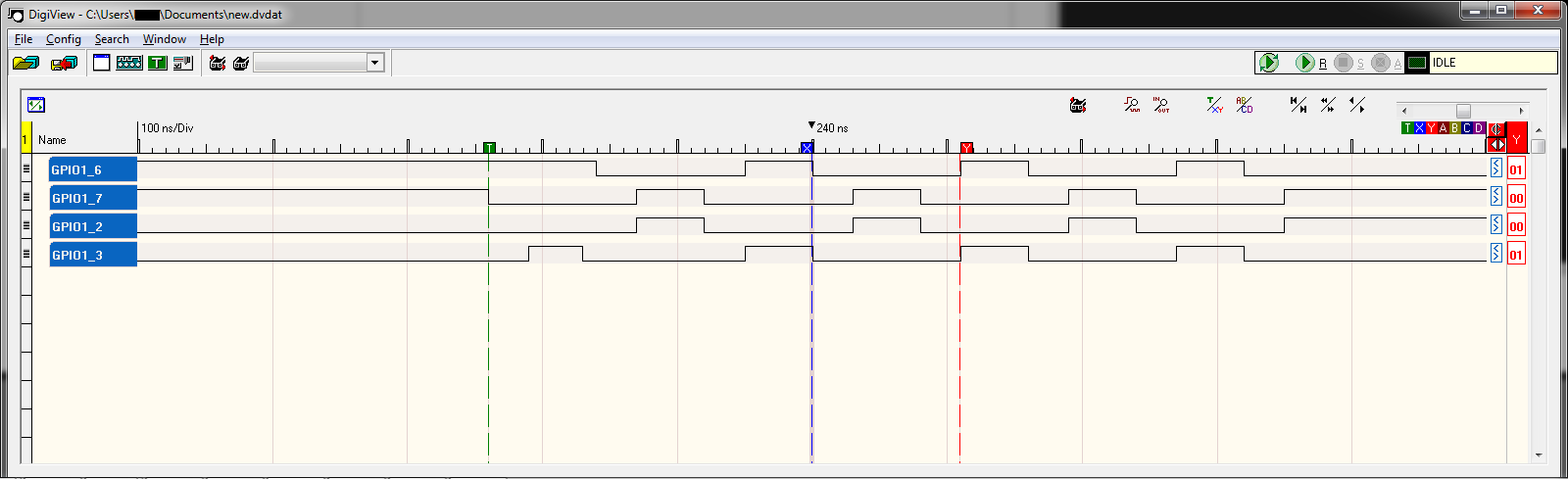{kind=link}
为了均匀超时,我交替设置 HI 和 LO 位,使周期相等,为 80ns,但 HI 和 LO 转换相互偏移 80ns:
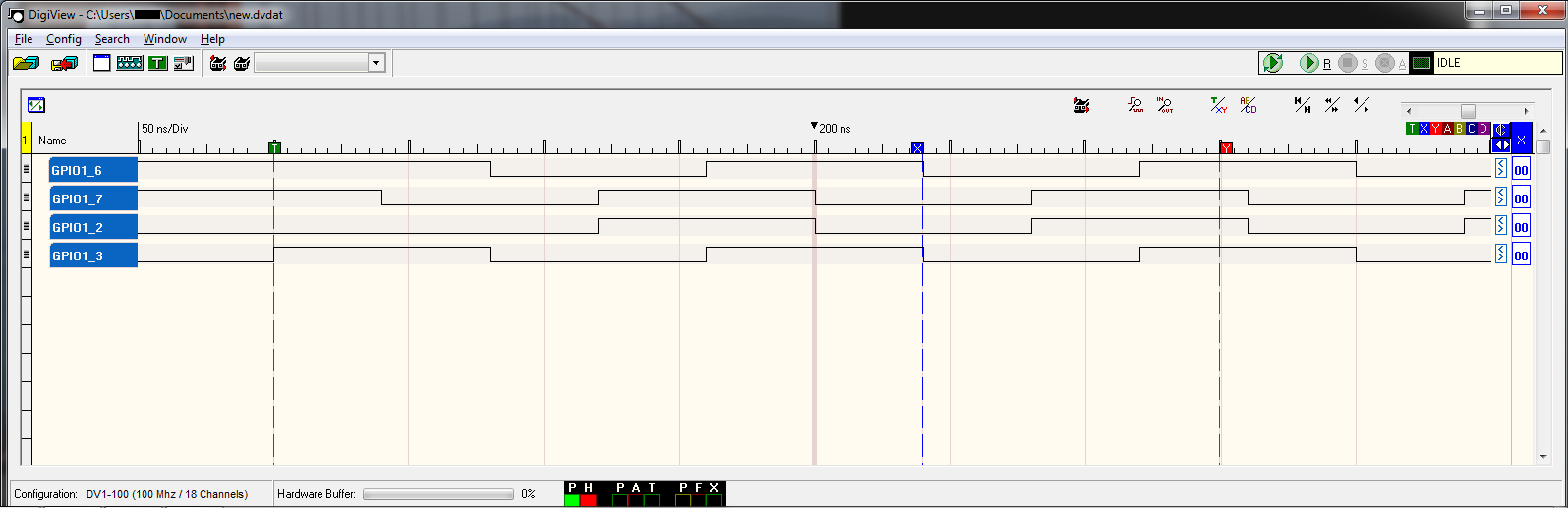{kind=link}
所以我的问题是如何让边缘转换同时发生?即,如果您比较 GPIO1_6 和 GPIO_7,屏幕截图的中心是 200ns,此时 GPIO1_7 转换为 LO,然后 50ns 之前,GPIO1_6 转换为 HI,我希望它们同时转换。我不介意放慢速度来实现这一点。
这是我的源代码:
文件:main.p
文件 main.c:
文件 main.hp:
arm - 来自不同制造商的 Thumb-2 ARM-Core Micros 是否具有相同的代码大小?
