问题标签 [cassandra-stress]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
cassandra - 无法运行 Cassandra-Stress
运行 cassandra-stress 命令时出现以下错误
./cassandra-stress 用户配置文件=/home/cass/apache-cassandra-3.11.2/tools/stress_test.yaml 持续时间=1m "ops(insert=1,latest_event=1,events=1)"
我收到以下错误/警告:
WARN 18:28:41,488 您在联系点中列出了 localhost/0:0:0:0:0:0:0:1:9042,但在启动时在控制主机的 system.peers 中没有找到它
连接到集群:测试集群,每个连接的最大挂起请求数 128,每个主机的最大连接数 8
数据中心:datacenter1;主机:localhost/127.0.0.1;机架:机架1
生成具有 [1..50] 分区和 [0..50] 行的批次(分区中的 [1..50] 总行)
睡2秒...
用 0 次迭代预热插入...用 0 次迭代预热 latest_event...
java.lang.IllegalArgumentException:在 org.apache.cassandra.stress.settings.SettingsCommandUser$1.get(SettingsCommandUser.java :93) 在 org.apache.cassandra.stress.settings.SettingsCommandUser$1.get(SettingsCommandUser.java:82) 在 org.apache.cassandra.stress.operations.SampledOpDistributionFactory$1.get(SampledOpDistributionFactory.java:83) 在 org. apache.cassandra.stress.StressAction$Consumer.(StressAction.java:409) at org.apache.cassandra.stress.StressAction.run(StressAction.java:233) at org.apache.cassandra.stress.StressAction.warmup(StressAction .java:121) 在 org.apache.cassandra.stress.StressAction.run(StressAction.java:70) 在 org.apache。cassandra.stress.Stress.run(Stress.java:143) 在 org.apache.cassandra.stress.Stress.main(Stress.java:62)
这是我的 stress_test.yaml 文件的样子:
键空间:hss_cass_2
表:设备状态
插入:分区:统一(1..50)
批处理类型:已记录
选择:统一(1..10)/10
查询:simple1: cql: select * from equipment_status where equipment_id = ? 和 eq_status = ? 限制 100 个字段:samerow
range1: cql: select * from equipment_status where equipment_id = ? 和 eq_status = ? 和设备ID类型=?限制 100 个字段:多行
此外,数据中心的名称是 dc1,但从错误日志中我发现 Datacenter: datacenter1 给出了。这可能是错误的事情之一,但我不知道。
阿帕奇卡桑德拉 3.11.2。RHEL 6.5
cassandra - Cassandra-stress 不会为每一行生成随机值
使用下面的 DDL 和配置文件 yaml,我使用cassandra-stress. 我得到的列结果amount与status预期不符。随机值似乎是每个分区绘制一次,而不是每一行。
例如,如果cassandra-stress生成具有相同business_date(即一个分区)的5 行,amount并且status值重复 5 次,则“下一个”随机值在business_date更改时出现。amount我怎样才能做到这一点,以便我status每行都获得新的平局?
示例输出,请注意仅在第一列更改后最后两列更改值。
表结构:
简介 YAML:
java - Elassandra - 错误:无法找到或加载主类 org.apache.cassandra.stress.Stress
我正在尝试cassandra-stress在 elassandra 集群上运行。
购买我总是收到此错误:
$密码
/usr/share/cassandra/tools/bin
$./cassandra-压力
Error: Could not find or load main class org.apache.cassandra.stress.Stress
E 编辑了 cassandra-stress 文件,我检查了该文件是否包含以下内容:
但不存在文件Stress.java和Stress.class系统。
但是不知道怎么用
elassandra - 错误:无法找到或加载主类 org.apache.cassandra.stress.Stress
如何cassandra-stress在Elassandra集群上执行?
cassandra-stress 不在 elassandra 文件系统上
cassandra - Cassandra-stress : 如何在 cassandra 集群外部安装和设置它
我即将使用简单的 cassnadra 集群(3 个节点,xxx104-106)。我使用的是 CentOS7,所以我使用了 datastax 存储库 Cassandra 3.0。我在论坛上看到,最好在集群外部安装cassandra-stress,否则它会消耗节点的CPU。
你能帮我吗,如何安装它?
我尝试单独复制 cassandra-stress.sh,但它依赖于一些 cassandra 文件(可能在安装过程中创建)。
所以我决定将整个 Cassandra 安装在不同的服务器上,在同一个网络空间中。现在,我正在努力正确设置,如何针对 cassandra 集群运行 cassandra-stress 工具。
在 cassandra.yaml 中,我设置了 Cassandra 名称,listen_adress 为 public_ip,rpc_address 为环回地址,我将种子设置为 cassandra 集群节点(xxx104-106)......但一般来说设置它没有意义,因为我不想'不要在 Cassandra 集群中创建另一个节点。
请你帮助我好吗?
编辑:也许使用这样的东西可能是正确的方法?
cassandra-stress 用户配置文件=/usr/cassandra/stress-file.yaml ops(insert=1,books=1) n=10000 -node xxx104,xxx105,xxx106 -port native= ? Telnet [cassandra_node_ip_ddress] 7000 工作正常
cassandra - 可以针对现有表数据运行 cassandra-stress 工具吗?
我有一个我一直在测试的现有 Cassandra 测试安装。我要针对当前运行该cassandra-stress工具的表具有真实(非实时)数据,大约 100k 行。所以我想知道该工具是否可以用于该数据,还是只能是该工具插入空表以确定写入速度等的数据?
database - 如何校准 cassandra-stress 图选项?
我设法在集群外运行压力工具。我已经准备好在我的 cassa 集群上的银行键空间中拥有基本表 bank_transactions。
bank.bank_transactions ( customerid text, year int, month int, id timeuuid, amount int, card text, status text, PRIMARY KEY ((customerid, year, month), id) ); 这是我的个人资料 yaml 文件:
我承受压力
我期待在 cassandra.apache 网站上有类似图表的东西
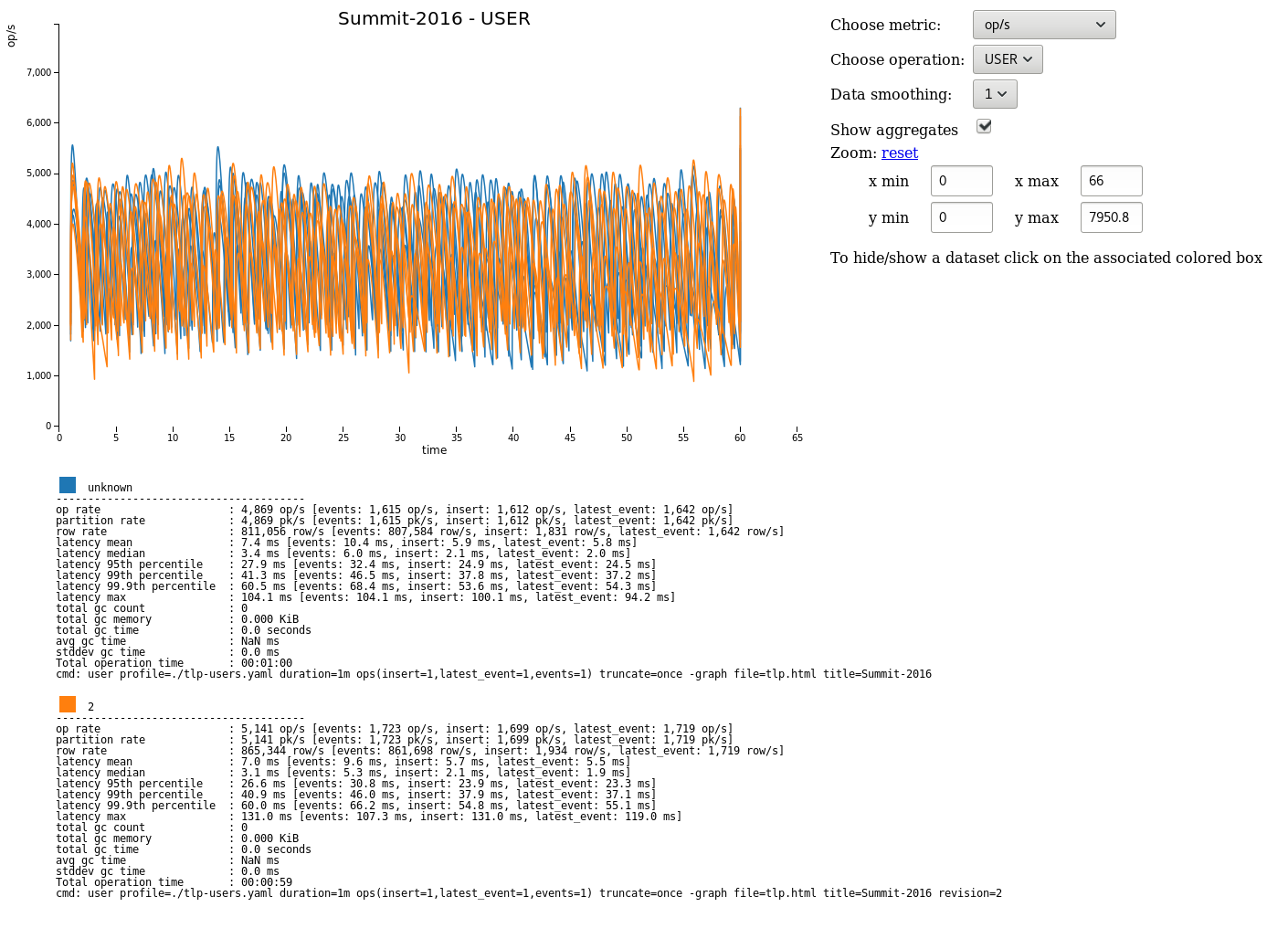
但结果真的很奇怪:

你能帮我吗,怎么了?