比较来自两个不同制造商的两个 Thumb-2 micros。一个是 Cortex M3,一个是 A5。他们是否保证将特定的代码段编译为相同的代码大小?
memory - [ARM CortexA]强序和设备内存类型的区别
我真的是 Cortex A 的新手,我知道 ARM 采用弱序内存模型,并且存在三种互斥内存类型:
- 强序
- 设备
- 普通的
我大致了解 Normal 的含义以及 Strongly-ordered 和 Device 的含义。然而,强排序和设备之间的差异让我感到困惑。
根据 Cortex-A 系列程序员指南,唯一的区别是:
对强序内存的写入只有在到达写入访问的外围设备或内存组件时才能完成。
允许在设备内存到达写入访问的外围设备或内存组件之前完成对设备内存的写入。
我不太确定这的真正含义是什么。我猜想,使用 Strongly-ordered 或 Device 键入的内存的访问顺序应该与程序员的代码一致(没有乱序访问)。但是,如果键入的是 Device,CPU 可能会在访问内存时执行下一条指令,如果键入的是 Strongly-ordered,它只会等到访问完成。
如果我错了,请纠正我,请告诉我这样做的含义是什么。
提前致谢。
arm - ARM DS-5 模拟器上的循环计数分析
我正在尝试在 DS-5 Simulator 上使用分析器。我现在不想附加任何板,因此我相信我不能使用 Streamline Analyzer。
我的问题是如何在 Eclipse 环境中的 Windows 上查看 DS-5 Simulator (Cortex A8) 上的代码覆盖率和循环计数使用情况。
谢谢
linux-kernel - ARM 中主要 GIC 与次要 GIC 的区别
根据 gic 设备树绑定的内核文档
“主 GIC 直接连接到 CPU,通常具有 PPI 和 SGI。”
“二级 GIC 级联到上行中断控制器,没有 PPI 或 SGI。”
我在 GIC-400 中没有找到主要/次要 GIC 一词。任何人都可以描述差异或指向说明它的文件。
assembly - MSR CPSR_C, #0x13 在使用 ARM 程序集时不起作用?
我正在为 ARM Cortex A9 处理器编写裸机代码(无操作系统)。
我需要读取一个只能在主管模式下访问的寄存器(多处理器关联寄存器,MPIDR)。
当我处于用户模式并尝试使用调试器逐步执行以下指令(进入主管模式)时,没有任何反应。
如果我尝试读取 MPIDR 寄存器,我的程序会进入未定义模式
请问你知道我错过了什么吗?
当我使用调试器窗口并将 CPSR 寄存器的前五个位强制为 b10011 时,它可以工作,我去主管。
c++ - ARM Cortex-A8:使用简单浮点乘法时交叉编译器的不同汇编输出
我正在使用带有 linux ubuntu 的 i.MX53 板进行试验。我正在我的主机系统上使用交叉编译器(arm-linux-gnueabihf)在 ssh 上工作。
对于在处理器 (ARM Cortex-A8) 上进行浮点运算的基准测试,我创建了以下两个不同的程序,它们都包含一个简单的循环。在第一个程序中,循环包含一个乘法,在第二个程序中,循环包含一个额外的加法。
我使用以下编译器调用编译了这两个程序:
现在我的问题是:为什么编译器会为循环部分输出如此不同的汇编代码? (见汇编代码)
我认识到,在第一个程序中,编译器为乘法生成 NEON 指令,而在第二个程序中,只有较慢的 VFP 指令。
第一个程序(loopMul.cpp):
第二个程序(loopMulAdd):
第一个程序的汇编输出(loopMul.s):
第二个程序的汇编输出(loopMulAdd.s):
assembly - 使用 NEON 优化 Cortex-A8 颜色转换
我目前正在做一个颜色转换程序,以便从 YUY2 转换为 NV12。我有一个非常快的功能,但没有我预期的那么快,主要是由于缓存未命中。
当我问 oprofile 什么需要时间时,它会说:
- 前两列是循环计数(绝对和相对)
- 接下来的两个是 L1 缓存未命中(绝对和相对)
- 最后一个是 L2 缓存未命中(绝对和相对)
任何帮助将不胜感激,因为目前这是一项非常困难的任务,要找出想法并避免缓存未命中......
谢谢 !