PS不要介意发行等,它只是游乐场......
docker - Cassandra-stress 文件未找到异常
我正在尝试使用定义的自己的 .yaml 文件运行 cassandra-strees,但我仍然遇到错误:
这对我来说很麻烦。让我解释一下为什么。
首先是我的 stress.yaml 文件:
我运行的命令:
'cassandra' 是我当前正在运行的容器。
文件的绝对路径stress.yaml是/home/kenik/Documents/stress.yaml我使用命令检查过的:readlink -f stress.yaml。我在放置stress.yaml 的目录中。如您所见,路径似乎很好,但 cassandra-stress 无论如何都找不到它。
您知道运行此 cassandra 压力测试的任何方法吗?
//更新当启动容器时我使用命令:
或者
并尝试执行测试:
结果是一样的:找不到文件异常。我已经更新了帖子,因为我可能会做出某种类型或没有正确理解答案。
cassandra - Cassandra TLP-Stress Tarball 安装
我刚刚为 cassandra 下载了 tarball tlp-stress 并提取并找到了一些罐子。运行压力测试的下一步是什么?
谢谢。
cassandra - 使用 cassandra-stress 导入时,ScyllaDB 模式会导致问题
我目前在我的环境中使用 ScyllaDB,并且由于技术原因,正在研究迁移到 Cassandra。我正在尝试使用可能与 ScyllaDB 中当前使用的模式相同的模式使用数据使 cassandra-stress 加载 Cassandra 集群。可悲的是,有一些问题。
环境:
- 在 Ubuntu 18.04 上运行的 ScyllaDB 3.0.7 (= Cassandra 3.0.8)
- 在 Ubuntu 18.04 上运行的 Cassandra 3.11.4
cassandra-tools在 Ubuntu 18.04 上运行的 cassandra-stress 3.0.18(pkg 的一部分)
过程如下:
- 从 ScyllaDB (
desc keyspace_name)转储模式 - 准备 cassandra-stress yaml 文件 - 一个键空间,总共五个表
- 运行 cassandra-stress (
cassandra-stress user profile=schema.yml cl=QUORUM duration=30s 'ops(insert=1)' -node 172.19.11.9 -rate threads=1)
为了确保没有与键空间相关的问题,每次运行 cassandra-stress 都是在一个新的键空间上完成的(我正在增加名称)。
现在,当模式是 1:1 作为从 Scylla 转储的模式时,定义两个表(并且只有这两个表)会导致压力工具失败:com.datastax.driver.core.exceptions.SyntaxError: line 1:35 no viable alternative at input 'WHERE' (UPDATE "activities_bp_action" SET [WHERE]...).
表定义如下:
如果将包含PRIMARY KEY和的两行CLUSTERING ORDER替换为以下内容,则 cassandra-stress 运行良好,没有错误,并开始用数据填充集群。但是,现在的定义与 ScyllaDB 的定义有所不同:
现在,在使用修改后的定义运行 cassandra-stress 之后,我可以回滚到未修改的定义(曾经失败的那个)。如果在已经存在的键空间上运行,yaml 现在可以正常工作并用数据填充集群。这表明创建表时会出现问题?
在调试模式下运行 cassandra-stress 和 Cassandra 时,我无法找到 cassandra-stress 在其堆栈跟踪中显示的完整查询,并且该查询让我有点困惑。
任何想法为什么会出现问题?谢谢!
编辑:
schema.yml附件:https : //gist.github.com/schybbkoh/76cdbf19a2bb933419063526ff5ac44f
编辑:
事实证明,“运行良好,没有错误,并开始用数据填充集群”模式创建并仅填充模式中定义的最后一个表。这里有问题。